
DRBD简介
DRBD(distributed replicated block device分布式复制块设备)是一个基于软件实现的、无共享的、服务器之间镜像块设备内容的存储复制解决方案。DRBD是镜像块设备,是按数据位镜像成一样的数据块
DRBD可以部署在如下类的底层设备上
1、一个磁盘,或者是磁盘的某一个分区;
2、一个soft raid 设备;
3、一个LVM的逻辑卷;
4、一个EVMS(Enterprise Volume Management System,企业卷管理系统)的卷;
5、其他任何的块设备。
工作原理
DRBD需要运行在各个节点上,且是运行在节点主机的内核中,所以DRBD是内核模块,在Linux2.6.33版本起开始整合进内核。
DRBD+heartbeat工作原理
每个设备(drbd 提供了不止一个设备)都有一个状态,可能是‘主’状态或‘从’态。在主节点上,应用程序应能运行和访问drbd设备(/dev/drbd)。每次写入会发往本地磁盘设备和从节点设备中。从节点只能简单地把数据写入它的磁盘设上。 读取数据通常在本地进行。如果主节点发生故障,心跳(heartbeat或corosync)将会把从节点转换到主状态,并启动其上的应用程序。(如果您将它和无日志FS 一起使用,则需要运行fsck)。如果发生故障的节点恢复工作,它就会成为新的从节点,而且必须使自己的内容与主节点的内容保持同步
复制协议
协议A
异步复制协议。一旦本地磁盘写入已经完成,数据包已在发送队列中,则写被认为是完成的。在一个节点发生故障时,可能发生数据丢失,因为被写入到远程节点上的数据可能仍在发送队列。尽管,在故障转移节点上的数据是一致的,但没有及时更新。这通常是用于地理上分开的节点
协议B
内存同步(半同步)复制协议。一旦本地磁盘写入已完成且复制数据包达到了对等节点则认为写在主节点上被认为是完成的。数据丢失可能发生在参加的两个节点同时故障的情况下,因为在传输中的数据可能不会被提交到磁盘
协议C
同步复制协议。只有在本地和远程节点的磁盘已经确认了写操作完成,写才被认为完成。没有任何数据丢失,所以这是一个群集节点的流行模式,但I / O吞吐量依赖于网络带宽
一般使用协议C,但选择C协议将影响流量,从而影响网络时延。为了数据可靠性,我们在生产环境使用时须慎重选项使用哪一种协议
内核更新(可选知识点)
一些依赖于内核的软件需要先检查内核版本,如果版本不够需要升级版本
uname -r
cat /etc/redhat-release
升级内核
导入elrepo的key
rpm -import https://www.elrepo.org/RPM-GPG-KEY-elrepo.org ###key
安装elrepo的yum源
rpm -Uvh http://www.elrepo.org/elrepo-release-7.0-2.el7.elrepo.noarch.rpm ###yum源
查看可用的内核相关的包
yum --disablerepo="*" --enablerepo="elrepo-kernel" list available

安装内核
yum -y --enablerepo=elrepo-kernel install kernel-ml.x86_64 kernel-ml-devel.x86_64
修改grub中默认的内核版本
查看内核启动顺序
awk -F\' '$1=="menuentry " {print $2}' /etc/grub2.cfg
通过此命令可以看到新内核顺序为0
修改内核启动顺序为0
grub2-set-default 0
接着用命令来创建内核配置
grub2-mkconfig -o /boot/grub2/grub.cfg
重启查看变化
reboot
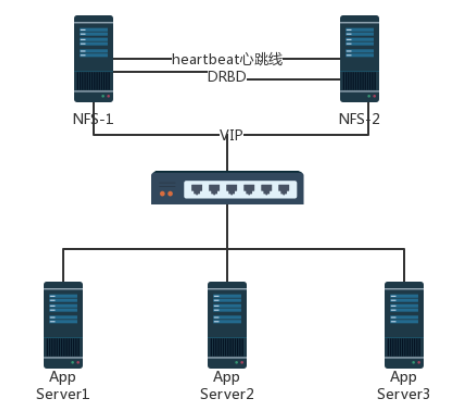
drbd+NFS+heartbeat搭建
实验环境:
db-server-a:192.168.1.10
db-server-b:192.168.1.11
DRBD磁盘
/dev/sdb1
VIP 192.168.1.100
拓扑图
实验流程
以下没有单独说,都是两端同时操作
修改主机名
a端
hostnamectl set-hostname db-server-a
bash
b端
hostnamectl set-hostname db-server-b
bash
添加一块硬盘划分区,但不创建文件系统
两端先添加一块硬盘
fdisk /dev/sdb
n 一直回车 最后w
ls /dev/sdb?

