


正则表达式与通配符的区别
正则表达式(Regular Expression)用来在文件中匹配符合条件的字符串(常用命令grep 、awk、sed),通配符用来匹配符合条件的文件名(常用的命令find、ls、cp)
基础正则 grep sed awk -> 扩展正则 egrep 、sed -r、awk
正则表达式
基础正则元字符:
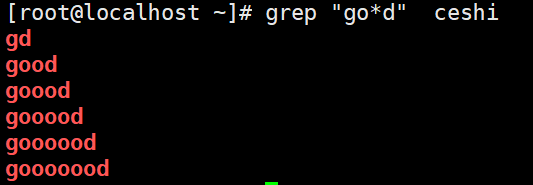
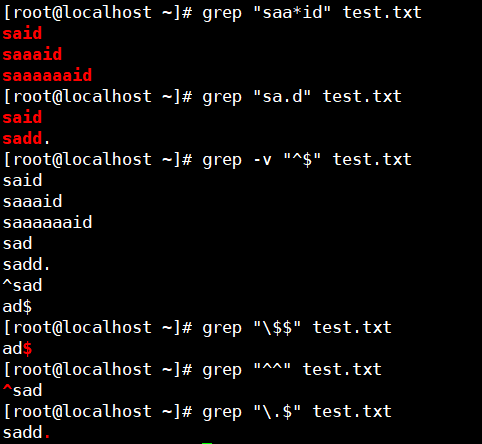
* 匹配前一个字符0次或任意多次
. 匹配除了换行符外任意一字符
^ 匹配行首
$ 匹配行尾
^$ 匹配空行(行首行尾啥都没有,一般与-v配合)
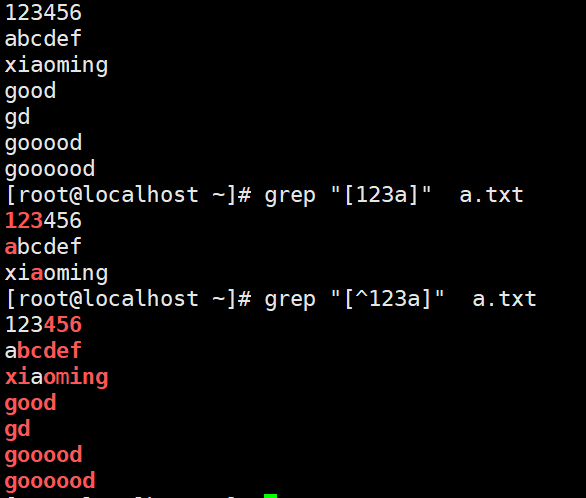
[] 匹配括号中任意一个字符示例:
\转义符,用于取消特殊符号的含义
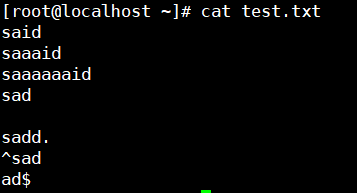
例子:匹配以“.”结尾的行 grep ".$"(此时.有其原先的含义但被转义符变为普通字符)
[]匹配括号中任意一个字符,[0-9]为匹配任意一个数字,[A-Za-z]为匹配任意一个字母 [a-z][0-9]意为匹配小写字和一位数字构成的两位字符 [0-9a-zA-Z]为匹配任意大小写字母和数字
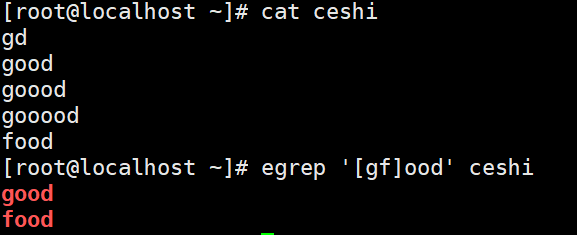

基础正则匹配前一个字符出现次数范围时大括号前要加转义符(在扩展正则中不需要反斜杠,建议使用扩展正则)
\{n\} 表示其前面的字符恰好出现n次,例如[0-9]\{4\} 匹配4位数字,[1][2-8][0-9]\{9\}匹配手机号码
\{n,\} 表示其前面的字符出现不小于n次,例如[0-9]\{2,\}表示2位及以上数字
\{n,m\} 表示其前面字符至少出现n次,最多出现m次,例如[a-z]\{6,8\}匹配6-8位的小写字母
\{,m\} 匹配前一个字符字符最多出现m次扩展正则:
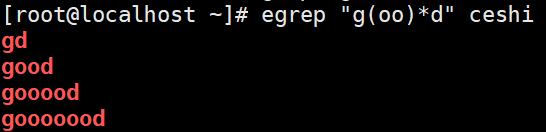
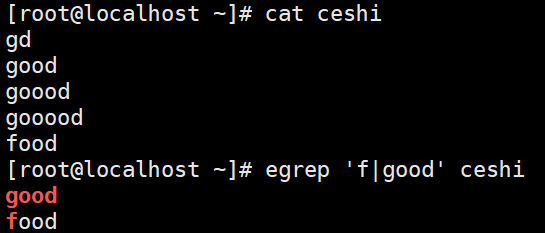
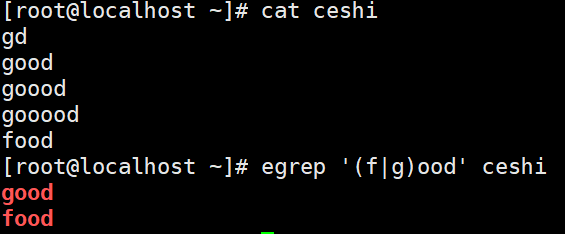
+ 前一个字符匹配一次或任意多次
?匹配前一个字符0次或1次【?* +范围依次向右】
()分组,匹配其整体为一个字符,及模式单元,可以理解为由多个单个字符组成的大字符
| 匹配两个或多分支选择,例如(dog)会匹配dog dogdog dogdogdog,但hello(cat|dog)会匹配hello cat及hello dog
当然扩展正则中也包括{n} {n,m} {n,} {,m}示例:
下面这个案例作为总体的练习:
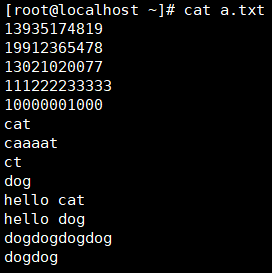

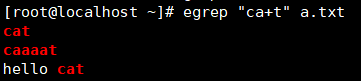
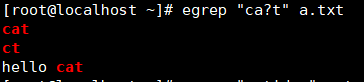
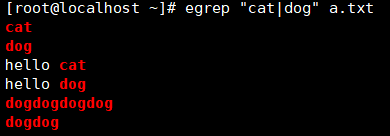
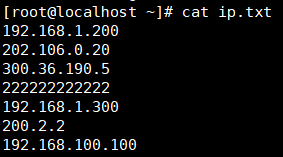
练习:匹配邮箱和精准的IP地址
匹配邮箱:
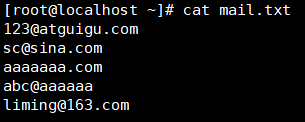

过滤IP:
思路:多种限制情况
| 百位 | 十位 | 个位 |
| 0 | 0-9 | 0-9 |
| 1 | 0-9 | 0-9 |
| 2 | 0-4 | 0-9 |
| 3 | 5 | 0-5 |

发布者:LJH,转发请注明出处:https://www.ljh.cool/5450.html