
Prometheus 数学理理论基础学习
PromQL常见语法
瞬时向量和区间向量
瞬时向量:包含该时间序列中最新的一个样本值
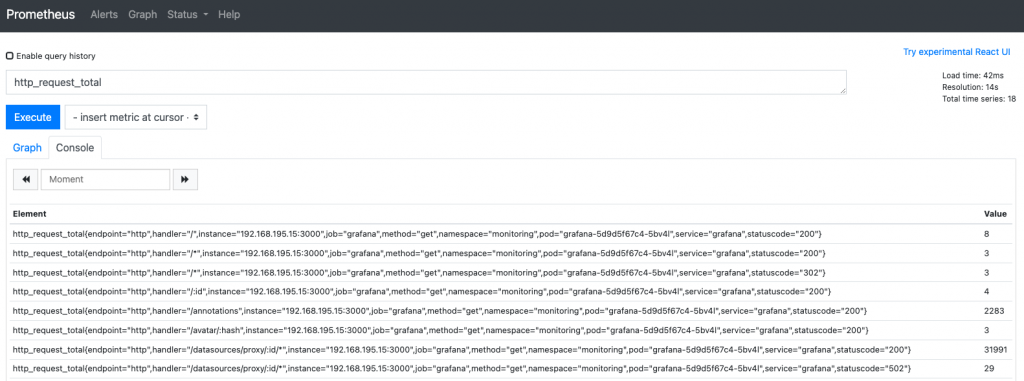

区间向量:一段时间范围内的数据

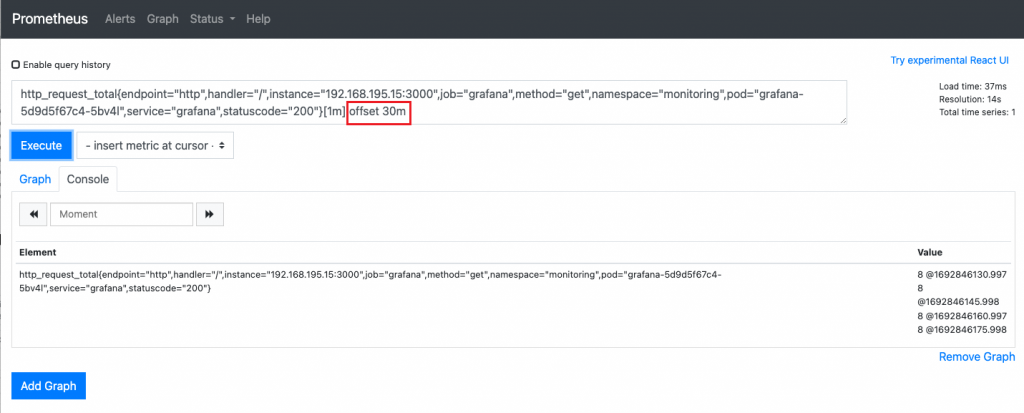
Offset:查看多少分钟之前的数据 offset 30m
Labelsets:
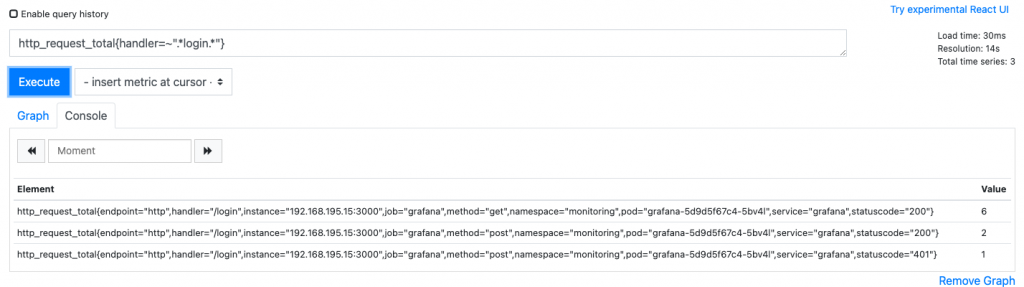
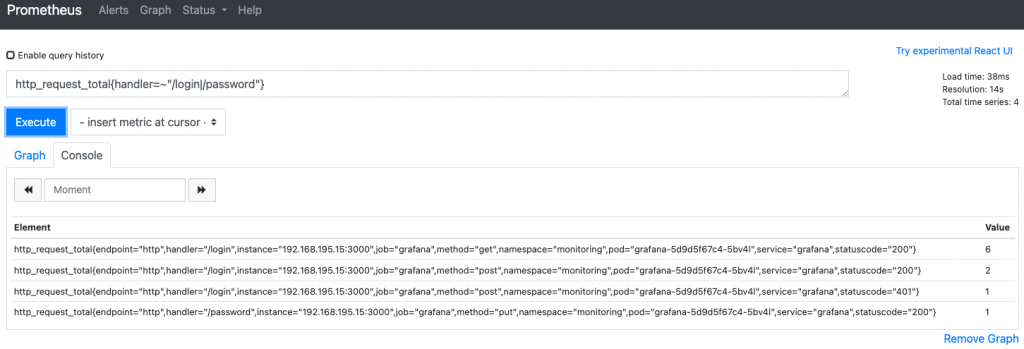
过滤出具有handler="/login"的label的数据。
正则匹配:http_request_total{handler=~".*login.*"}
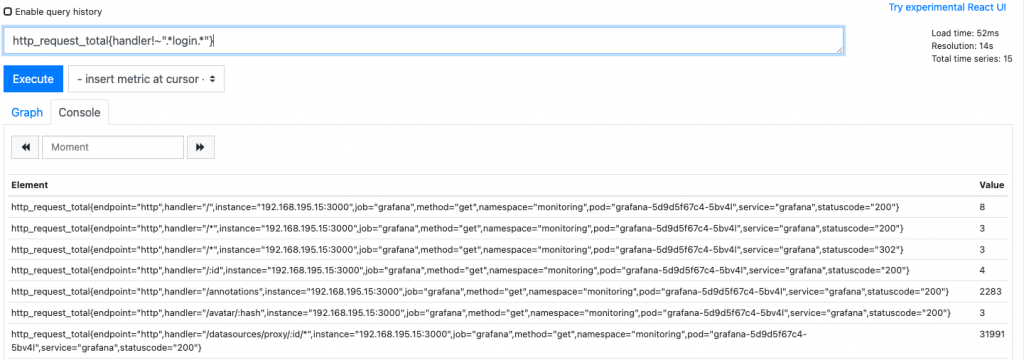
剔除某个label:http_request_total{handler!~".*login.*"}
匹配两个值:http_request_total{handler=~"/login|/password"}
数学运算:+ - * / % ^
查看主机内存总大小(Mi)
node_memory_MemTotal_bytes/1024/1024<4000

