


Prometheus概述
Prometheus是什么
Prometheus(普罗米修斯)是一个最初在SoundCloud上构建的监控系统。自2012年成为社区开源项目,拥有非常活跃的开发人员和用户社区。为强调开源及独立维护,Prometheus于2016年加入云原生云计算基金会(CNCF)
Prometheus相比与其他监控
Prometheus相⽐其他⽼款监控的 不可被替代的巨⼤优势,以及⼀些不⾜有待提⾼的
地⽅
优点
• 基于time series时间序列模型(数字 数学),是一系列有序的数据,通常是等时间间隔采样数据,监控数据的精细程度 绝对的第⼀ 可以精确到 1~5秒的采集精度 4 5分钟 理想的状态 我们来算算采集精度 (存储 性能)基于K/V数据模型,最大的好处就是数据格式简单,速度快,易维护开发
基于数学计算方式
例如(增量(A)+增量(B))/总增量(C)>固定百分比
采用HTTP pull/push两种对应的数据采集传输方式,所有数据采集都基本采用HTTP,而分为pull/push推拉两种方式去采集程序方便,几乎所有数据采集可以实现push采集方法
• 集群部署的速度 监控脚本的制作 (指的是熟练之后) ⾮常快速 ⼤⼤缩短监控的搭建时间成本
• 周边插件很丰富 exporter pushgateway ⼤多数都不需要⾃⼰开发了
• 本⾝基于数学计算模型,⼤量的实⽤函数 可以实现很复杂规则的业务逻辑监控(例如QPS的曲线 弯曲 凸起 下跌的 ⽐例等等模糊概念)
• 可以嵌⼊很多开源⼯具的内部 进⾏监控 数据更准时 更可信(其他监控很难做到这⼀点)
• 本⾝是开源的,更新速度快,bug修复快。⽀持N多种语⾔做本⾝和插件的⼆次开发
• 图形很⾼⼤上 很美观 ⽼板特别喜欢看这种业务图 (主要是指跟Grafana的结合)
⼀些不⾜的地⽅
因其数据采集的精度 如果集群数量太⼤,那么单点的监控有性能瓶颈 ⽬前尚不⽀持集群 只能workaround
学习成本太⼤,尤其是其独有的数学命令⾏(⾮常强⼤的同时 又极其难学《=⾃学的情况下),中⽂资料极少,本⾝的各种数学模型的概念很复杂(如果没⼈教 ⾃⼰⼀点点学英⽂官⽹ 得 1-3 个⽉⼊门)
• 对磁盘资源也是耗费的较⼤,这个具体要看 监控的集群量 和 监控项的多少 和保存时间的长短
本⾝的使⽤ 需要使⽤者的数学不能太差 要有⼀定的数学头脑(这个说真的 我觉得才是最难克服的)
官方网站和项目托管网站
https://prometheus.io
https://github.com/prometheus
Prometheus 特点
多维数据模型:由度量名称和键值对标识的时间序列数据
PromSQL:一种灵活的查询语言,可以利用多维数据完成复杂的查询
不依赖分布式存储,单个服务器节点可直接工作
基于HTTP的pull方式采集时间序列数据
推送时间序列数据通过PushGateway组件支持
通过服务发现或静态配置发现目标
多种图形模式及仪表盘支持(grafana)
Prometheus组成及架构
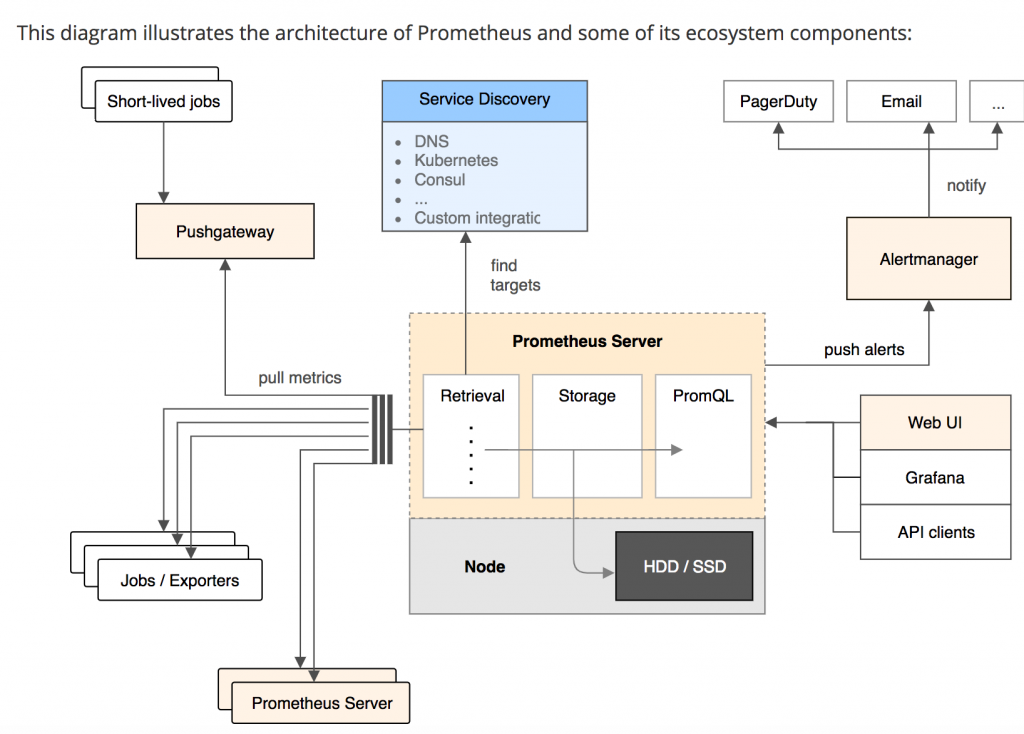
Prometheus Server:收集指标和存储时间序列数据,并提供查询接口
ClientLibrary:客户端库(提供各种语言的api)
Exporters:采集已有的第三方服务监控指标并暴露metrics
Alertmanager:告警
Web UI:简单的Web控制台
上图组件细说:
普罗米修斯的存储方式:

服务发现:

