
知识简介:
“计算机”与“数据”之间水乳交融的关系。
计算机名字里就有【计算】两字,如果计算机离开了数据,就如巧妇难为无米之炊。所以说,数据对于计算机很重要。
计算机有3种方式利用数据:


第一种:直接使用数据,比如print()语句,可以直接把我们提供的数据打印出来,通常所见即所得。

第二种:计算和加工(拼接、转换数据类型等)数据,让我们看个例子:

第三种:用数据做判断
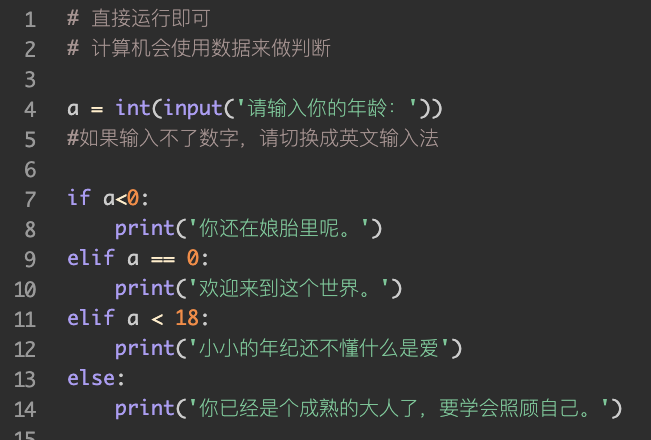
计算机在这里是【利用数据用做逻辑判断】
掌握主要的数据类型是重中之重
这一关,我们就会接触两种新的数据类型——列表和字典,你会发现,它们比我们学过的“整数、浮点数、字符串”更加高级,更有“包容性”。
为什么这么说呢?前面学的几种类型,每次赋值只能保存一条数据。如果我们需要使用很多数据的时候,就会很不方便。
而列表和字典的作用,就是可以帮我们存储大量数据,让计算机去读取和操作。
数据类型:列表:
思考:如果只能用已学的知识来解决这个问题,我们需要将每个学生的名字都赋值到一个变量名,然后再分别打印。代码是这样的:
但我们知道,在编程世界里,最忌讳的就是“重复性劳动”。这一百行代码打下来,即使是复制黏贴修改的,分分钟也要抓狂。
实际上呢,只要学会了列表和循环(剧透:循环下一关会讲,可先忽略),3行代码就能搞定。
#直接运行代码即可
students = ['党志文', '浦欣然', '罗鸿朗', '姜信然', '居俊德', '宿鸿福', '张成和', '林景辉', '戴英华', '马鸿宝', '郑翰音', '厉和煦', '钟英纵', '卢信然', '任正真', '翟彭勃', '蒋华清', '双英朗', '金文柏', '饶永思', '堵宏盛', '濮嘉澍', '戈睿慈', '邰子默', '于斯年', '扈元驹', '厍良工', '甘锐泽', '姚兴怀', '殳英杰', '吴鸿福', '王永年', '宫锐泽', '黎兴发', '朱乐贤', '关乐童', '养永寿', '养承嗣', '贾康成', '韩修齐', '彭凯凯', '白天干', '瞿学义', '那同济', '衡星文', '公兴怀', '宫嘉熙', '牧乐邦', '温彭祖', '桂永怡']
for i in students:
print(i+'在不在?')
赋值号右边不再像字符串那样只能放一个名字,而是放了50个。
什么是列表

一个列表需要用中括号[ ]把里面的各种数据框起来,里面的每一个数据叫作“元素”。每个元素之间都要用英文逗号隔开。
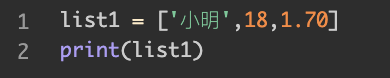
这就是列表的标准格式,现在请你创建一个列表名为list1的列表,列表里有三个元素:'小明',18,1.70,并将其打印出来:
代码验证了一个知识点:列表很包容,各种类型的数据(整数/浮点数/字符串)无所不能包。
不过,很多时候,我们只需要用到列表中的某一个元素,好比老师上课点名时,不会说“所有的同学都站起来回答一下这个问题”。所以,问题来了:列表中具体的某个元素,要如何取出来?
查元素:
从列表提取单个元素
这就涉及到一个新的知识点:偏移量。列表中的各个元素,好比教室里的某排学生那样,是有序地排列的,也就是说,每个元素都有自己的位置编号(即偏移量)。