集合运算
and or
node_memory_MemTotal_bytes / 1024 /1024 <= 2772 or node_memory_MemTotal_bytes / 1024 /1024 == 3758.59765625
unless:排除
node_memory_MemTotal_bytes / 1024 /1024 >= 2772 unless node_memory_MemTotal_bytes / 1024 /1024 == 3758.59765625
优先级
- ^
- * / %
- + -
- ==, !=, <=, < >= >
- And unless
- Or
聚合操作:
sum:求所有node内存,使用sum后是将所有的监控的服务器的值进行取和,所以当我们只看某一台时需要进行拆分拆分常用方法by increase()
sum(node_memory_MemTotal_bytes) / 1024^2
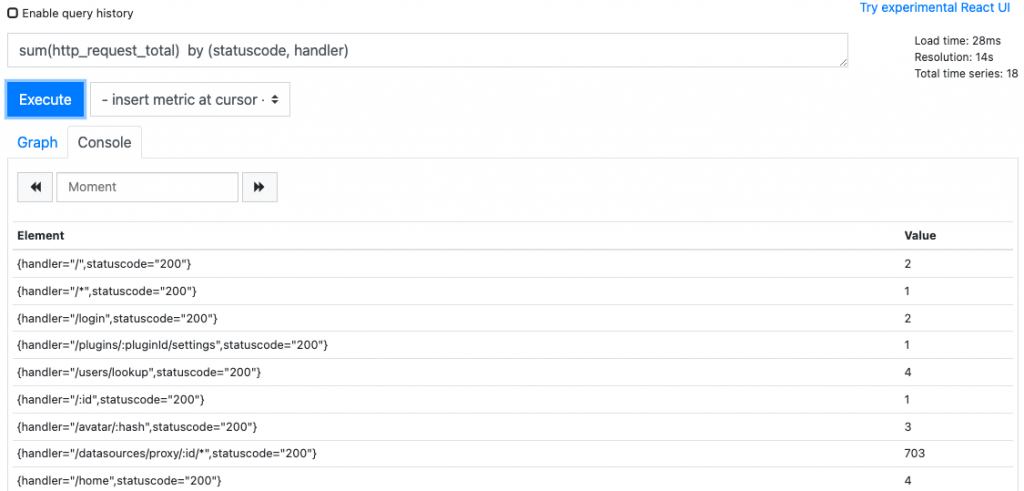
根据某个字段进行统计
sum(http_request_total) by (statuscode, handler)
最大值max() 最小值 min() 平均值 avg()
标准差:stddev 方差:stdvar
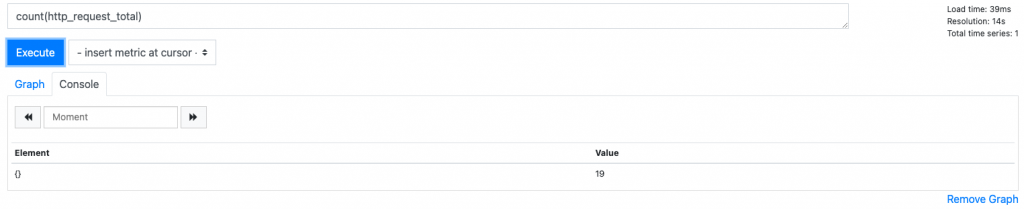
计数 count()
count(http_request_total)
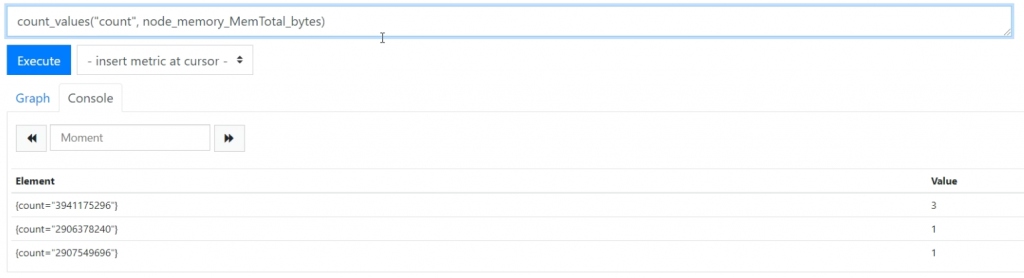
count_values("count", node_memory_MemTotal_bytes) 对value进行统计计数
topk(5, sum(http_request_total) by (statuscode, handler)) 取前N条时序
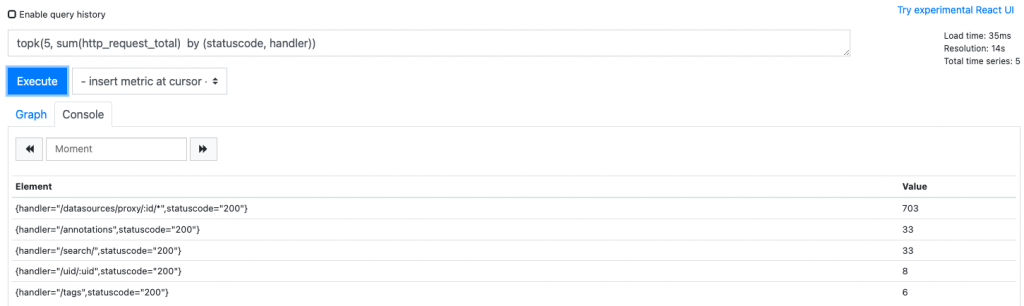
bottomk(3, sum(http_request_total) by (statuscode, handler)) 取后N条时序
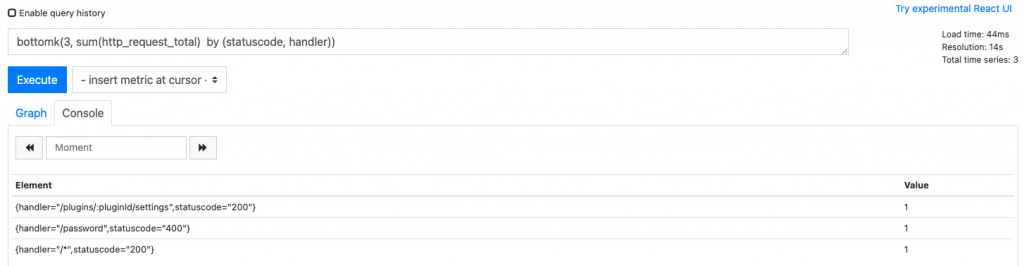
取当前数据的中位数
求请求延时中位数quantile(0.5, http_request_total)
内置函数:
一个指标的增长率increase()
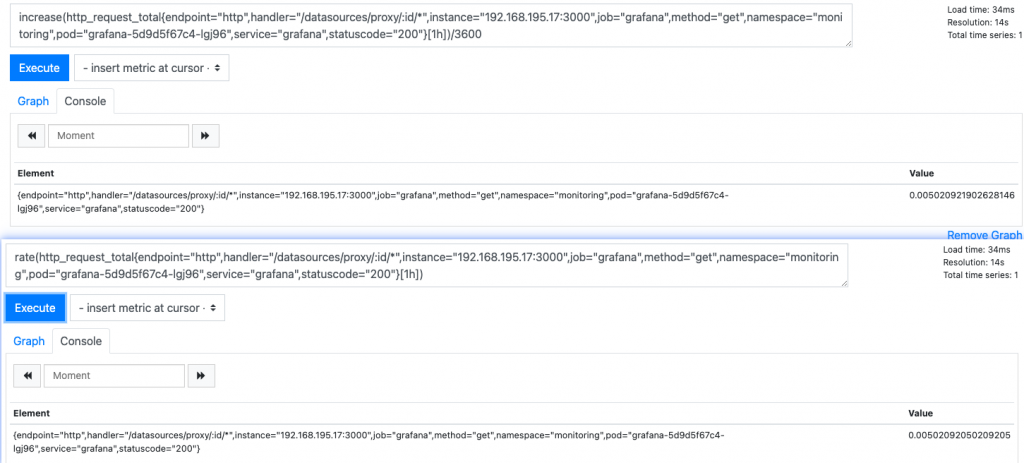
计算最近一小时平均每秒平均访问增长率
increase(http_request_total{endpoint="http",handler="/datasources/proxy/:id/*",instance="192.168.195.17:3000",job="grafana",method="get",namespace="monitoring",pod="grafana-5d9d5f67c4-lgj96",service="grafana",statuscode="200"}[1h])/3600
等于
rate(http_request_total{endpoint="http",handler="/datasources/proxy/:id/*",instance="192.168.195.17:3000",job="grafana",method="get",namespace="monitoring",pod="grafana-5d9d5f67c4-lgj96",service="grafana",statuscode="200"}[1h])