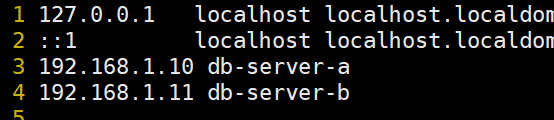
在hosts文件中添加主机映射关系
vim /etc/hosts
192.168.1.10 db-server-a
192.168.1.11 db-server-b
时间同步
在a上安装ntp服务
yum -y install ntp
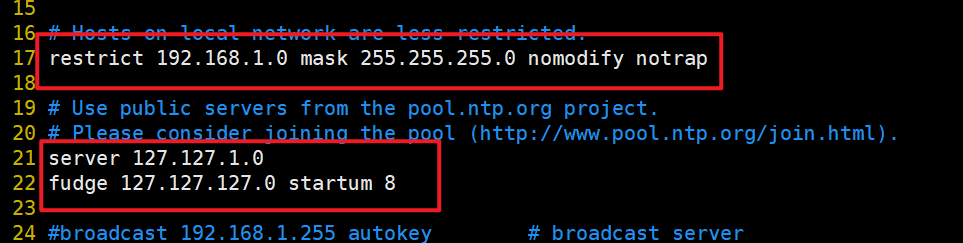
vim /etc/ntp.conf
restrict取消注释,修改成自己网段加入
server 127.127.1.0
fudge 127.127.127.0 startum 8
systemctl start ntpd
systemctl enable ntpd
b上
yum -y install ntpdate
ntpdate 192.168.1.10
crontab -e
* * * * * /usr/sbin/ntpdate 192.168.1.10 &>/dev/null
两个节点安装nfs服务,并共享/share目录(/dev/sdb1)
yum -y install nfs-utils rpcbind
mkdir /share
vim /etc/exports
/share 192.168.1.100/24(rw,sync,no_root_squash)
这个写VIP
systemctl start rpcbind
systemctl enable rpcbind
检测后记得关闭nfs,等会交给heartbeat处理
systemctl start nfs
exportfs

使用网络原将内核升级
先查看自己的版本
uname -r

备份本地源
mv /etc/yum.repos.d/local.repo /etc/yum.repos.d/local.bak
挂载阿里云网络源
curl -o /etc/yum.repos.d/CentOS-Base.repo https://mirrors.aliyun.com/repo/Centos-7.repo
sed -i -e '/mirrors.cloud.aliyuncs.com/d' -e '/mirrors.aliyuncs.com/d' /etc/yum.repos.d/CentOS-Base.repo
挂载阿里云epel源
yum -y install wget
wget -O /etc/yum.repos.d/epel.repo http://mirrors.aliyun.com/repo/epel-7.repo
yum clean all;yum makecache
下载新版内核
yum -y install kernel*
这个时间比较长,耐心等待就好
重启才能刷新内核
reboot
uname -r

可以看到内核版本更新了
安装drbd
yum install https://www.elrepo.org/elrepo-release-7.0-3.el7.elrepo.noarch.rpm -y
yum -y install drbd84-utils kmod-drbd84
modprobe drbd
lsmod |grep drbd