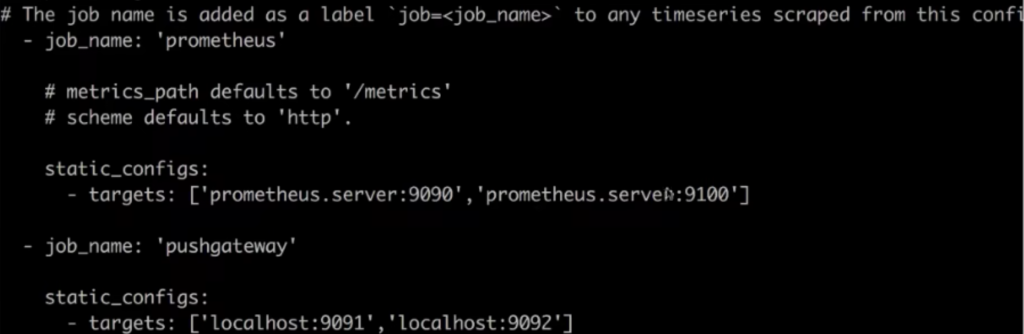
配置文件中定义了一个大的Job名字,在这个Jobs的名字下具体定义要被监控的节点以及节点上具体的端口信息等等
如果配合了例如consul这种服务发现的软件,配置文件就不需要在用人工手工定义,而是能自动发现集群中有哪些机器上出现了那些新服务可以被监控
Job / Exporters
pull主动拉取的形式
客户端(被监控机器)先安装各类已有expotrers(由社区组织或企业开发的监控客户端插件)在系统上之后,exporter以守护进程的模式运行并开始采集数据exporter本身亦是一个http_server可以对http请求作出响应 返回数据(K/V mertics)
prometheus用pull这种主动拉的方式(HTTP get)去访问每个节点上exporter并采样回需要的数据
push 被动推送的形式

报警部分
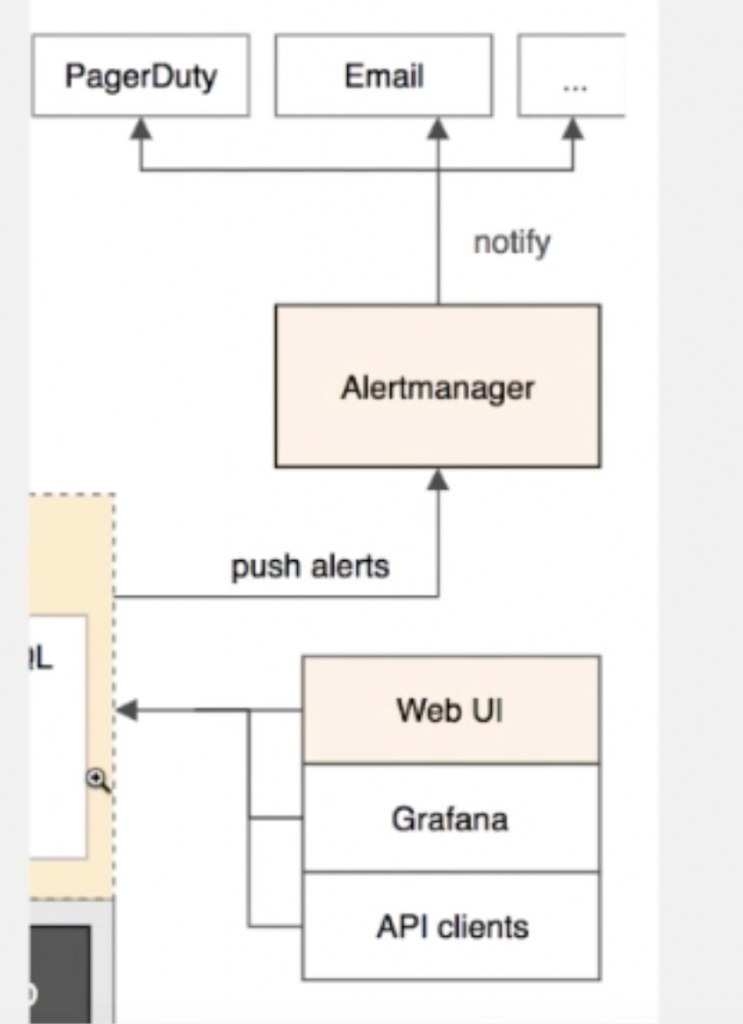
Alermanager不具体讲了:因为可以集成到Grafana上,通过Grafana报警到商业报警平台
Prometheus数据格式
metrics的概念