如果想要更灵敏使用irate(): 瞬时增长率,取最后两个数据进行计算,而不是一个小时进行平均数据,不适合做需要分期长期趋势或者在告警规则中使用。
预测统计:
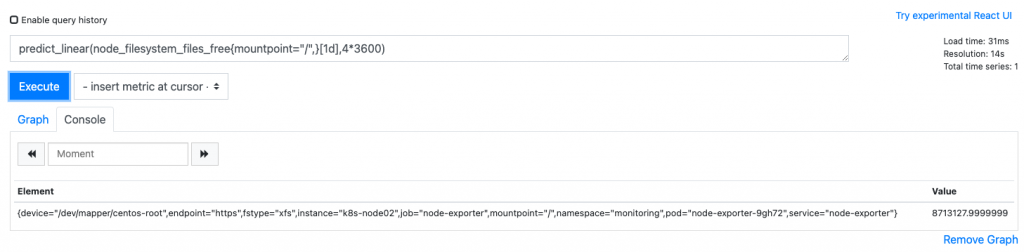
根据一天的数据,预测4个小时之后,磁盘分区的空间会不会小于0
predict_linear(node_filesystem_files_free{mountpoint="/",}[1d],4*3600)<0
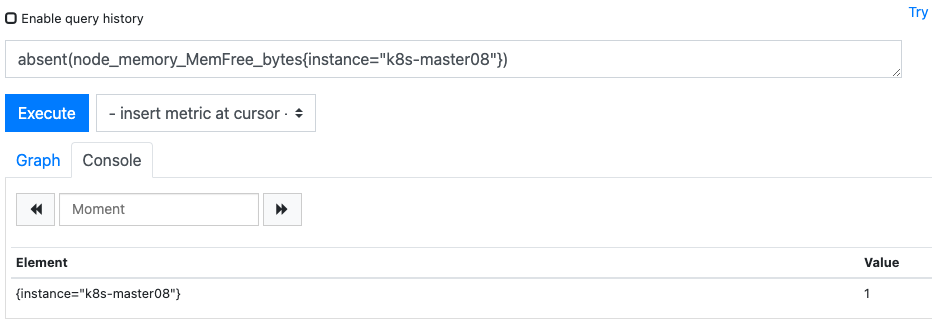
absent():如果样本数据不为空则返回no data,如果为空则返回1。判断数据是否在正常采集
absent(node_memory_MemFree_bytes{instance="k8s-master08"})
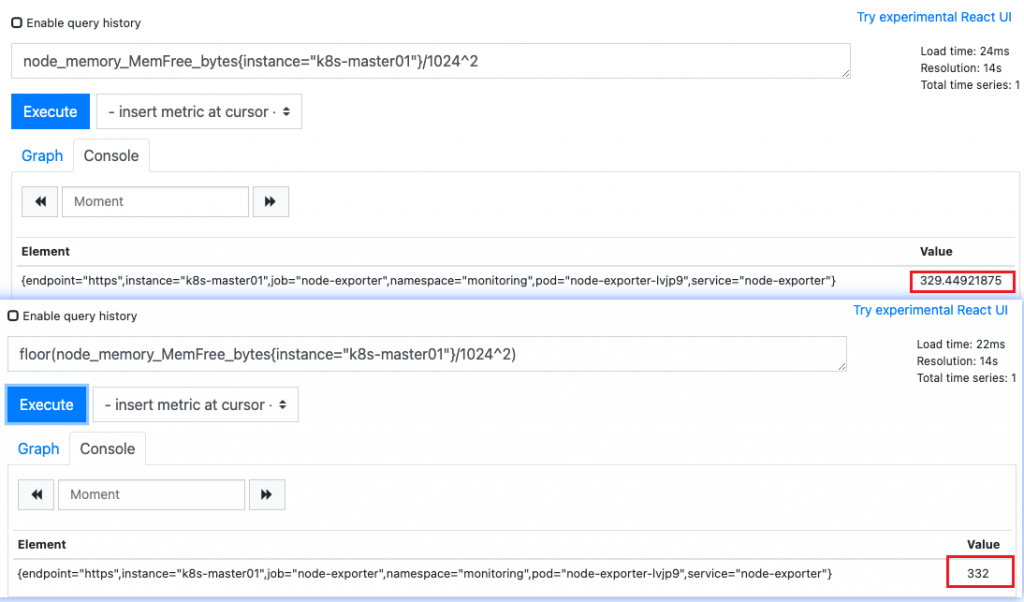
去除小数点:
Ceil():四舍五入,向上取最接近的整数,2.79 -> 3
floor():向下取, 2.79 -> 2
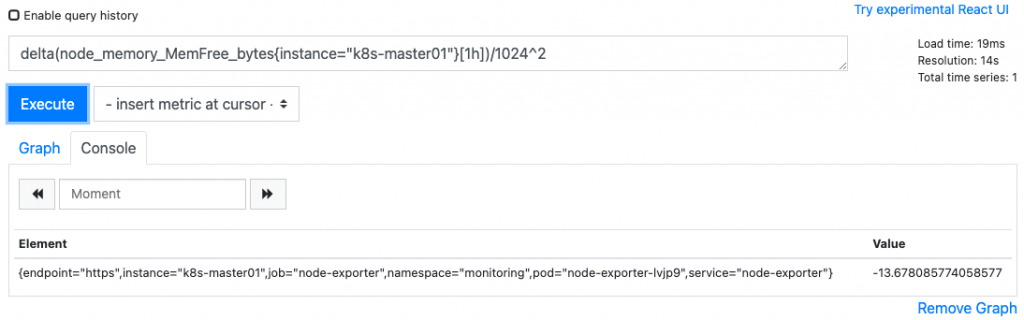
Delta():差值
查看一小时内的内存差距(类似于increase)delta(node_memory_MemFree_bytes{instance="k8s-master01"}[1h])/1024^2
排序:
sort():正序
sort_desc():倒序
Label_join:
将数据中的一个或多个label的值赋值给一个新label(指定连接符,可以做一些数据的处理)
label_join(node_filesystem_files_free, "new_label", ",", "instance", "mountpoint")
将instance、mountpoint的值使用“,”连接,成为"new_label"的 value
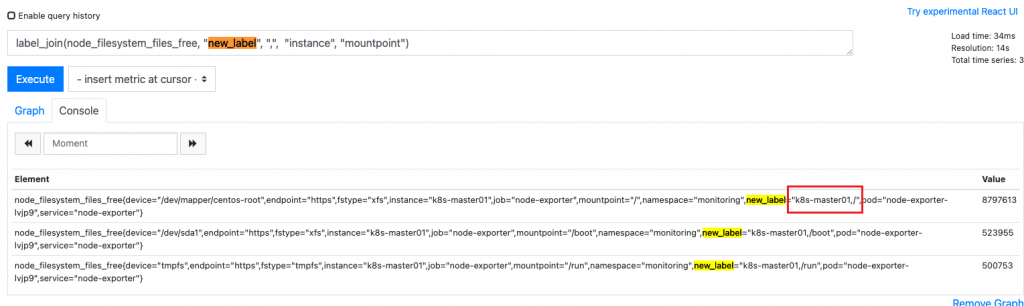
label_replace:根据数据中的某个label值,进行正则匹配,然后赋值给新label并添加到数据中
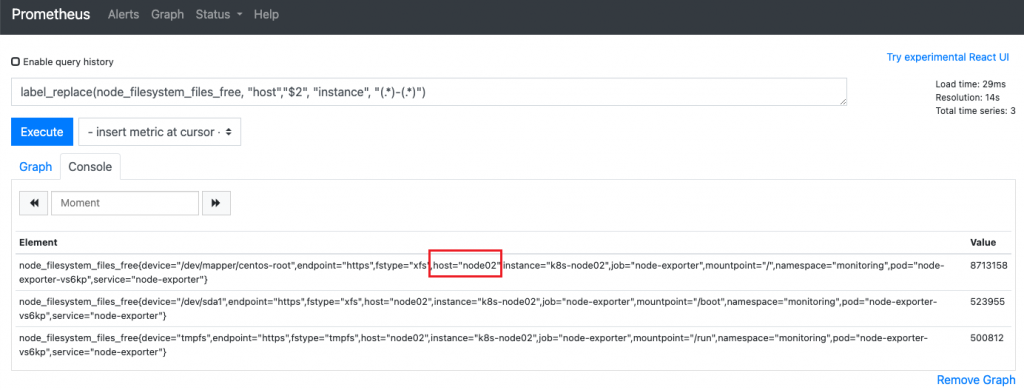
label_replace(node_filesystem_files_free, "host","$2", "instance", "(.*)-(.*)")
本题为根据instance的值通过正则匹配(.*)-(.*) $2匹配到的值赋值给新的label host中(将instance中k8s-node02中的“node02”匹配到然后添加到新标签 host 的 value中去,得到: host=node02)
实战案例
CPU使⽤率 计算公式
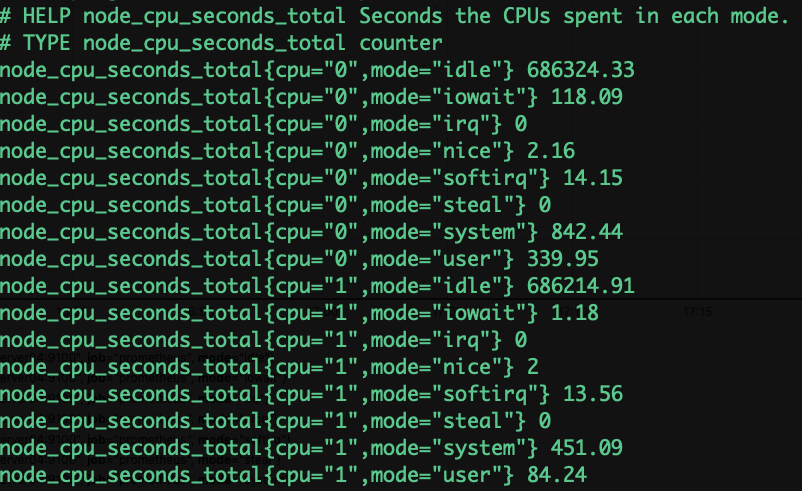
采集的metrics
简单的总结如下:
Linux系统开启后,CPU开始进⼊⼯作状态,每⼀个不同状态的CPU使⽤时间 都从零开始累计 ⽽我们在被监控客户端安装的node_exporter 会抓取 并返回给我们常⽤的⼋种CPU状态的累积时间数值
我们就先使⽤ ⽤户态CPU来给⼤家举个例⼦ ⽤户态CPU通常是 占⽤整个CPU状态 最多的类型 , 当然也有个别的情况,内核态 或 IO等待 占⽤的更多TOP => user%
12:00 开机后 ⼀直到 12:30 截⽌ 这30分钟的过程中(当前我们先暂时忽略 是⼏核CPU 就当作1核来说)