修改配置文件激活nfs资源
vim /etc/drbd.d/global_common.conf
global {
usage-count yes;
#是否参与DRBD使用者统计,默认为yes,yes or no都无所谓
}
common {
syncer { rate 30M; }
}
resource nfs {
#r0为资源名,我们在初始化磁盘的时候就可以使用资源名来初始化。
protocol C;
#使用 C 协议。
handlers {
pri-on-incon-degr "echo o > /proc/sysrq-trigger ; halt -f ";
pri-lost-after-sb "echo o > /proc/sysrq-trigger ; halt ";
local-io-error "echo o > /proc/sysrq-trigger ; halt -f";
fence-peer "/usr/lib4/heartbeat/drbd-peer-outdater -t 5";
pri-lost "echo pri-lst. Have a look at the log file.mail -s 'Drbd Alert' root";
split-brain "/usr/lib/drbd/notify-split-brain.sh root";
out-of-sync "/usr/lib/drbd/notify-out-of-sync.sh root";
}
net {
cram-hmac-alg "sha1";
shared-secret "MySQL-HA";
#drbd同步时使用的验证方式和密码信息
}
disk {
on-io-error detach;
fencing resource-only;
# 使用DOPD(drbd outdate-peer deamon)功能保证数据不同步的时候不进行切换。
}
startup {
wfc-timeout 120;
degr-wfc-timeout 120;
}
device /dev/drbd1;
#这里/dev/drbd1是用户挂载时的设备名字,由DRBD进程创建
on db-server-a {
#每个主机名的说明以on开头,后面是hostname(必须在/etc/hosts可解析)
disk /dev/sdb1;
#使用这个磁盘作为drbd的磁盘/dev/drbd0。
address 192.168.1.10:7788;
#设置DRBD的监听端口,用于与另一台主机通信
meta-disk internal;
#drbd的元数据存放方式
}
on db-server-b {
disk /dev/sdb1;
address 192.168.1.11:7788;
meta-disk internal;
}
}激活配置的DRBD资源nfs
drbdadm create-md nfs
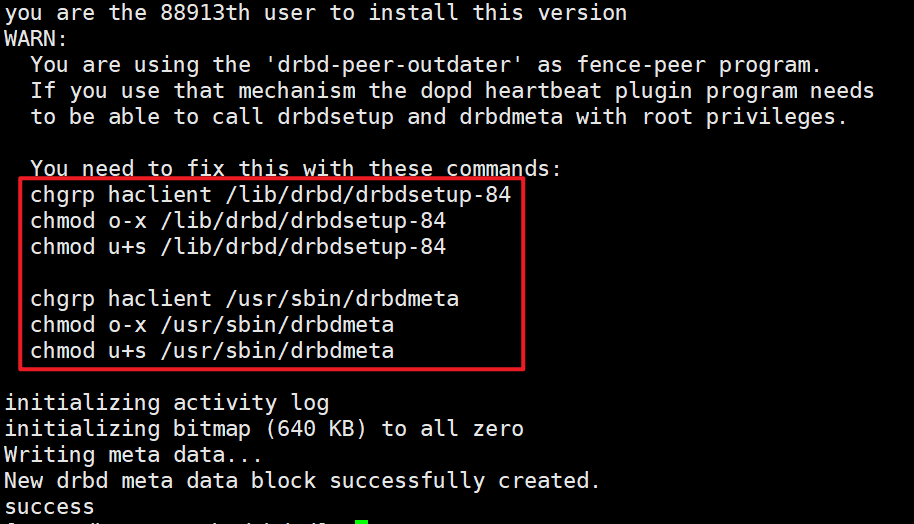
按照提示解决报错
groupadd haclient
chgrp haclient /lib/drbd/drbdsetup-84
chmod o-x /lib/drbd/drbdsetup-84
chmod u+s /lib/drbd/drbdsetup-84
chgrp haclient /usr/sbin/drbdmeta
chmod o-x /usr/sbin/drbdmeta
chmod u+s /usr/sbin/drbdmetasystemctl start drbd.service
systemctl enable drbd.service
server-a操作
设置a为默认主节点
drbdadm -- --overwrite-data-of-peer primary all
设置a为主
drbdadm primary --force nfs
查看a节点主从状态
drbdadm role nfs
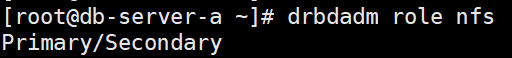
server-b查看状态
drbdadm role nfs

查看数据同步状态
drbdadm dstate nfs

挂载DRBD磁盘并测试同步
a上操作
mkfs.ext4 /dev/drbd1
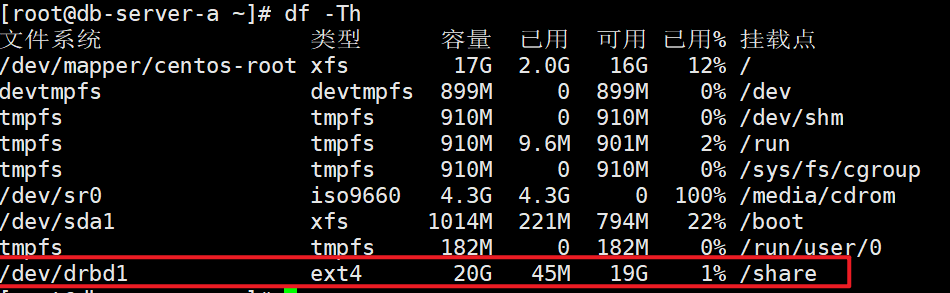
mount /dev/drbd1 /share
df -Th
echo 1111 >/share/a.txt
b上操作,主要是检测备端是否能够正常挂载和使用:
为了验证a/share目录中的文件可以同步到secondary从服务器上,需要把原来的primary降级为secondary,把原来的secondary升级primary(实际生产环境可以结合HA高可用集群来实现,下面为了测试,我们手动实现)
先操作a
先把a端取消挂载
umount /share
切换为备状态
drbdadm secondary all
drbdadm role nfs