指标类型
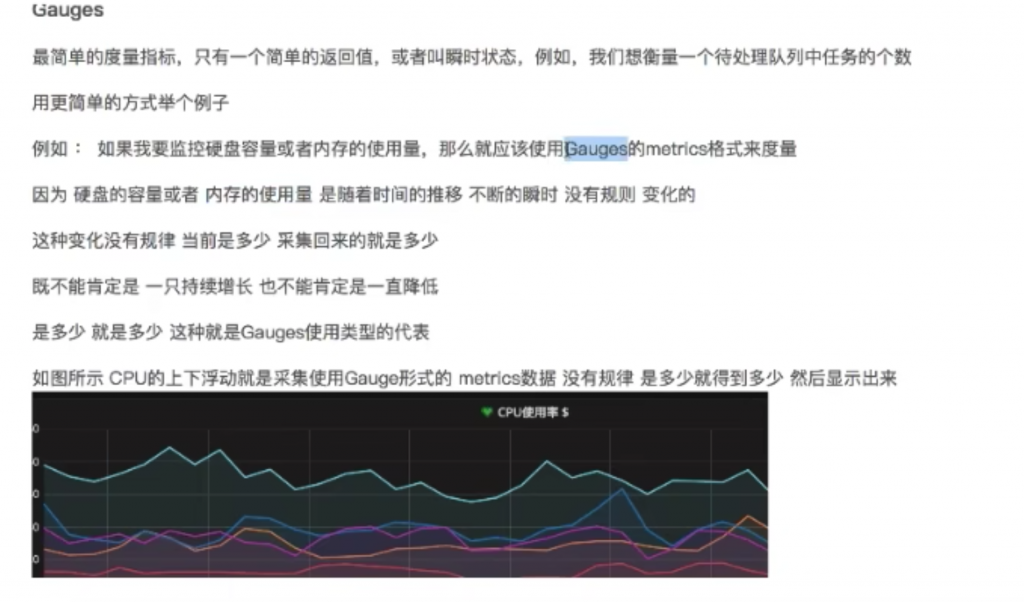
•Gauge:可以任意变化的数值
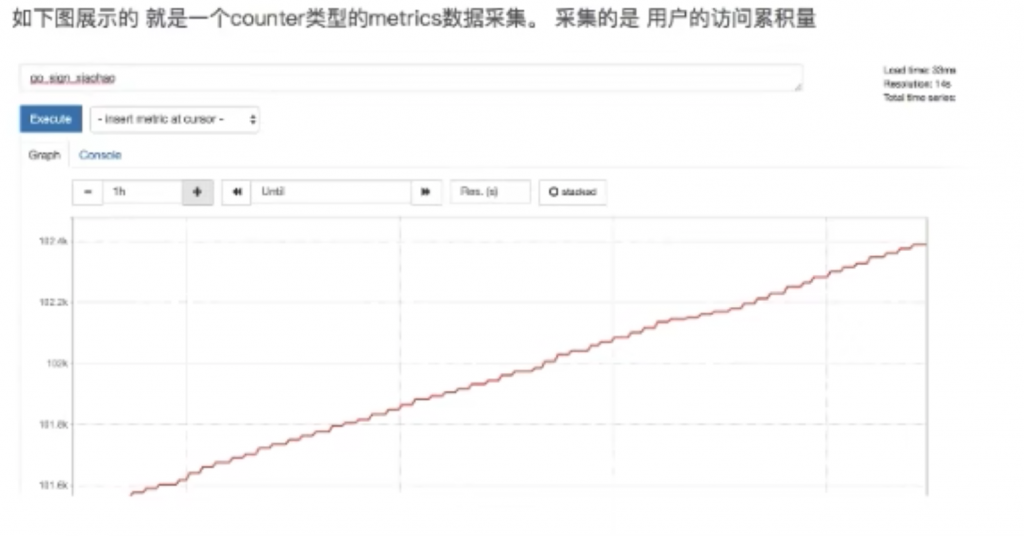
•Counter:递增的计数器
•Histogram:对一段时间范围内数据进行采样,并对所有数值求和与统计数量
•Summary:与Histogram类似,使用分位数测量低于数值的具体值的统计
文字解释几个指标:
Counter:只增不减的计数器
Counter类型的指标其工作方式和计数器一样,只增不减(除非系统发生重置)。常见的监控指标,如http_requests_total,node_cpu都是Counter类型的监控指标。 一般在定义Counter类型指标的名称时推荐使用_total作为后缀。
Counter是一个简单但有强大的工具,例如我们可以在应用程序中记录某些事件发生的次数,通过以时序的形式存储这些数据,我们可以轻松的了解该事件产生速率的变化。 PromQL内置的聚合操作和函数可以让用户对这些数据进行进一步的分析:
例如,通过rate()函数获取HTTP请求量的增长率:
rate(http_requests_total[5m])
查询当前系统中,访问量前10的HTTP地址:
topk(10, http_requests_total)
Gauge:可增可减的仪表盘
与Counter不同,Gauge类型的指标侧重于反应系统的当前状态。因此这类指标的样本数据可增可减。常见指标如:node_memory_MemFree(主机当前空闲的内存大小)、node_memory_MemAvailable(可用内存大小)都是Gauge类型的监控指标。
通过Gauge指标,用户可以直接查看系统的当前状态:
node_memory_MemFree
对于Gauge类型的监控指标,通过PromQL内置函数delta()可以获取样本在一段时间返回内的变化情况。例如,计算CPU温度在两个小时内的差异:
delta(cpu_temp_celsius{host="zeus"}[2h])
还可以使用deriv()计算样本的线性回归模型,甚至是直接使用predict_linear()对数据的变化趋势进行预测。例如,预测系统磁盘空间在4个小时之后的剩余情况:
predict_linear(node_filesystem_free{job="node"}[1h], 4 * 3600)
Histogram(直方图)
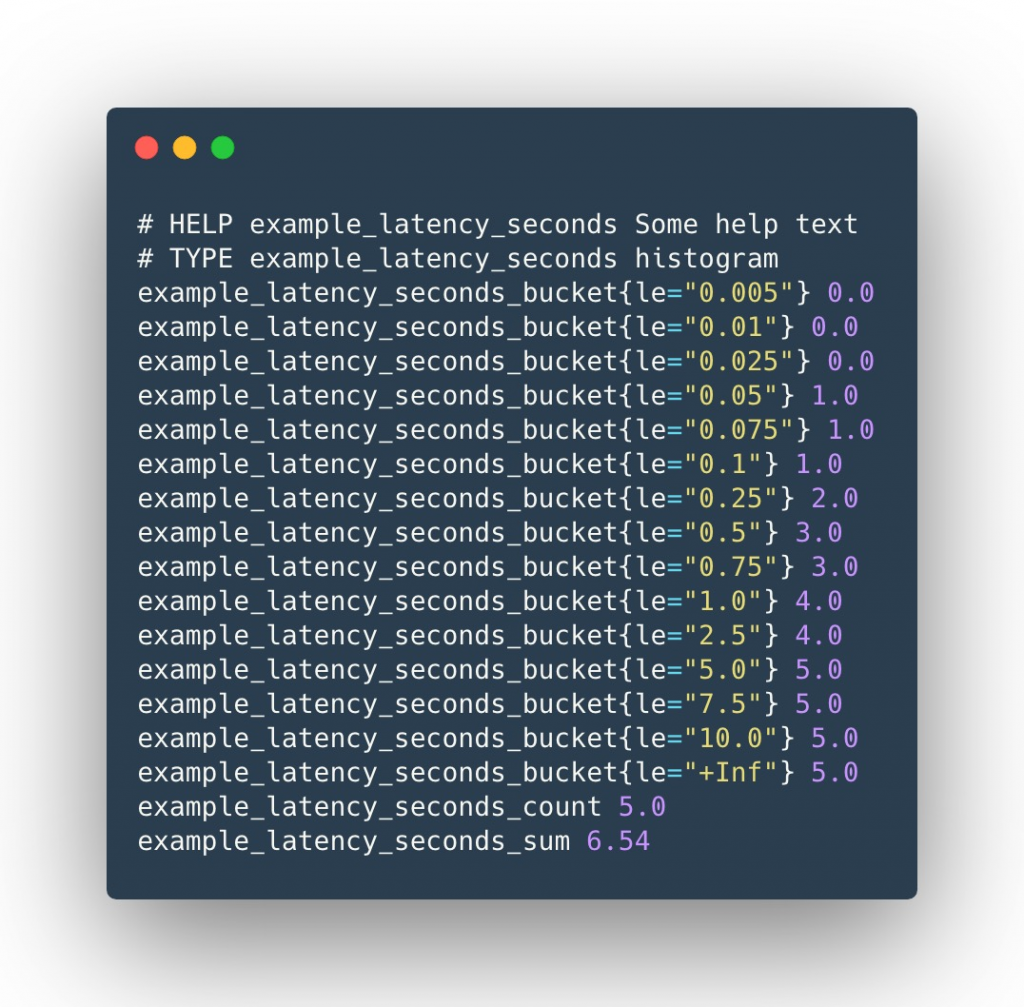
Histogram在一段时间范围内对数据进行采样,并将其计入可配置的存储桶中,后续可通过制定区间筛选样本,也可以统计样本总数,最后一般将数据展示为直方图,
- 样本的值分布在 bucket 中的数量,命名为
<basename>_bucket{le="<上边界>"}。解释的更通俗易懂一点,这个值表示指标值小于等于上边界的所有样本数量 - 所有样本值的大小总和,命名为
<basename>_sum。 - 样本总数,命名为
<basename>_count。值和<basename>_bucket{le="+Inf"}相同。
Summary(摘要)
与Histogram类似类型,用于表示一段时间内的数据采样结果(通常是请求持续时间或响应大小等),但它直接存储了分位数(通过客户端计算,然后展示出来),而不是通过区间计算
- 样本值的分位数分布情况,命名为
<basename>{quantile="<φ>"}。 - 所有样本值的大小总和,命名为
<basename>_sum。 - 所有样本值的大小总和,命名为
<basename>_sum。
Histogram与Summary的异同