所以 针对这30分钟 我们的CPU平均使⽤率就是 30%

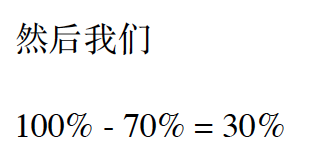



increase()

接下来 来看第⼆个问题

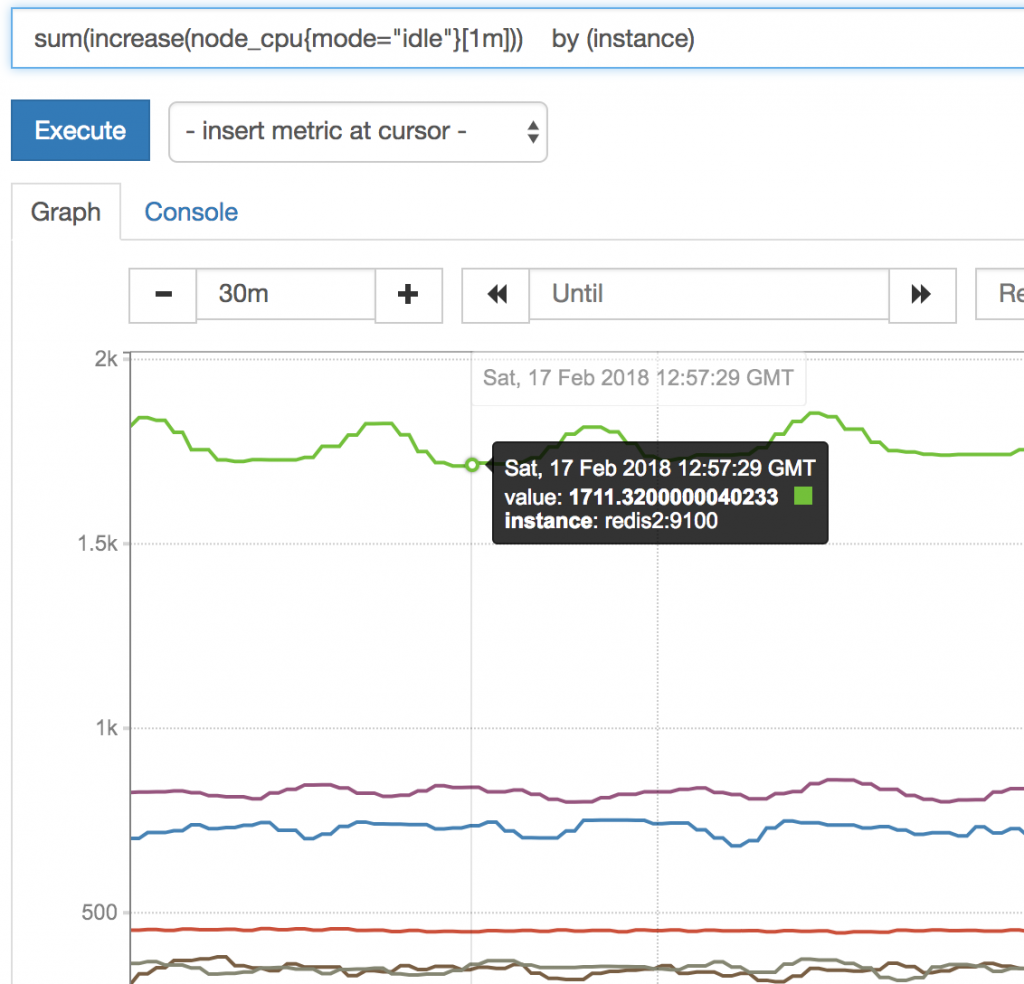
sum() 函数

拆分 并 解释 这个运算公式
注:新版本node_cpu_seconds_total取代了node_cpu
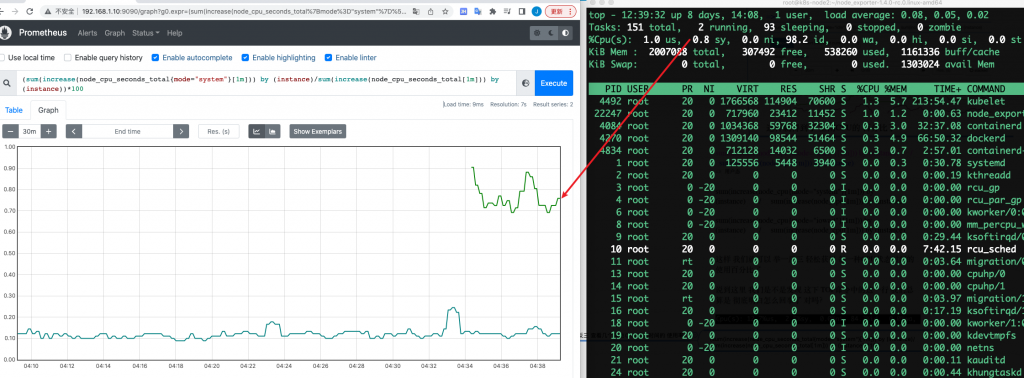
(1-((sum(increase(node_cpu_seconds_total{mode="idle"}[1m])) by (instance))/(sum(increase(node_cpu_seconds_total[1m])) by (instance))))*100




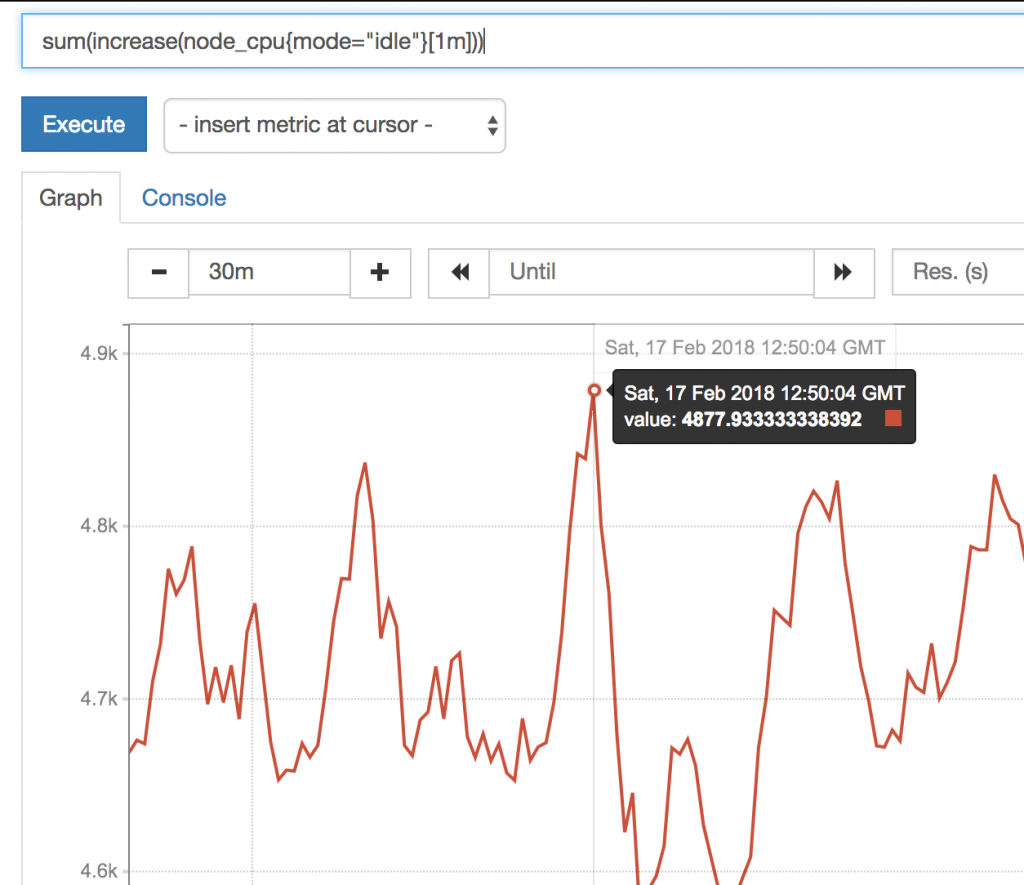
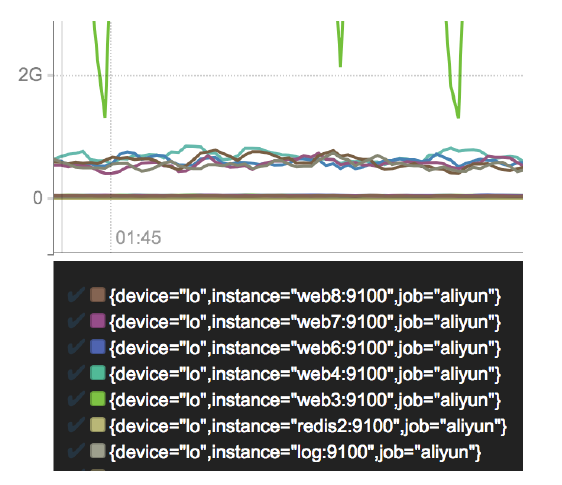
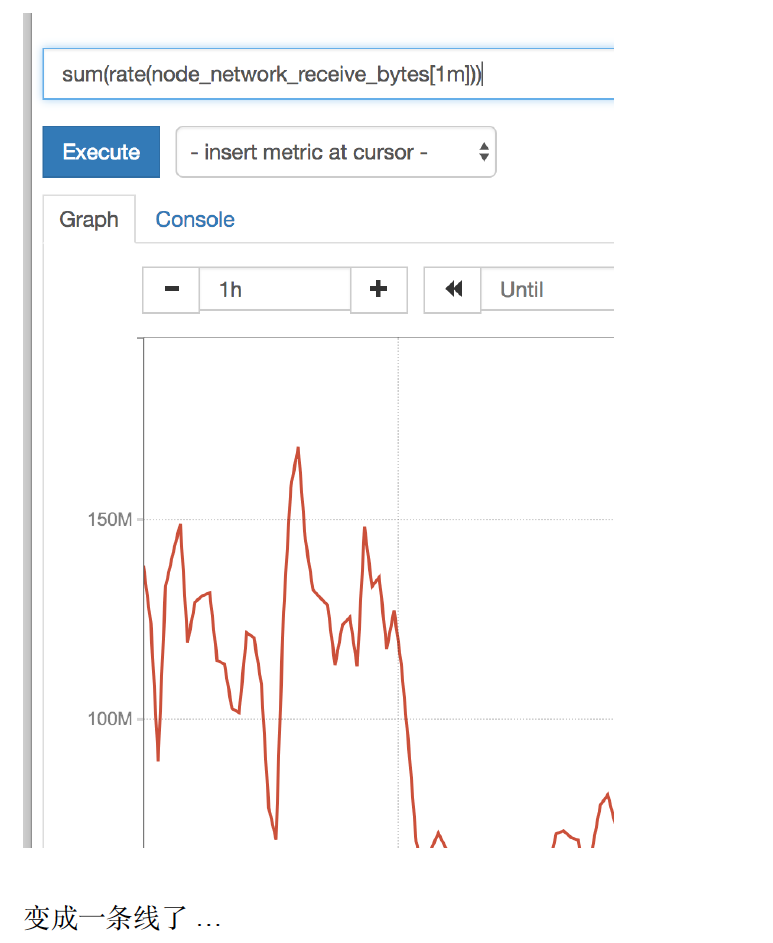
我们这个CPU的监控 其实采集的是 多台服务器的监控数据,怎么现在变成就⼀条线了???