再操作b
被设为主状态
drbdadm primary nfs
drbdadm role nfs

挂载b
mount /dev/drbd1 /share
df -Th
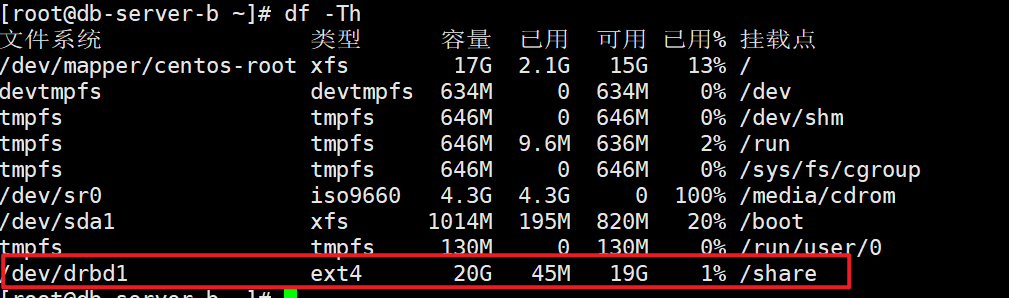
ls /share;cat /share/a.txt

最后再切回来
b端
umount /share
drbdadm secondary all
drbdadm role nfs

a端
drbdadm primary nfs
drbdadm role nfs

mount /dev/drbd1 /share
最后在检查一下
cat /proc/drbd

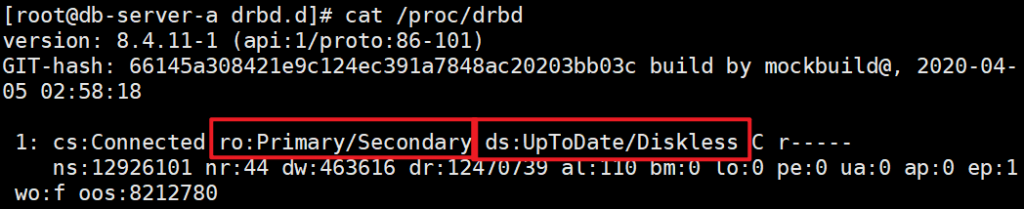
上面两幅图都是正确的状态,diskless这块显示UpToDate也没问题
df

部署heartbeat
centos6可以使用epel源安装,只需要输入这两条指令,centos7只能用源码包安装
rpm -vih http://dl.fedoraproject.org/pub/epel/6/x86_64/epel-release-6-8.noarch.rpm
yum -y install heartbeat heartbeat-devel heartbeat-stonith heartbeat-pils
生产环境中备份服务器之间一般进行免密操作:a端操作
ssh-keygen -q -t rsa -N '' -f ~/.ssh/id_rsa
ssh-copy-id root@db-server-b
两台机同时操作
去官网下载:http://www.linux-ha.org/wiki/Downloads
下载软件包:Reusable-Components-glue、resource-agents、heartbeat
放到家目录下