- 它们都包含了
<basename>_sum和<basename>_count指标 - Histogram 需要通过
<basename>_bucket来计算分位数,而 Summary 则直接存储了分位数的值。 - 与Summary类型的指标相似之处在于Histogram类型的样本同样会反应当前指标的记录的总数(以_count作为后缀)以及其值的总量(以_sum作为后缀)。不同在于Histogram指标直接反应了在不同区间内样本的个数,区间通过标签len进行定义。
- 同时对于Histogram的指标,我们还可以通过histogram_quantile()函数计算出其值的分位数。不同在于Histogram通过histogram_quantile函数是在服务器端计算的分位数。 而Sumamry的分位数则是直接在客户端计算完成。因此对于分位数的计算而言,Summary在通过PromQL进行查询时有更好的性能表现,而Histogram则会消耗更多的资源。反之对于客户端而言Histogram消耗的资源更少。在选择这两种方式时用户应该按照自己的实际场景进行选择。
相关案例:
Gauge
Counter

Histogram




K/V数据形式

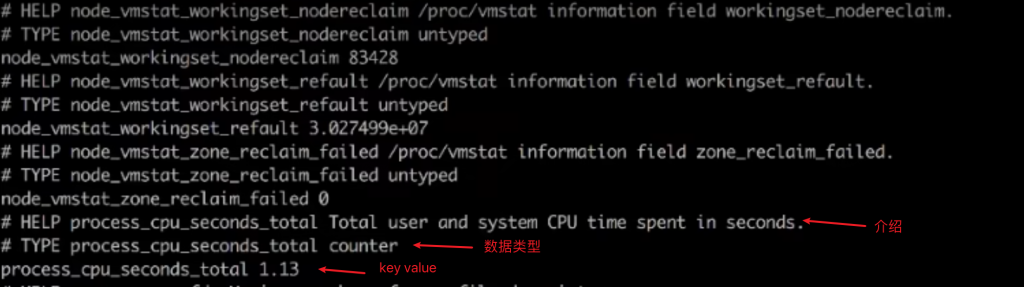
prometheus exporter的使用(pull形式采集数据)
常见的采集插件
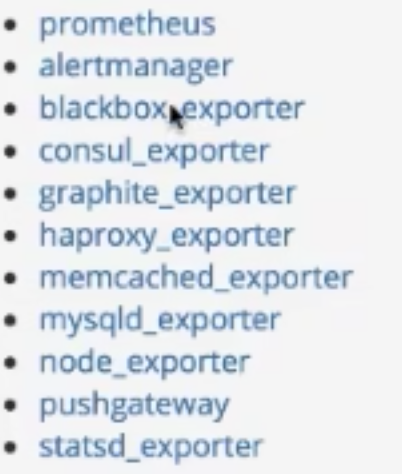

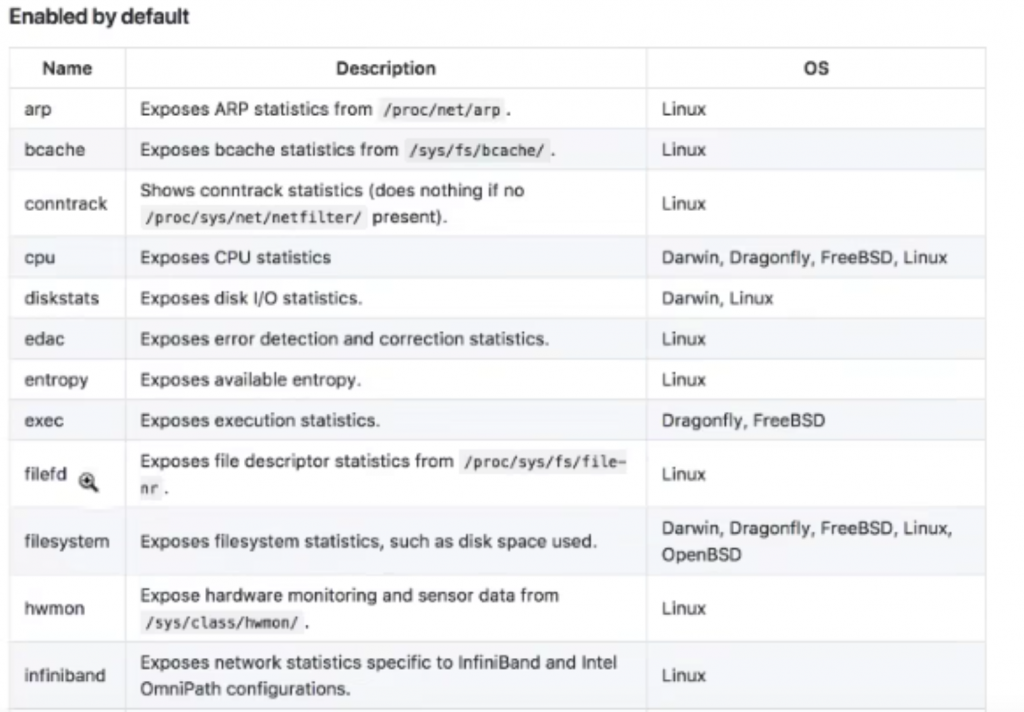
prometheus pushgateway入门介绍(push形式采集数据)