也可以使用irate()占用百分比
100-(avg(irate(node_cpu_seconds_total{mode="idle"}[5m]))by(instance)*100)
举⼀反三 查看⼏个其他CPU状态时间的 使⽤率

计算内核态:
(sum(increase(node_cpu_seconds_total{mode="system"}[1m])) by (instance)/sum(increase(node_cpu_seconds_total[1m])) by (instance))*100
Prometheus 函数详细讲解
prometheus命令⾏格式

我就使⽤这个key 来进⾏我们的命令⾏ 正式的学习
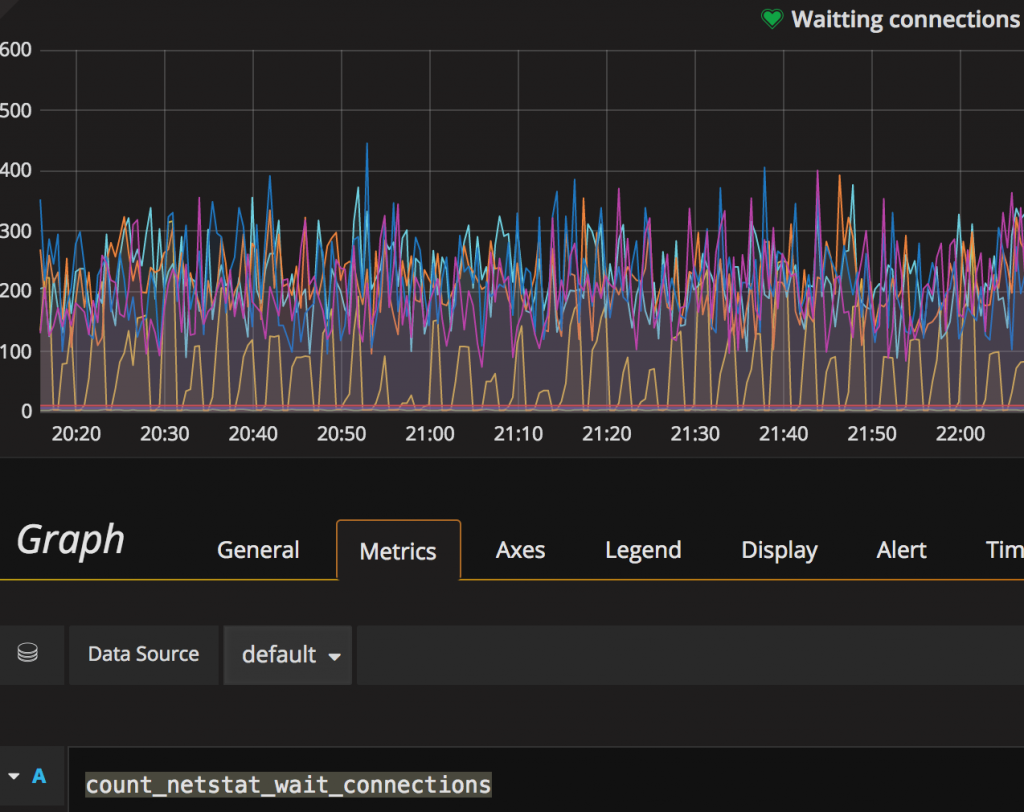
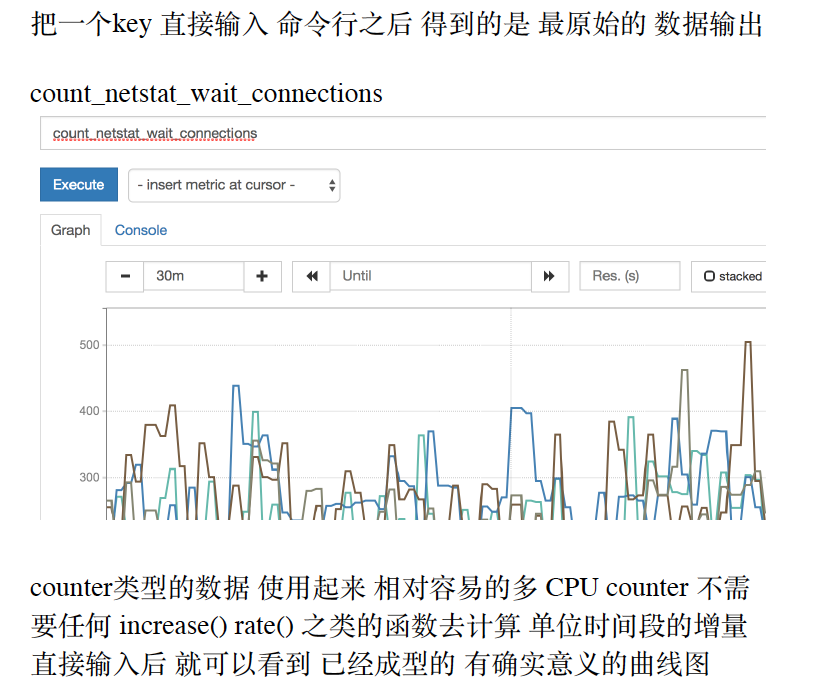
count_netstat_wait_connections
默认输⼊后 会把所有 安装了这个采集项的 服务器数据都显⽰出来我们来学习 命令⾏的 过滤