两端操作,安装依赖
yum install gcc gcc-c++ autoconf automake libtool glib2-devel libxml2-devel bzip2 bzip2-devel e2fsprogs-devel libxslt-devel libtool-ltdl-devel asciidoc -y
两端添加用户
groupadd haclient
useradd -g haclient hacluster
两台同时操作
安装glue这里包名字是:0a7add1d9996.tar.bz2,按照你下载的进行修改即可
tar xf 0a7add1d9996.tar.bz2
cd Reusable-Cluster-Components-glue--0a7add1d9996/
./autogen.sh
./configure --prefix=/usr/local/heartbeat --with-daemon-user=hacluster --with-daemon-group=haclient --enable-fatal-warnings=no LIBS='/lib64/libuuid.so.1'
make && make install
echo $?
cd ..安装Resource Agents(包名:resource-agents-3.9.6.tar.gz)
tar xf resource-agents-3.9.6.tar.gz
cd resource-agents-3.9.6/
./autogen.sh
./configure --prefix=/usr/local/heartbeat --with-daemon-user=hacluster --with-daemon-group=haclient --enable-fatal-warnings=no LIBS='/lib64/libuuid.so.1'
make && make install
echo $?
cd ..安装HeartBeat(包名:958e11be8686.tar.bz2)
tar xf 958e11be8686.tar.bz2
cd Heartbeat-3-0-958e11be8686/
./bootstrap
export CFLAGS="$CFLAGS -I/usr/local/heartbeat/include -L/usr/local/heartbeat/lib"
./configure --prefix=/usr/local/heartbeat --with-daemon-user=hacluster --with-daemon-group=haclient --enable-fatal-warnings=no LIBS='/lib64/libuuid.so.1'
make && make install
echo $?拷贝三个模版配置文件到 /usr/local/heartbeat/etc/ha.d 目录下 (三个文件分别是认证文件,主配置问文件,资源文件)
cd /usr/local/heartbeat/etc/ha.d/
cp /root/Heartbeat-3-0-958e11be8686/doc/{ha.cf,haresources,authkeys} /usr/local/heartbeat/etc/ha.d/
配置
chkconfig --add heartbeat
chkconfig heartbeat on
mkdir -pv /usr/local/heartbeat/usr/lib/ocf/lib/heartbeat/
cp /usr/lib/ocf/lib/heartbeat/ocf-* /usr/local/heartbeat/usr/lib/ocf/lib/heartbeat/
ln -sv /usr/local/heartbeat/lib64/heartbeat/plugins/* /usr/local/heartbeat/lib/heartbeat/plugins/两台机器创建库文件链接
ln -svf /usr/local/heartbeat/lib64/heartbeat/plugins/RAExec/* /usr/local/heartbeat/lib/heartbeat/plugins/RAExec/
ln -svf /usr/local/heartbeat/lib64/heartbeat/plugins/* /usr/local/heartbeat/lib/heartbeat/plugins/
修改主配置文件
vim /usr/local/heartbeat/etc/ha.d/ha.cf
debugfile /var/log/ha-debug
##用于记录heartbeat的调试信息
logfile /var/log/ha-log
#指定heartbeat日志文件的位置
logfacility local0
#设置heartbeat的日志,这里用的是系统日志
keepalive 2
# 心跳发送时间间隔
deadtime 10
# 备用节点10s内没有检测到master机的心跳,确认对方故障
warntime 5
#指定心跳延迟的时间为10秒,10秒内备节点不能接收主节点心跳信号, 即往日志写入警告日志,但不会切换服务
initdead 30
# 守护进程启动30s后,启动服务资源,取值至少为deadtime的两倍。
udpport 694
#设定集群节点间的通信协议及端口为udp694监听端口(该端口可以修改)
ucast ens33 192.168.1.11
# 另一台主机节点网卡的地址,注意是另一台。
auto_failback on
#当primary节点切换到secondary节点之后,primary节点恢复正常,进行切回操作,但是切换一次mysql master成本很高,一般为off。
node db-server-a
node db-server-b
# 定义两个节点的主机名,一行写一个。
ping 192.168.1.2
#两个IP的网关
respawn hacluster /usr/local/heartbeat/libexec/heartbeat/ipfail
#使用这个脚本去侦听对方是否还活着(使用的是ICMP报文检测)
apiauth ipfail gid=haclient uid=hacluster
##设置启动IPfail的用户和组Bcast、ucast和mcast分别代表广播、单播和多播,是组织心跳的的方式,任选其一
配置haresources配置文件
Haresources文件用于指定双机系统的主节点、集群IP、子网掩码、广播地址及启动服务集群资源,文件每一行可包含一个或多个资源脚本名,资源间使用空格隔开,参数间使用两个冒号隔开,主节点和备份节点中资源文件haresources要完全一样,resource-group用于指定需Heartbeat托管的服务(即这些服务可由Heartbeat来启动和关闭)。如要托管这些服务,必须将服务写成可通过start/stop来启动或关闭的脚本,放到/etc/init.d/或/etc/ha.d/resource.d/目录下,Heartbeat会根据脚本名称自动去/etc/init.d或者/etc/ha.d/resource.d目录下找到相应脚本进行启动或关闭操作。
vim /usr/local/heartbeat/etc/ha.d/haresources
末尾添加如下
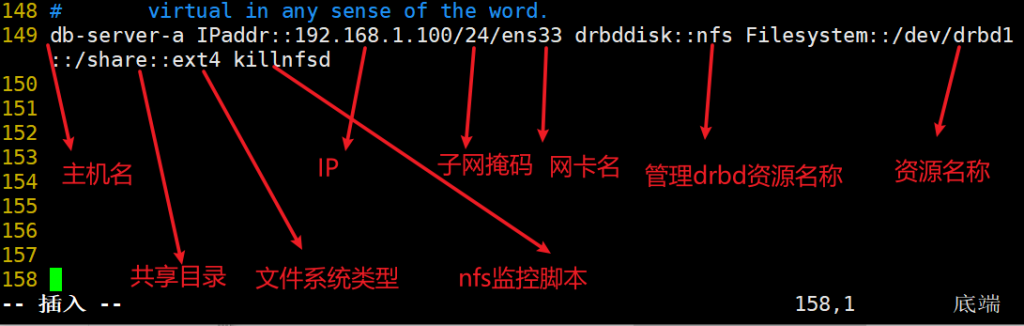
注:db-server-a是主服务器的主机名, db-server-b主机上不需要修改。这样资源默认会加a这个主机上。当a坏了,b会再接管。
添加脚本
cp /etc/ha.d/resource.d/drbddisk /usr/local/heartbeat/etc/ha.d/resource.d/
yum -y install psmisc
echo "pkill -9 nfs; systemctl restart nfs; exit 0" > /usr/local/heartbeat/etc/ha.d/resource.d/killnfsd脚本介绍
编辑nfs脚本文件killnfsd ,killnfsd 脚本文件的作用:
drbd主备切换时,若nfs没有启动,则此脚本会把nfs启动
drbd主备切换时,若nfs已启动,则此脚本会重启nfs服务,因为NFS服务切换后,必须重新mount一下nfs共享出来的目录,否则会出现stale NFS file handle的错误
添加执行权限
chmod +x /usr/local/heartbeat/etc/ha.d/resource.d/drbddisk
chmod +x /usr/local/heartbeat/etc/ha.d/resource.d/killnfsd
查看配置目录
cd /usr/local/heartbeat/etc/ha.d/resource.d/
ll drbddisk Filesystem killnfsd IPaddr