从上图可得:1.偏移量是从0开始的,而非我们习惯的从1开始;2.列表名后加带偏移量的中括号,就能取到相应位置的元素。
所以,我们可以通过偏移量来对列表进行索引(可理解为搜索定位),读取我们所需的元素。
假如你现在要喊小明来回答问题,用代码怎么写

从列表提取多个元素
总结下规律:

上面这种用冒号来截取列表元素的操作叫作切片,顾名思义,就是将列表的某个片段拿出来处理。这种切片的方式可以让我们从列表中取出多个元素。
偏移量取到的是列表中的元素,而切片则是截取了列表的某部分
总结口诀:
左右空,取到头,左取右不取
给列表增加/删除元素
方式一:
定义时添加和覆盖式删除
方式二:
append(元素)
这里先感受下:
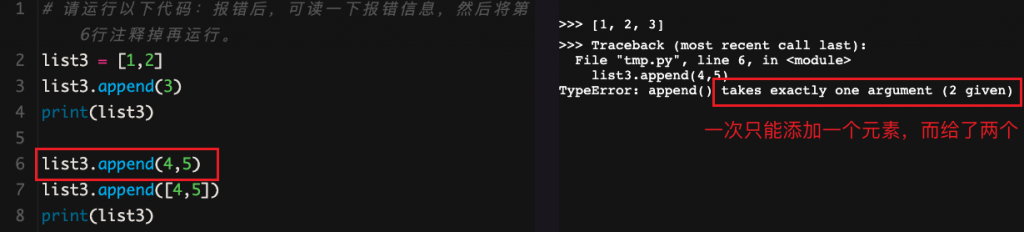
append后的括号里只能接受一个参数,但却给了两个,也就是4和5。所以,用append()给列表增加元素,每次只能增加一个元素到列表的末尾。
再感受下:

从第7行代码 list3.append([4,5]) 能成功运行可以看出:append函数并不生成一个新列表,而是让列表末尾新增一个元素。而且,列表长度可变,理论容量无限,所以支持任意的嵌套
小练习:
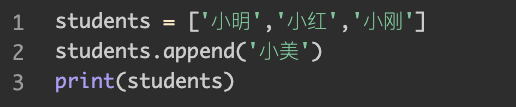
过了一周,你正上着课呢,教导主任突然领了一个新学生“小美”,说是转校生,要插到你们班。这时,我们就需要用到append()函数给列表增加元素,append的意思是附加,增补。
del语句:
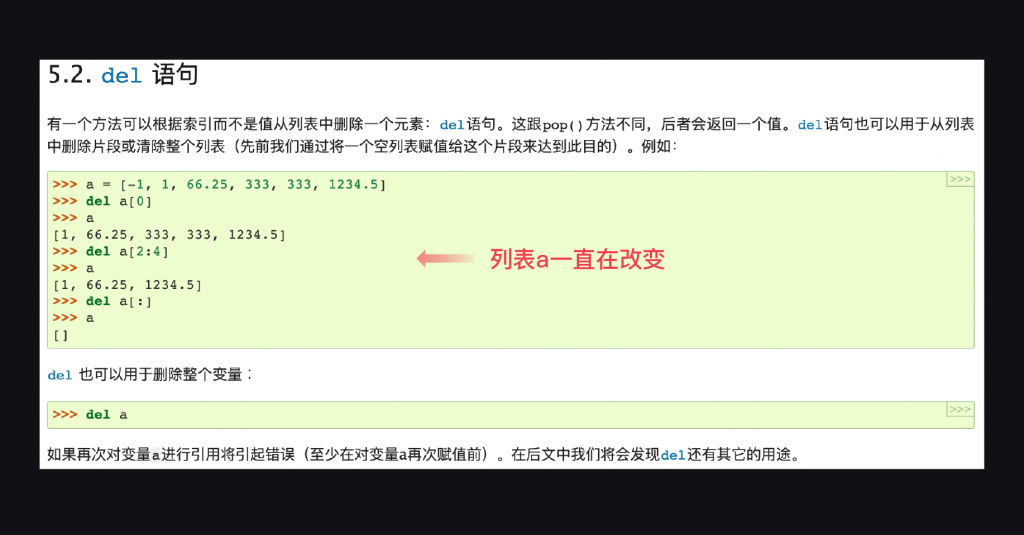
事实上del语句非常方便,既能删除一个元素,也能一次删除多个元素(原理和切片类似,左留右不留)。
总结:

数据类型:字典
思考:
众所周知,一个老师的日常就是出卷、改卷。这次期中考呢,小明、小红、小刚分别考了95、90和90分。
假如我们还用列表来装数据的话,我们需要新创建一个列表来专门放分数,而且要保证和姓名的顺序是【一致】的,很麻烦。
所以类似这种名字和数值(如分数、身高、体重等)两种数据存在一一对应的情况,用第二种数据类型——“字典”(dictionary)来存储会更方便。
数据结构:
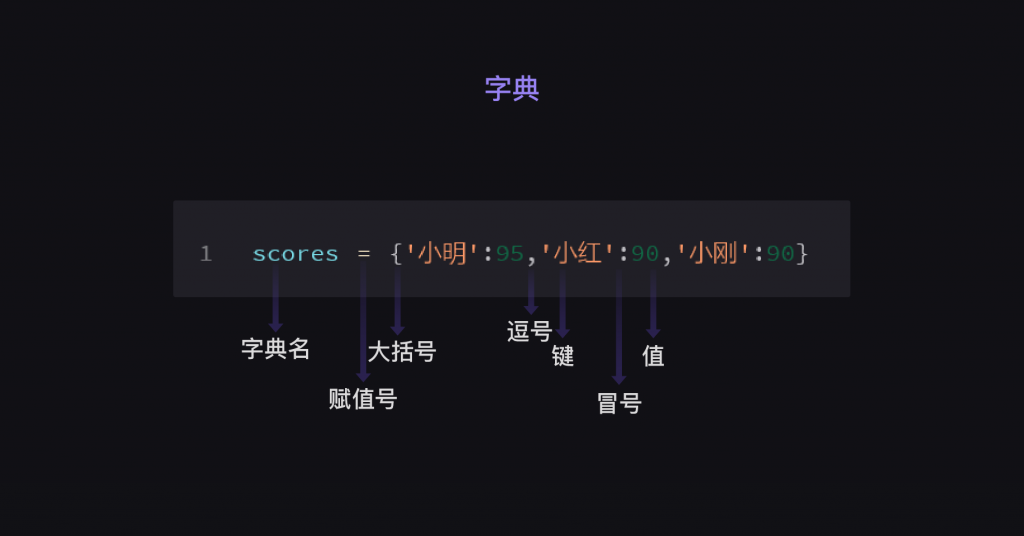
仔细看下,字典和列表有3个地方是一样的:1.有名称;2.要用=赋值;3.用逗号作为元素间的分隔符
而不一样的有两处:
1.列表外层用的是中括号[ ],字典的外层是大括号{ };
2.列表中的元素是自成一体的,而字典的元素是由一个个键值对构成的,用英文冒号连接。如'小明':95,其中我们把'小明'叫键(key),95叫值(value)。
这样唯一的键和对应的值形成的组合,我们就叫做【键值对】,上述字典就有3个【键值对】:'小明':95、'小红':90、'小刚':90
计算长度:
如果不想口算,我们可以用len()函数来得出一个列表或者字典的长度(元素个数),括号里放列表或字典名称。

这里需要强调的是,字典中的键具备唯一性,而值可重复。也就是说字典里不能同时包含两个'小明'的键,但却可以有两个同为90的值。
查:
我们尝试将小明的成绩从字典里打印出来。这就涉及到字典的索引,和列表通过偏移量来索引不同,字典靠的是键