exporter和pushgateway的区别
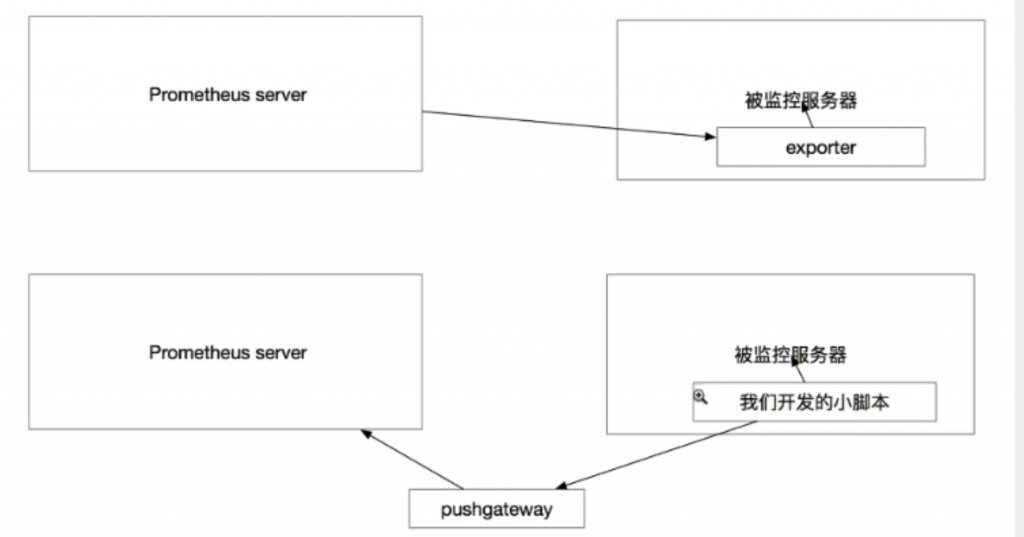
Prometheus 部署
二进制部署
官网安装包
https://prometheus.io/download/
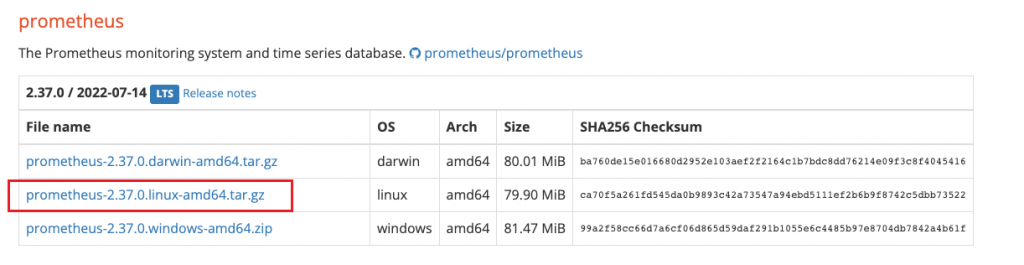
tar zxvf tar zxvf prometheus-*.gz
mv prometheus-2.38.0.linux-amd64 /usr/local/prometheus
prometheus.yml
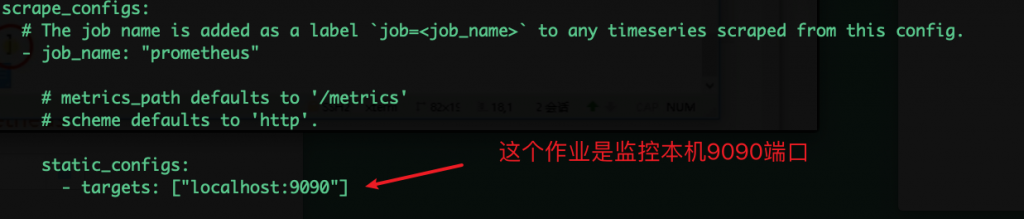
promethues命令:
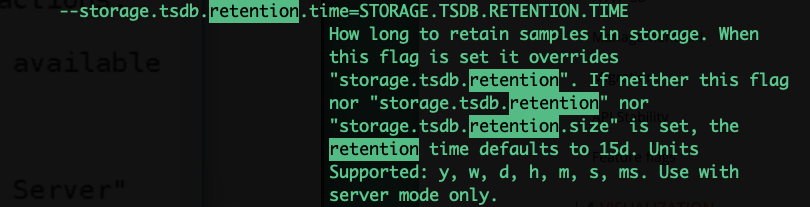
指定存储目录,默认本地

存储时间:
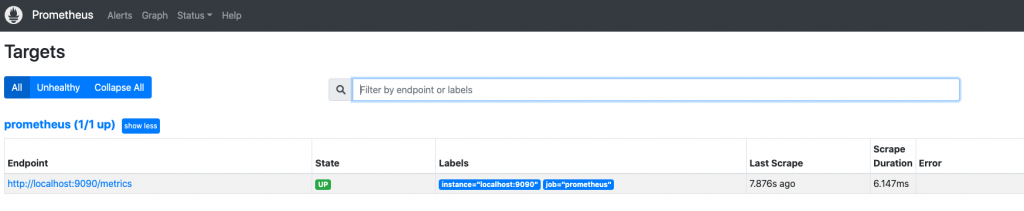
启动:
./prometheus --config.file="prometheus.yml"
访问本地9090端口
交给systemd管理:
vi /usr/lib/systemd/system/prometheus.service
[Unit]
Description=https://prometheus.io/docs
[Service]
Restart=on-failure
ExecStart=/usr/local/prometheus/prometheus --config.file=/usr/local/prometheus/prometheus.yml
[Install]
WantedBy=multi-user.targetsystemctl daemon-reload
systemctl start prometheus

add:添加两个后台部署方式(可跳过)
screen方式
安装命令:
yum -y install screen
进入screen后台
screen
执行命令
./prometheus
退出screen模式
control + a + d
screen -r 104319 可以返回前台
不足的地方:没有规范化管理模式,适合临时执行,前台列表进程不够人性化
daemonize方式
git clone https://github.com/bmc/daemonize.git
sh configure && make && sudo make install
daemonize -c /usr/local/prometheus/ /usr/local/prometheus/up.sh
-c指定路径
/usr/local/prometheus/up.sh
生产环境运行prometheus实际是需要添加额外的参数
/usr/local/prometheus/prometheus --web.listen-address="0.0.0.0:9090" --web.read-timeout=5m --web.max-connections=10 --storage.tsdb.retention=15d --storage.tsdb.path="data/" --query.max-concurrency=20 --query.timeout=3m

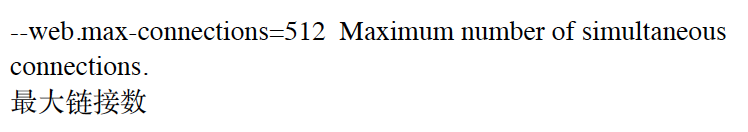



prometheus 对系统时间 ⾮常敏感 ⼀定要时时刻刻 保证系统时间同步 不然 曲线是乱的
prometheus 运⾏时 存放的历史数据 在这⼉

Docker部署
docker run \
-p 9091:9090 \
-v /usr/local/prometheus/prometheus.yml:/etc/prometheus/prometheus.yml \
prom/prometheus