配置authkeys认证文件
vim /usr/local/heartbeat/etc/ha.d/authkeys
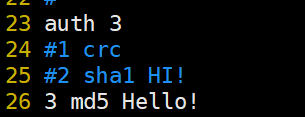
该权限必须为600
chmod 600 /usr/local/heartbeat/etc/ha.d/authkeys
测试部分
测试vip漂移
systemctl enable heartbeat
systemctl start heartbeat
主服务器VIP出现
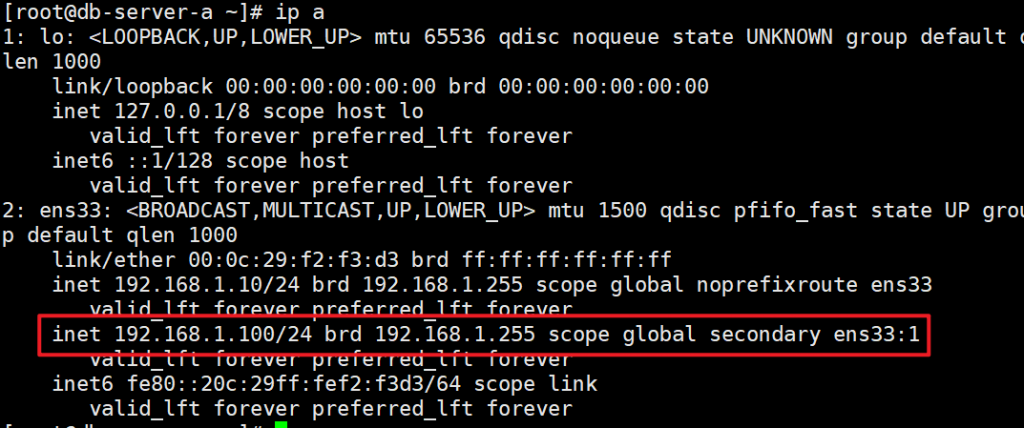
systemctl stop heartbeat
vip漂移到了另外一台服务器
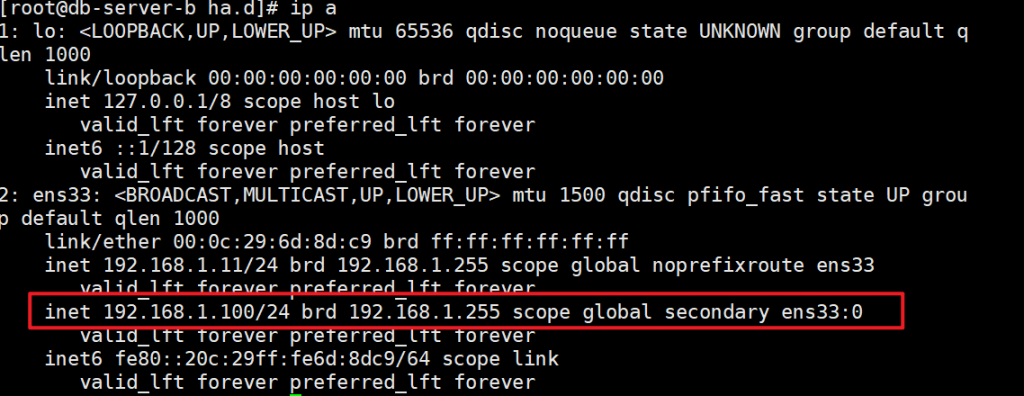
测试nfs自动挂载
showmount -e 192.168.1.100