这便是从字典中提取对应的值的用法。和列表相似的是要用[ ],不过因为字典没有偏移量,所以在中括号中应该写键的名称,即字典名[字典的键]。
给字典增加/删除元素
样例:
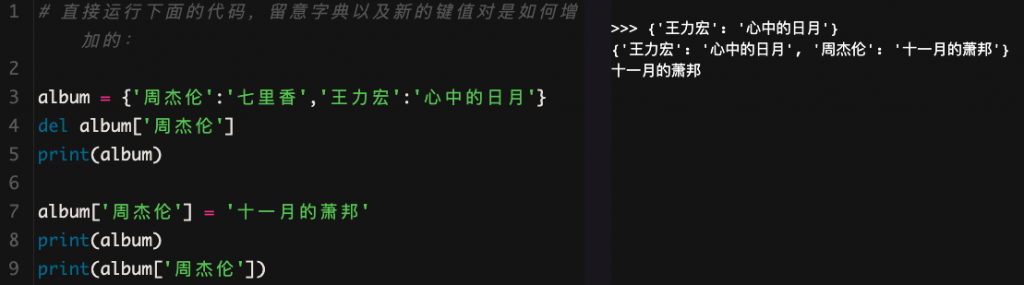
我们可以发现:删除字典里键值对的代码是del语句del 字典名[键],而新增键值对要用到赋值语句字典名[键] = 值。
练习:
把小刚的成绩改成92分

总结一下字典的基础知识:

列表和字典的异同
列表和字典的不同点
一个很重要的不同点是列表中的元素是有自己明确的“位置”的,所以即使看似相同的元素,只要在列表所处的位置不同,它们就是两个不同的列表。我们来看看代码:
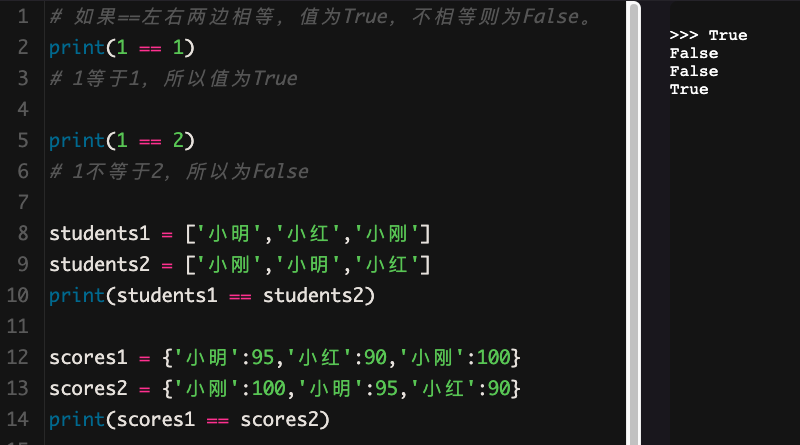
而字典相比起来就显得随和很多,调动顺序也不影响。因为列表中的数据是有序排列的,而字典中的数据是随机排列的。
这也是为什么两者数据读取方法会不同的原因:列表有序,要用偏移量定位;字典无序,便通过唯一的键来取值。
共同点:
第一个共同点:在列表和字典中,如果要修改元素,都可用赋值语句来完成。
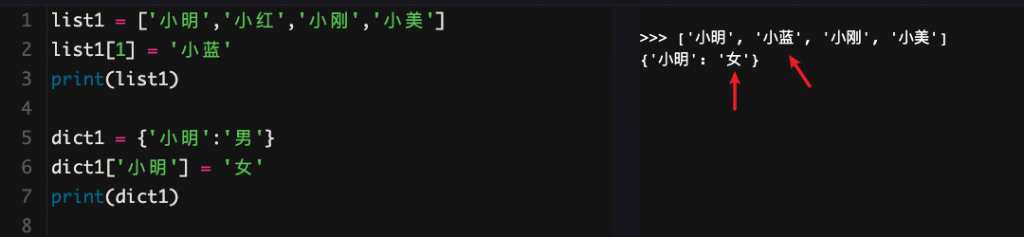
第二个共同点即支持任意嵌套
除之前学过的数据类型外,列表可嵌套其他列表和字典,字典也可嵌套其他字典和列表。
列表嵌套列表
先来看看第一种情况:列表嵌套列表。你在班级里成立了以四人为单位的学习小组。这时,列表的形式可以写成:
students = [['小明','小红','小刚','小美'],['小强','小兰','小伟','小芳']]
students这个列表是由两个子列表组成的,现在有个问题是:我们要怎么把小芳取出来呢?
当我们在提取这种多级嵌套的列表/字典时,要一层一层地取出来,就像剥洋葱一样
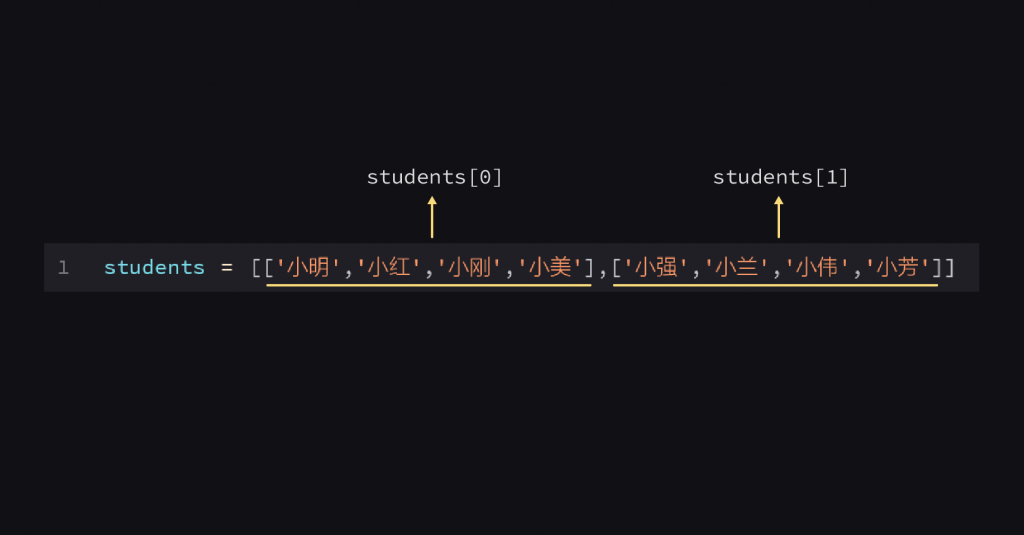
现在,我们确定了小芳是在students[1]的列表里,继续往下看。
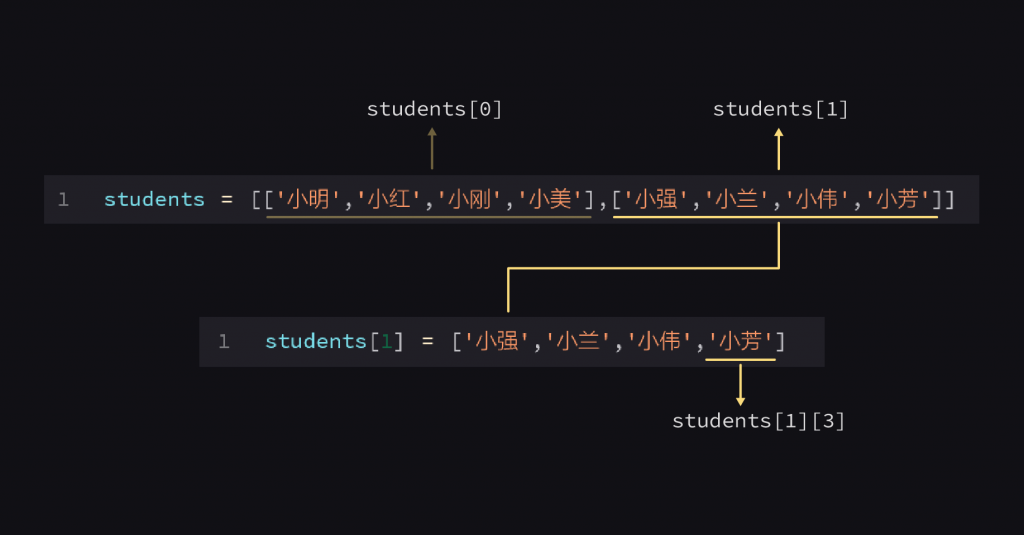
小芳是students[1]列表里的第三个元素,所以要取出小芳,代码可以这么写:

字典嵌套字典
和列表嵌套列表也是类似的,需要一层一层取出来,比如说要取出小芳的成绩,代码是这样写:

取出小刚的成绩
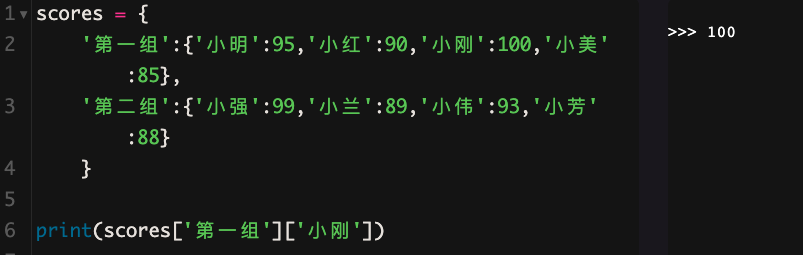
列表和字典相互嵌套

输出结果分别为:小美、99
字符串类型转化为列表类型
通过分割将字符串转化为列表:
dict1=str(['cat','dog','duck'])
dict2=dict1.replace("[",'').replace("]",'').replace("\'",'')
print(dict2)
dict3=dict2.split()
print(dict3)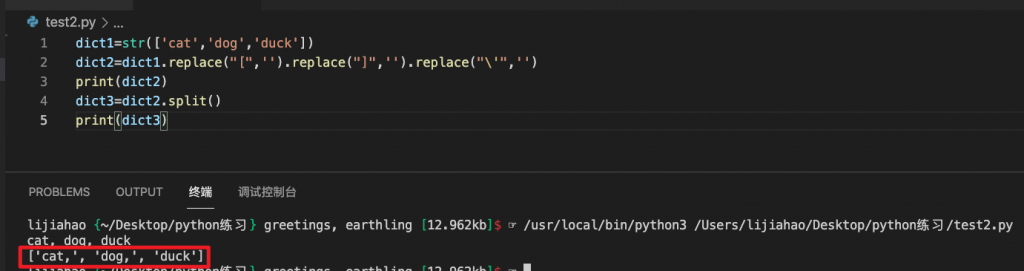
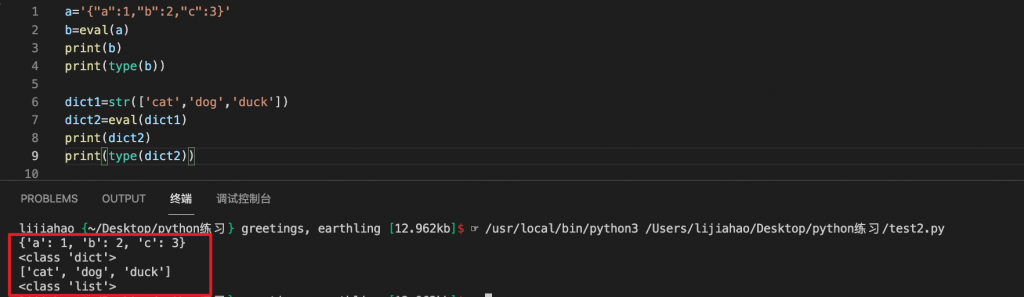
使用eval()函数直接逆向转化
课后练习:
townee = [
{'海底王国':['小美人鱼''海之王''小美人鱼的祖母''五位姐姐'],'上层世界':['王子','邻国公主']},
'丑小鸭','坚定的锡兵','睡美人','青蛙王子',
[{'主角':'小红帽','配角1':'外婆','配角2':'猎人'},{'反面角色':'狼'}]
]在层层嵌套的各种数据类型中,准确地提取出你需要的数据。
列表中有个字符串是“狼”,将其打印出来吧。

发布者:LJH,转发请注明出处:https://www.ljh.cool/7578.html