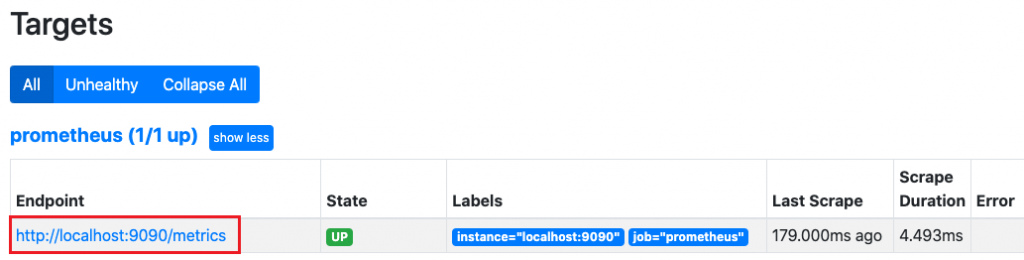
查看数据暴露的指标
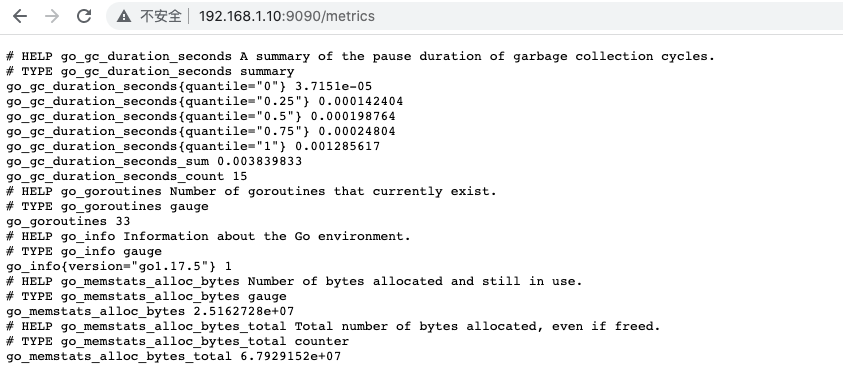
配置文件与核心功能
prometheus.yml详解
全局配置:
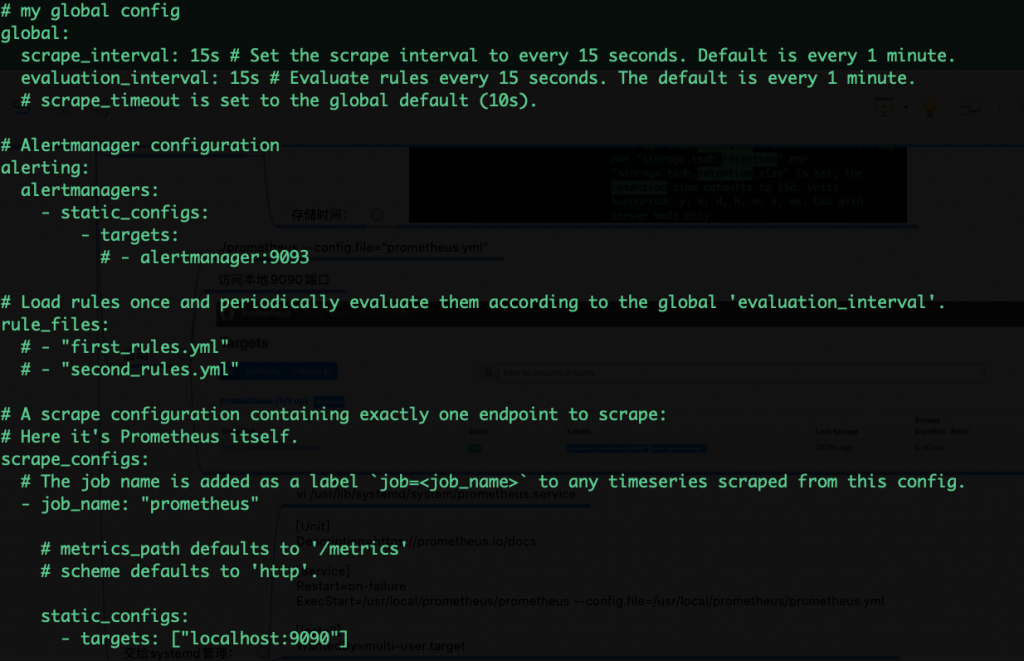
详解

Alertmanager配置:消息发送到报警平台,不讲,grafana取代
scrape_configs
如果想监控多个节点:
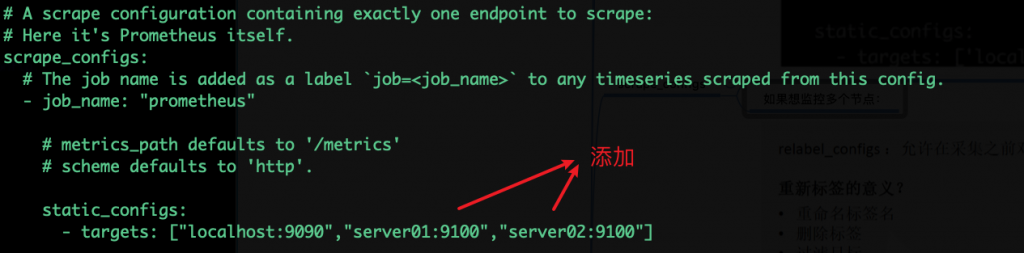
server01必须要在/etc/hosts解析
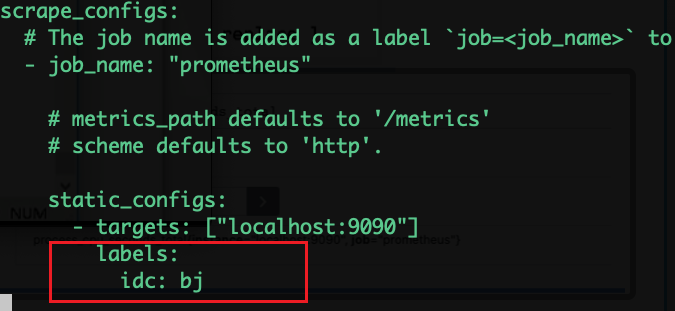
添加标签
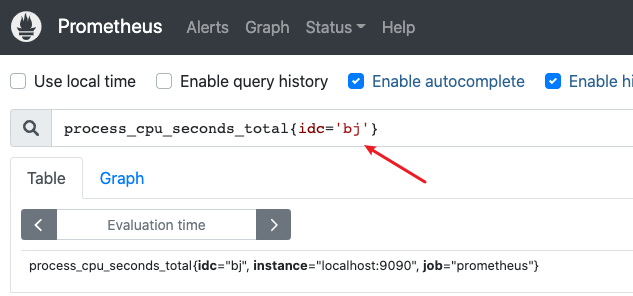
例如:查看idc机房在bj所有机器CPU使用率
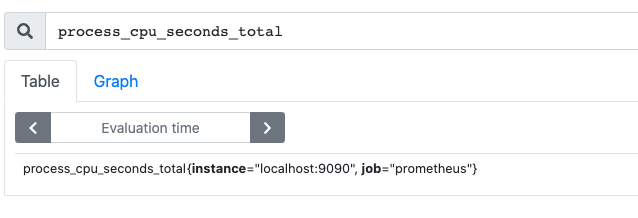
修改配置文件
检查并重启:
/usr/local/prometheus/promtool check config /usr/local/prometheus/prometheus.yml