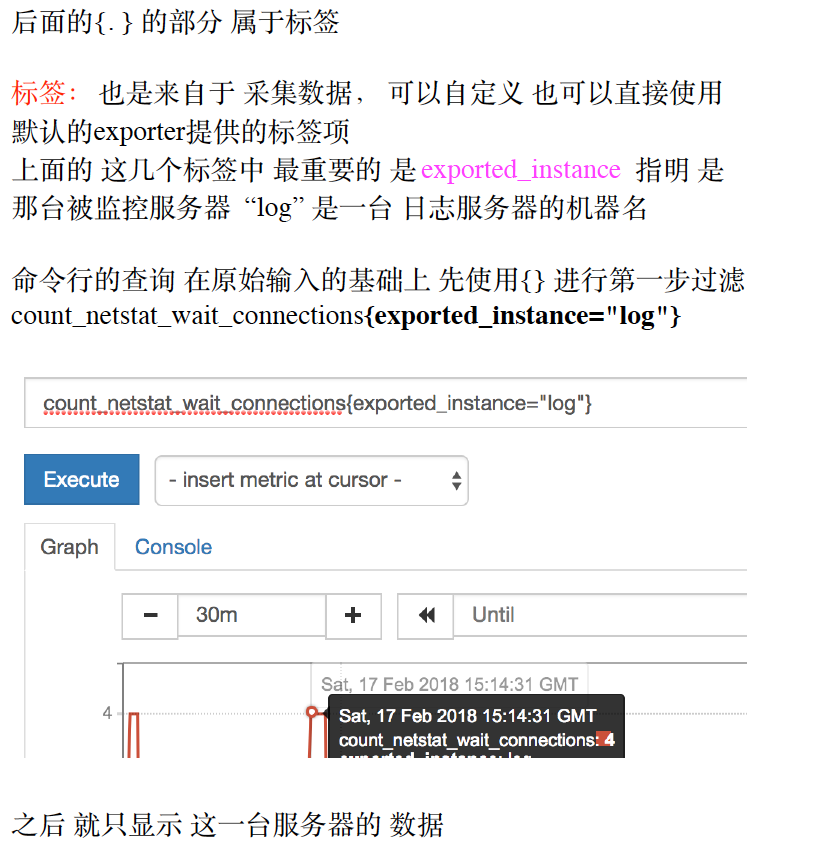
过滤除了精确匹配 还有 模糊匹配
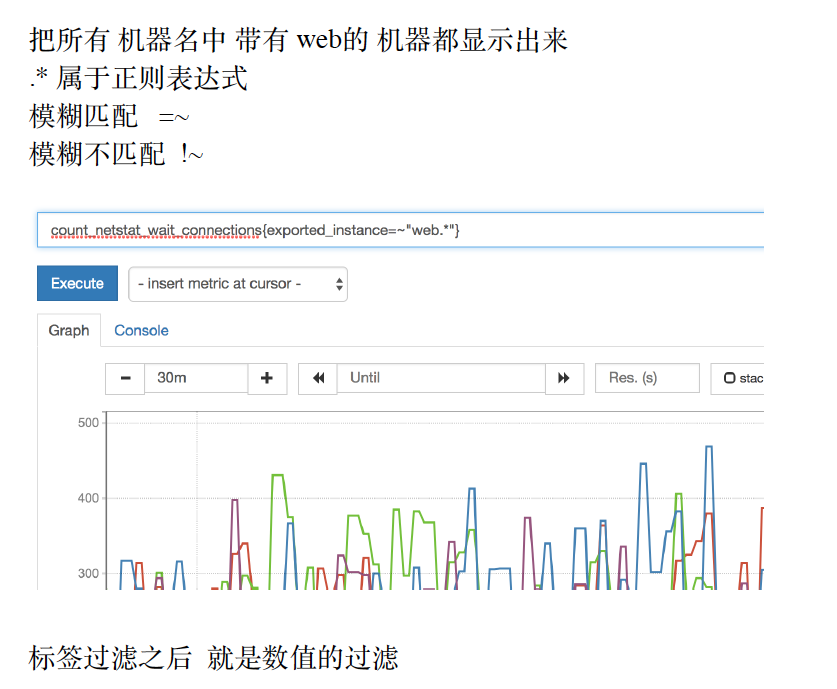
标签过滤之后 就是数值的过滤
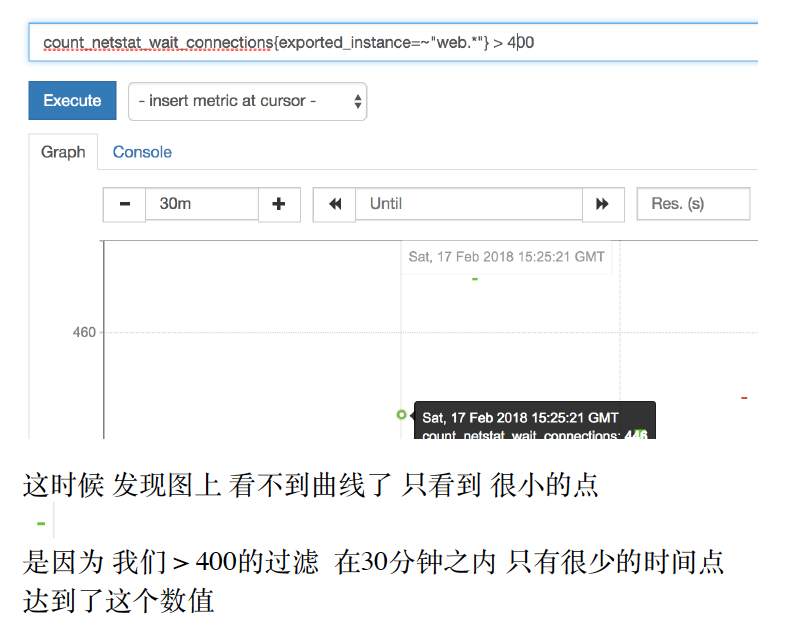
⽐如我们只想找出 wait_connection数量 ⼤于200的count_netstat_wait_connections{exported_instance=~"web.*"}> 400
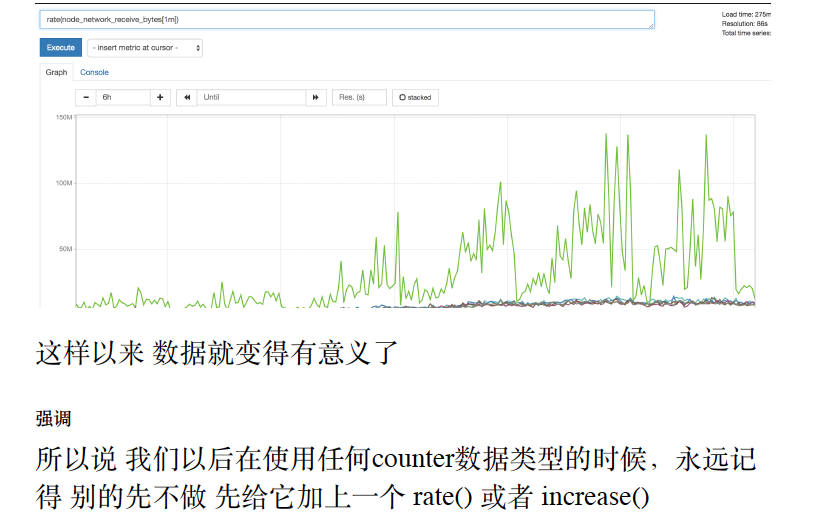
rate 函数的使⽤
rate 函数可以说 是prometheus提供的 最重要的函数之⼀