关闭heartbeat
systemctl stop heartbeat.service
关闭nfs
systectl stop nfs
开启heartbeat,nfs也自动开启
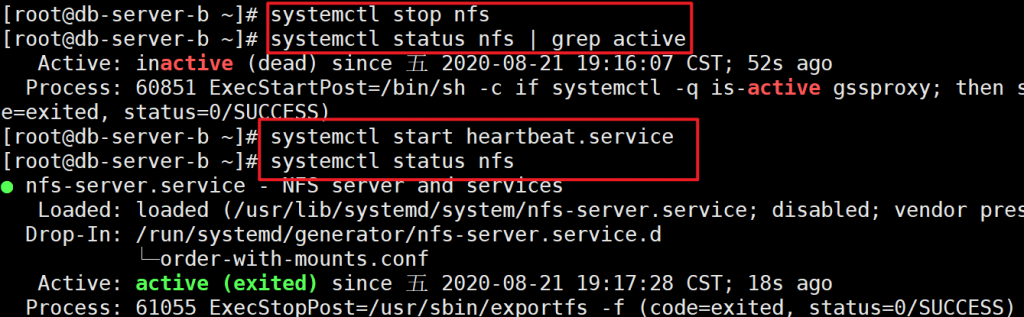
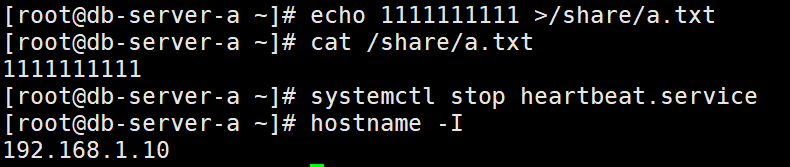
测试自动备份
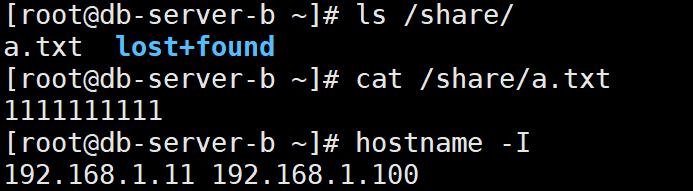
a端加入一个文件到/share,然后关闭heartbeat
b端vip成功漂移过来,而且成功接收到a.txt
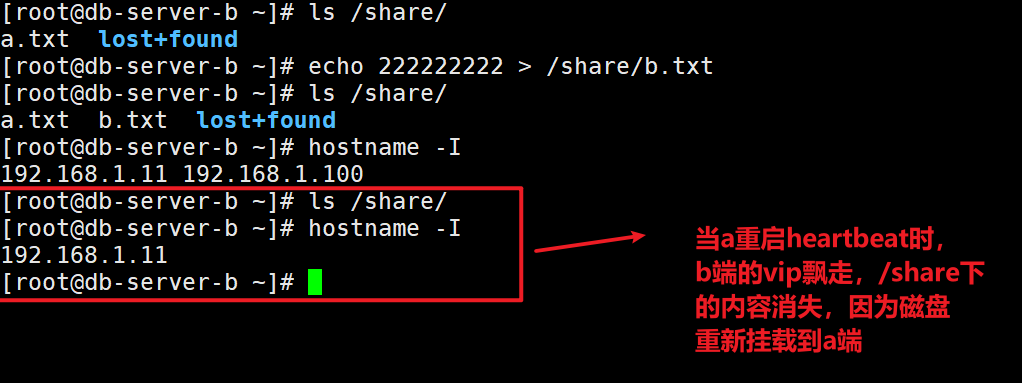
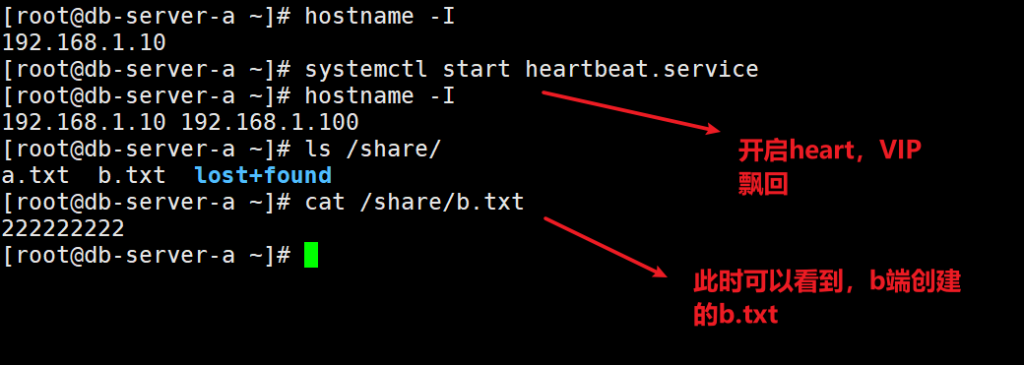
测试VIP飘回
b端先在共享目录创建一个b.txt(此时VIP在b端),然后开启a端的heartbeat服务,可以在a端的/share看到在b端创建的内容
编写nfs宕机会自动关闭heartbeat脚本
vim heartbeat-nfs.sh
#!/bin/bash
while true
do
drbdstatus=`cat /proc/drbd 2> /dev/null | grep ro | tail -n1 | awk -F':' '{print $4}' | awk -F'/' '{print $1}'`
#获取一下drdb的状态
nfsstatus=`systemctl status nfs&>/dev/null ; echo $?`
#获取一下nfs状态,如果正常,值为0
if [ -z $drbdstatus ];then
sleep 10
continue
#如果drbd状态正常,继续下一轮检测