可用作不同地区通过标签进行维度区分
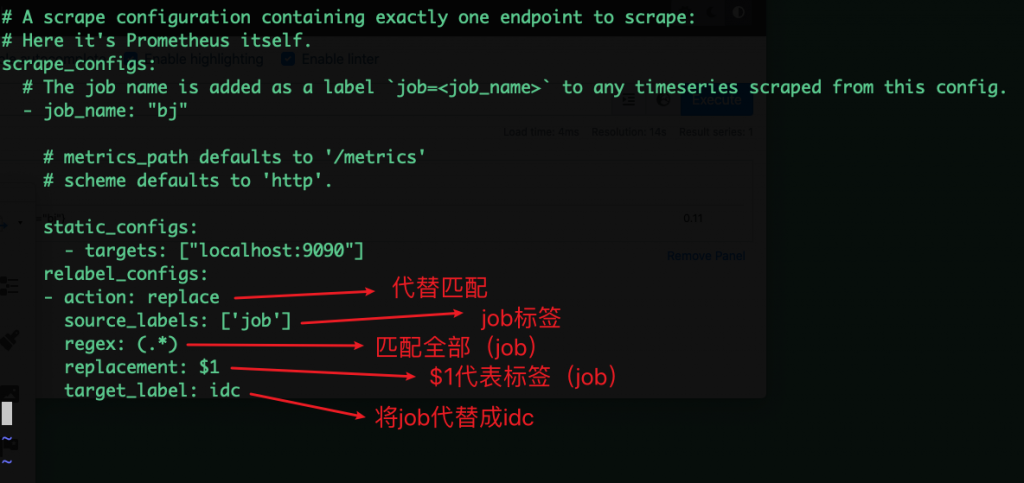
relabel_configs


标签:
重新标签动作:
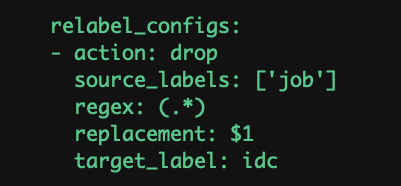
•replace:默认,通过regex匹配source_label的值,使用replacement来引用表达式匹配的分组
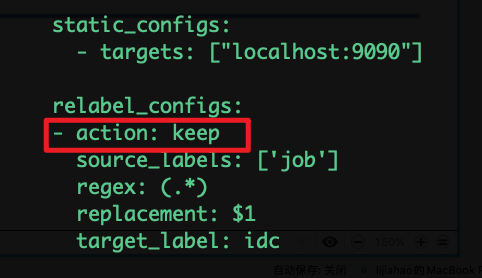
•keep:删除regex与连接不匹配的目标source_labels
•drop:删除regex与连接匹配的目标source_labels
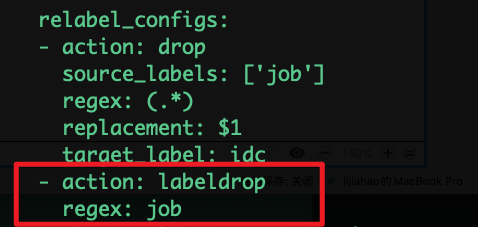
•labeldrop:删除regex匹配的标签
•labelkeep:删除regex不匹配的标签
•hashmod:设置target_label为modulus连接的哈希值source_labels
•labelmap:匹配regex所有标签名称。然后复制匹配标签的值进行分组,replacement分组引用(${1},${2},…)替代
修改标签
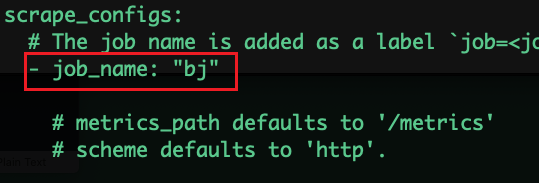
系统默认会将job_name和targets两个配置参数作为初始标签:
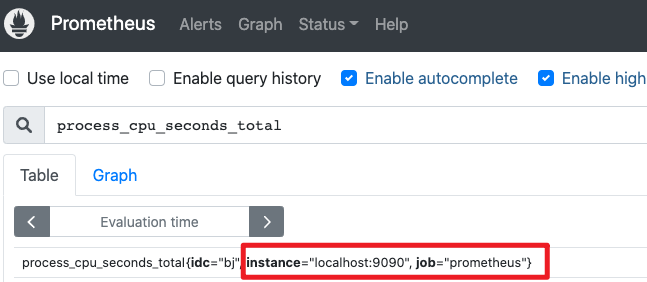
将job_name从prometheus修改成bj
./promtool check config prometheus.yml

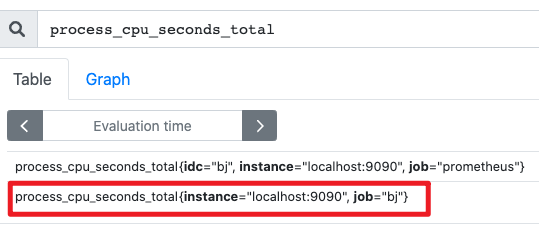
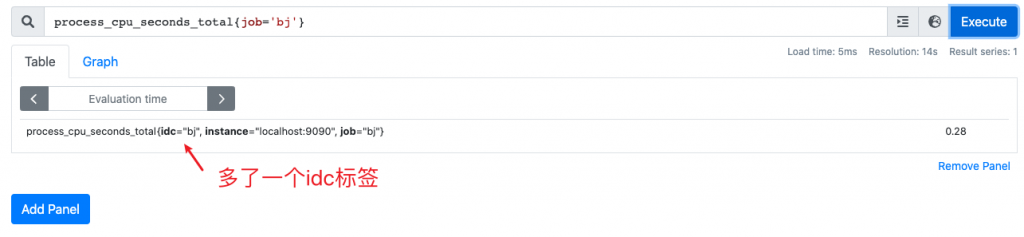
聚合:process_cpu_seconds_total{job="bj"}
删除标签:

保留标签:
labeldrop:删除regex匹配的标签

…
支持服务发现的来源

当要进行动态的缩容和扩容
vi /usr/local/prometheus/prometheus.yml
注释掉上面的行,添加
file_sd_configs:
- files: ['/usr/local/prometheus/sd_config/*.yml']
refresh_interval: 5s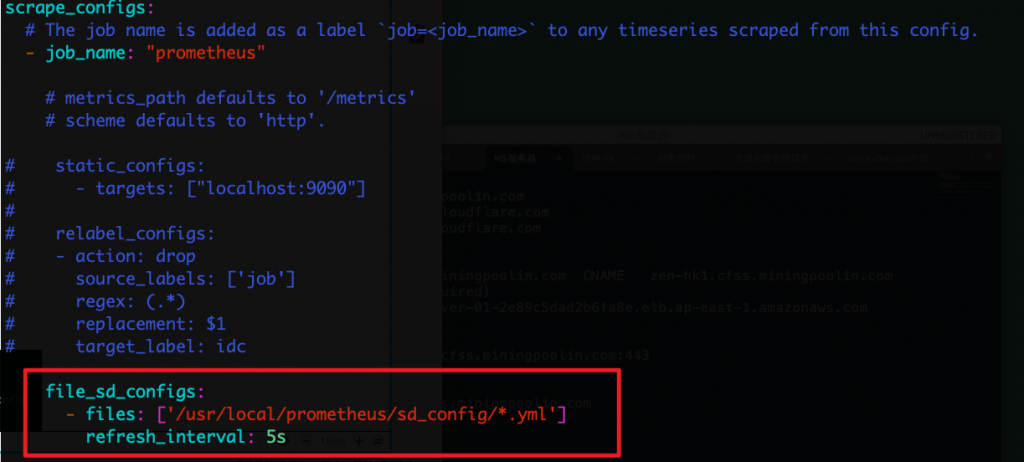
重启服务,监控节点消失:
mkdir -p /usr/local/prometheus/sd_config/
cd /usr/local/prometheus/sd_config/
vi /usr/local/prometheus/sd_config/prometheus1.yml
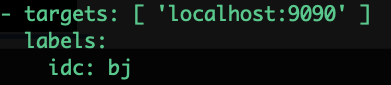
- targets: [ 'localhost:9090' ]
动态出现