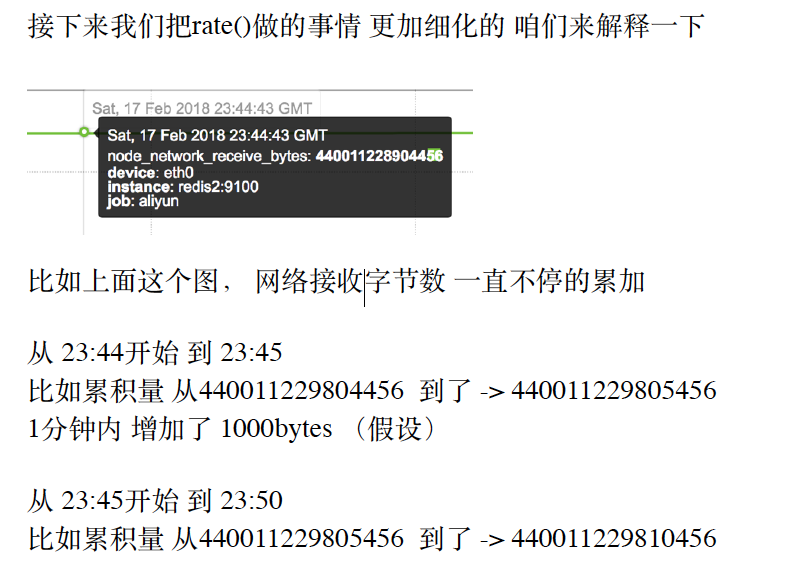

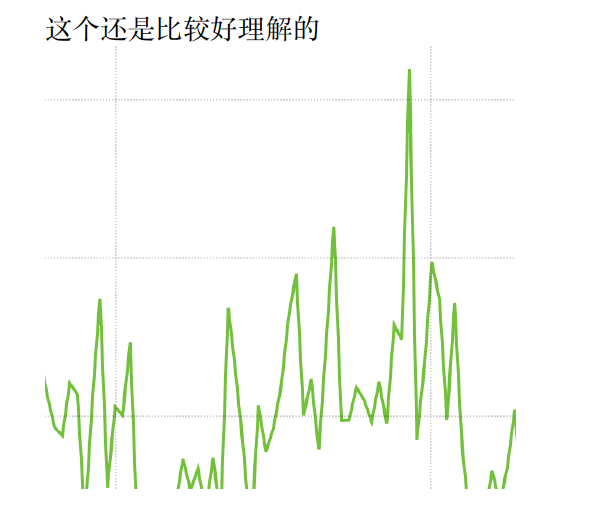

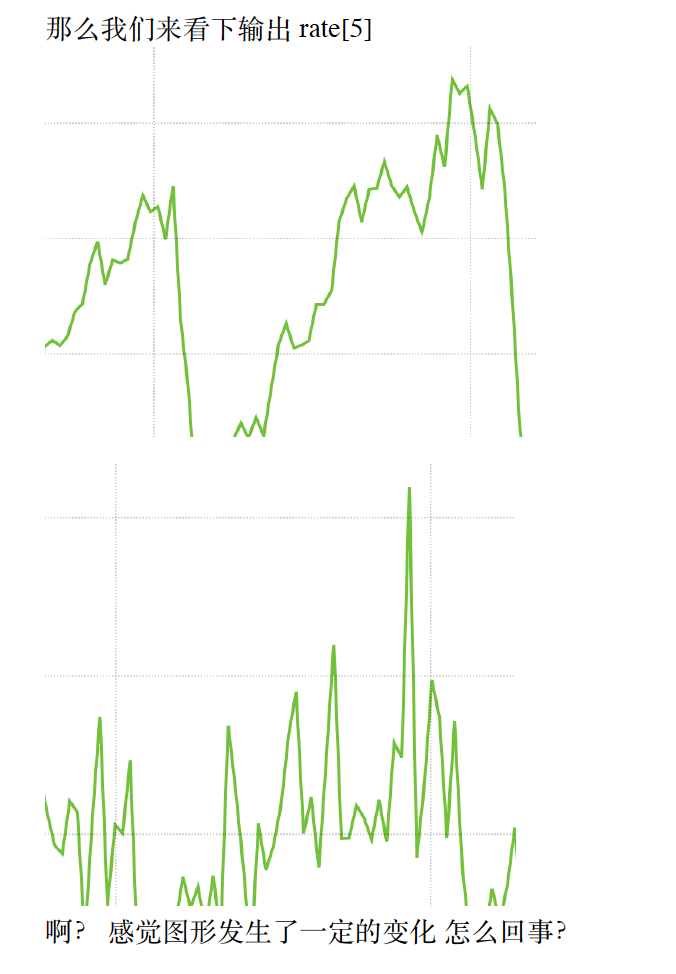

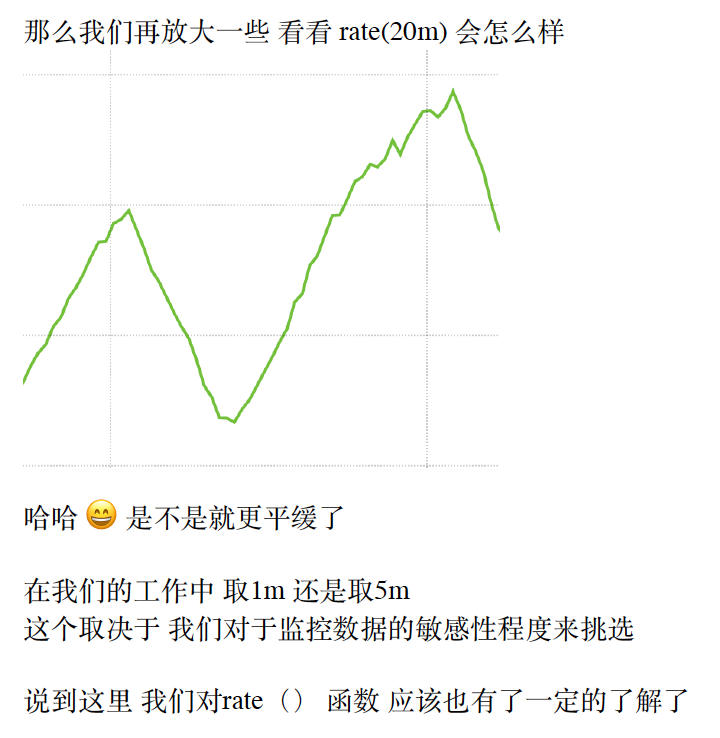
increase 函数的使⽤
increase 函数 其实和rate() 的概念及使⽤⽅法 ⾮常相似


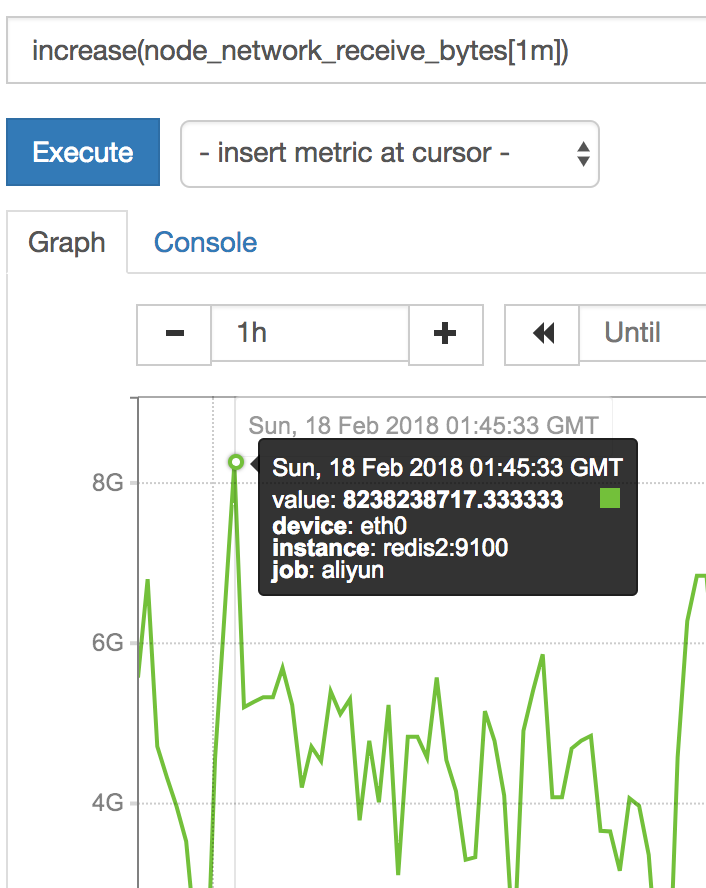
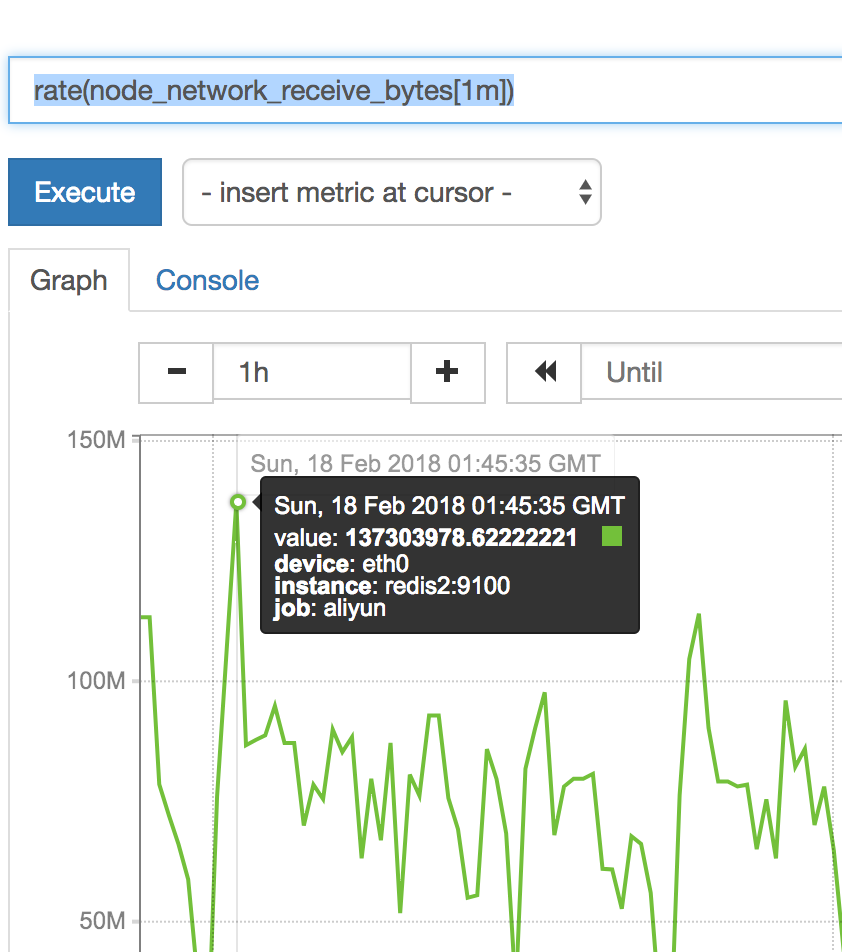

变化平缓的数据用increase(),瞬息万变用rate()
sum函数使⽤






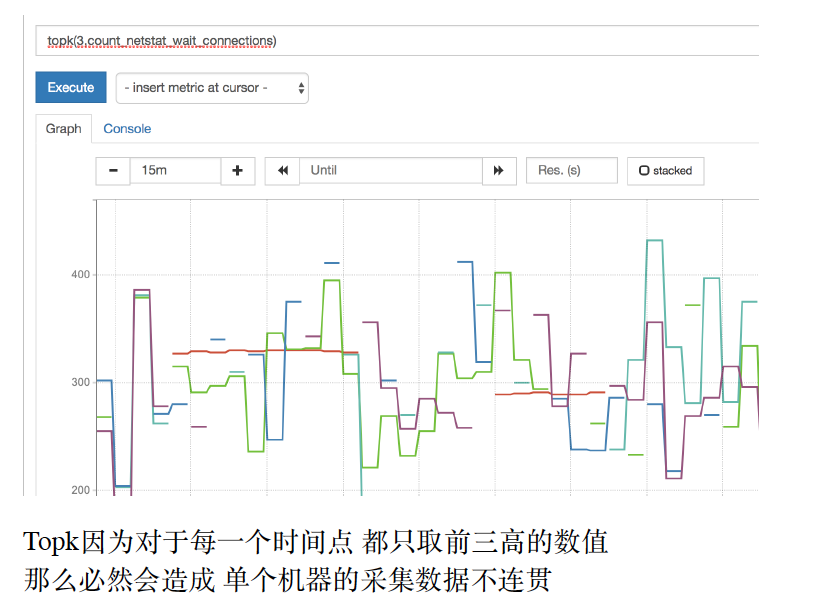
topk(x,)







count()