elif [ $drbdstatus == 'Primary' ];then
if [ $nfsstatus -ne 0 ];then
systemctl start nfs &> /dev/null
#如果drdb是主节点,而且drdb未开启,尝试开启nfs
newnfsstatus=`systemctl status nfs&>/dev/null ; echo $?`
#再次检测nfs状态,新的状态赋值为返回的状态码
if [ $newnfsstatus -ne 0 ];then
systemctl stop heartbeat
#尝试开启之后若还是不行,则关掉heartbeat
fi
fi
fi
sleep 5
done两端持续执行即可
遇到的报错(这一部分可以忽略)
内核版本不够
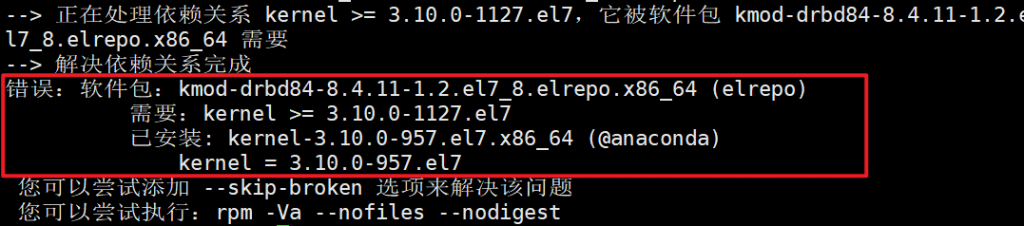
解决方法,使用网络源下载新版本内核
curl -o /etc/yum.repos.d/CentOS-Base.repo https://mirrors.aliyun.com/repo/Centos-7.repo
yum clean all
yum makecache
yum -y install kernel*
reboot
uname -r

如果需要自定义内核版本看“内核更新(可选知识点)”部分
没有主从切换

删除原有的磁盘分区,重新创建磁盘分区
没有配置hosts或者是密钥认证
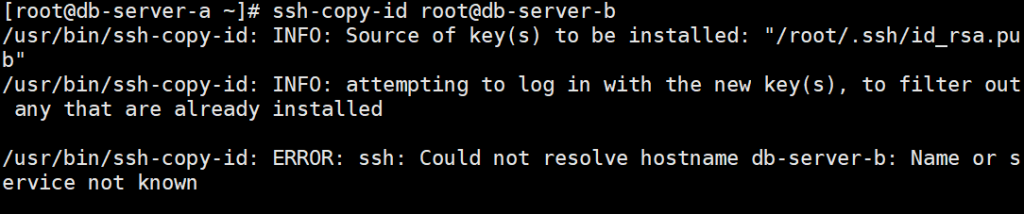
解决:vim /etc/hosts ,里面两台主机名和IP都要匹配
发布者:LJH,转发请注明出处:https://www.ljh.cool/6130.html