动态添加标签:
vim prometheus1.yml

搭建expoter服务
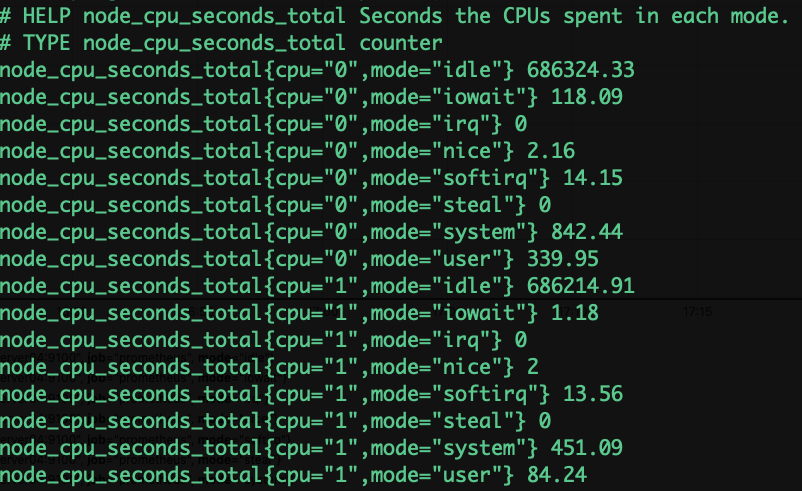
下载node exporter:
https://prometheus.io/download/#node_exporter
下载之后运行即可

使用systemctl后台管理:
vi /usr/lib/systemd/system/exporter.service
[Unit]
Description=https://prometheus.io/docs
[Service]
Restart=on-failure
ExecStart=/usr/local/prometheus/exporter/node_exporter/node_exporterl
[Install]
WantedBy=multi-user.target动态配置:
prometheus.yml 添加
- job_name: "node"
file_sd_configs:
- files: ['/usr/local/prometheus/sd_config/node.yml']
refresh_interval: 5s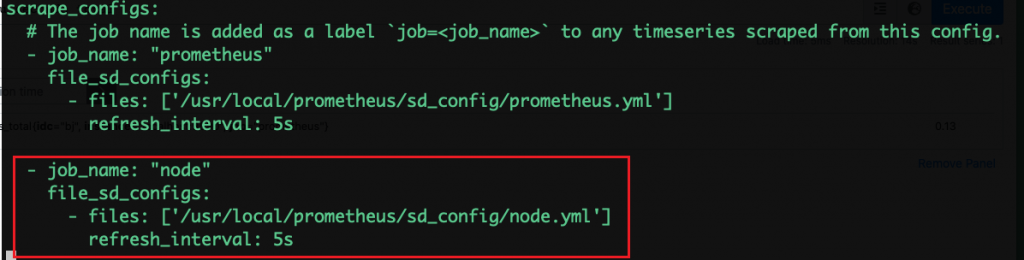
cd /usr/local/prometheus/sd_config
vi node.yml
- targets:
- 192.168.1.10:9100curl测试
curl localhost:9100/metrics
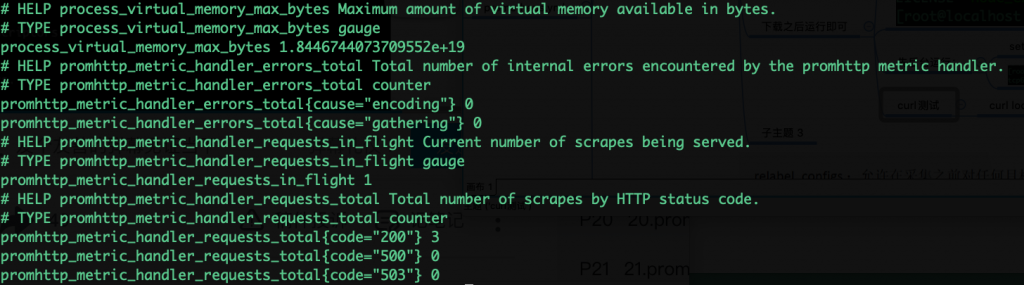
外部测试:
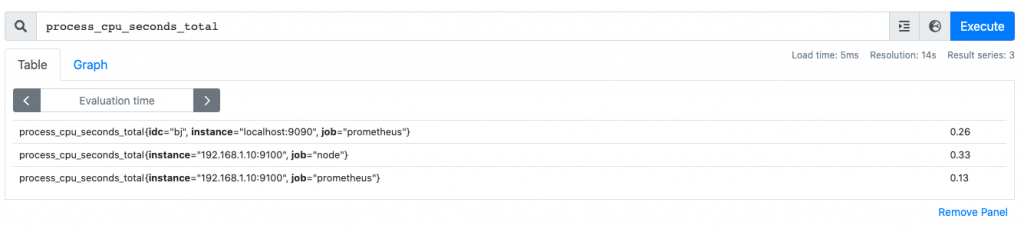
练习:监控cpu使用率



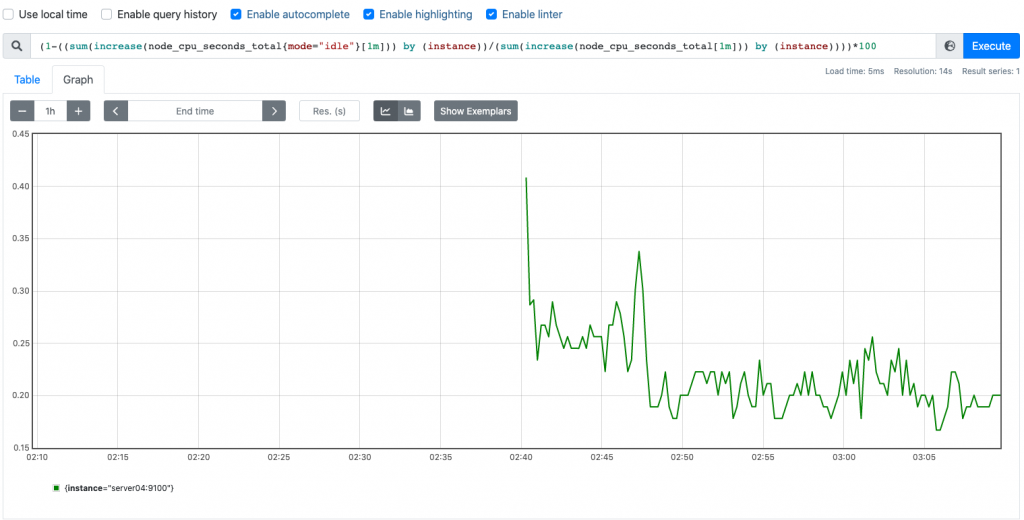
(1-((sum(increase(node_cpu_seconds_total{mode="idle"}[1m])) by (instance))/(sum(increase(node_cpu_seconds_total[1m])) by (instance))))*100
发布者:LJH,转发请注明出处:https://www.ljh.cool/7213.html