企业级监控数据采集⽅方法
prometheus 服务端的安装和后台稳定运⾏
prometheus 服务端配置⽂件写法
node_exporter 安装和后台运⾏
node_exporter 观察 和 采集数据
我们去到 node_exporter在 github上的地址来看看 我们伟⼤的社区开发者们 都给咱们提供了 哪些有⽤的采集项⽬ 链接:https://github.com/prometheus/node_exporter
prometheus 查询采集回来的各种数据
随便挑⼏个 key 就可以查看
另外 prometheus 的命令⾏ 本⾝也⽀持suggest 功能(输⼊提⽰)
随便找个key 查询⼀下 是否有图输出 就可以了
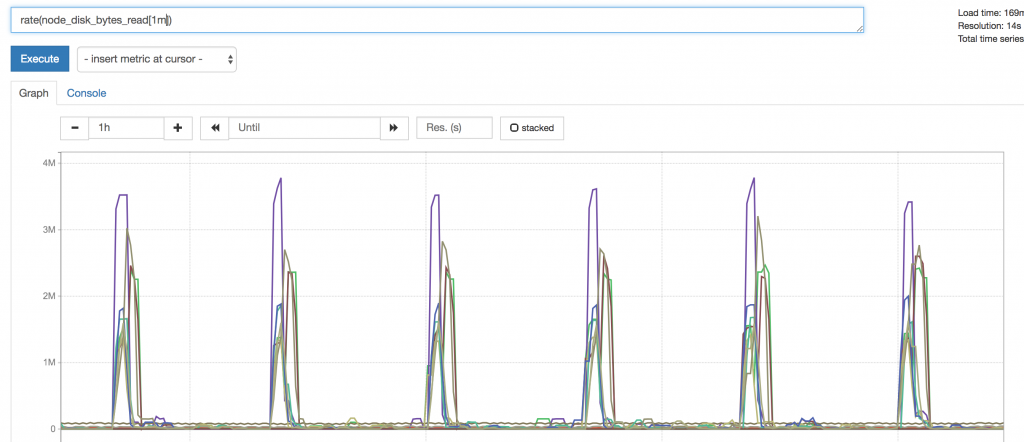
使⽤我们之前的学过的 prometheus 命令⾏的形式 练习组合各种监控图
接下来 咱们找⼀个 ⽐较重要的key 然后 ⽤我们学过的 命令⾏⽅式 给他组成⼀个 临时监控图
⽐如node_cpu node_memory node_disk

企业级监控数据采集脚本开发实践(Pushgateway模块学习)
pushgateway 的介绍
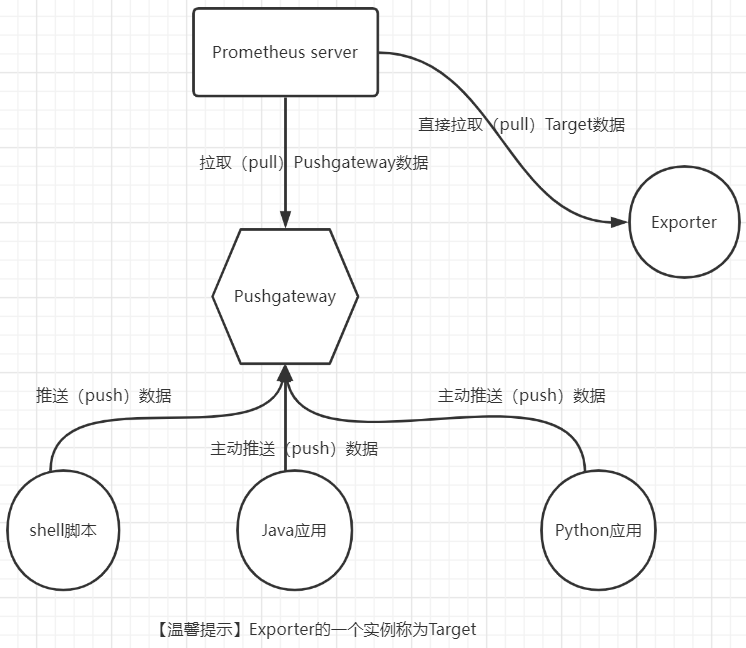
pushgateway 是另⼀种采⽤被动推送的⽅式(⽽不是exporter主动获取)获取监控数据的prometheus 插件,Pushgateway就是个数据中转站。提供API,支持数据生产者随时将数据推送过来。
它是可以单独运⾏在 任何节点上的插件(并不⼀定要在被监控客户端)然后 通过⽤户⾃定义开发脚本 把需要监控的数据 发送给pushgateway,然后pushgateway 再把数据 推送给prometheus server
pushgateway 的安装和运⾏和配置
pushgateway 跟 prometheus和 exporter ⼀样,解压后 直接运⾏
下载地址:https://prometheus.io/download/#pushgateway
github的官⽅地址:https://github.com/prometheus/pushgateway
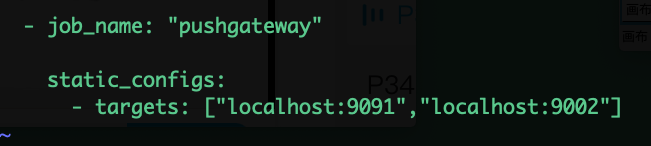
pushgateway的配置 主要指的是 在prometheus sever端的配

mkdir -p /usr/local/node_exporter && cd /usr/local/node_export
tar xf pushgateway-1.4.3.linux-amd64.tar.gz
ln -s pushgateway-1.4.3.linux-amd64 pushgateway
daemonize -c /usr/local/node_exporter/pushgateway /usr/local/node_exporter/pushgateway/pushgateway
⾃定义编写脚本的⽅法 发送pushgateway 采集
pushgateway 本⾝是没有任何抓取监控数据的功能的 它只是被动的等待推送过来
pushgateway 编程脚本的写法
vi /usr/local/node_exporter/node_exporter_shell.sh
#!/bin/bash
instance_name=`hostname -f | cut -d'.' -f1` #本机机器名 变量⽤于之后的 标签
if [ $instance_name == "localhost" ];then # 要求机器名 不能是localhost 不然标签就没有区分了
echo "Must FQDN hostname"
exit 1
fi
# For waitting connections
label="count_netstat_wait_connections" # 定⼀个新的 key
count_netstat_wait_connections=`netstat -an | grep -i wait | wc -l`
#定义⼀个新的数值 netstat中 wait 的数量
echo "$label : $count_netstat_wait_connections"
echo "$label $count_netstat_wait_connections" | curl --databinary @- http://192.168.1.10:9091/metrics/job/pushgateway/instance/$instance_name最后 把 key & value 推送给 pushgatway,将HTTP POST请求中的数据发送给HTTP服务器器(pushgateway),与⽤用户提交HTML表单时浏览器的行为完全⼀一样。HTTP POST请求中的数据为纯二进制数据


写入crontab, 默认 只能最短⼀分钟的间隔,如果希望 ⼩于⼀分钟的间隔 15s :sleep 15
crontab -e
# node_exporter_jobs_1
* * * * * sleep 15; /usr/local/node_exporter/node_exporter_shell.sh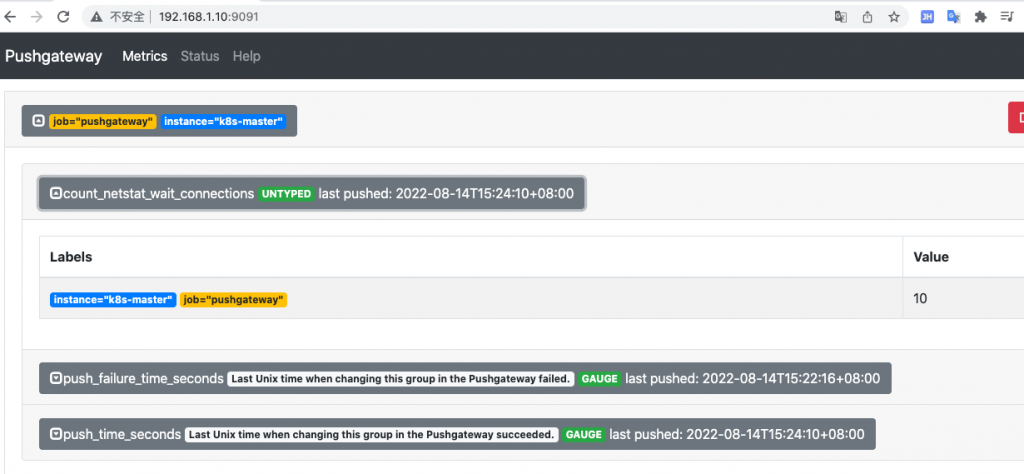
使⽤pushgateway的优缺点
pushgateway虽然灵活 但是 也是存在⼀些短板


发布者:LJH,转发请注明出处:https://www.ljh.cool/7301.html