
使用 python 统计列表中的元素出现次数,按升序排序输出
def count_and_sort(lst):
# 创建一个字典来存储每个元素出现的次数
count_dict = {}
# 统计每个元素的出现次数
for item in lst:
if item in count_dict:
count_dict[item] += 1
else:
count_dict[item] = 1
# 将字典转换为一个列表,其中每个元素是一个元组(元素, 出现次数)
count_list = [(item, count) for item, count in count_dict.items()]
# 按出现次数对列表进行排序
count_list.sort(key=lambda x: x[1])
return count_list
# 示例列表
lst = ['apple', 'banana', 'apple', 'orange', 'banana', 'apple', 'pear', 'orange', 'banana', 'banana']
# 调用函数并打印结果
sorted_counts = count_and_sort(lst)
for item, count in sorted_counts:
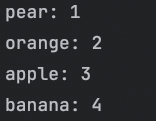
print(f'{item}: {count}')

详细讲解:
知识点一: 统计元素出现次数
for item in lst:
if item in count_dict:
count_dict[item] += 1
else:
count_dict[item] = 1- 循环遍历(for loop): 使用
for item in lst:循环遍历列表lst中的每个元素。 - 检查元素是否在字典中:
if item in count_dict:检查当前元素item是否已经在count_dict字典中。- 如果在字典中,说明该元素之前已经出现过,此时就将字典中对应的值(计数)加 1:
count_dict[item] += 1。 - 如果不在字典中,说明这是该元素第一次出现,此时将其添加到字典并将计数初始化为 1:
count_dict[item] = 1。
通过这个循环,最终 count_dict 字典就会包含列表中每个元素的出现次数。例如,对于示例列表,count_dict 可能会变成:
{
'apple': 3,
'banana': 4,
'orange': 2,
'pear': 1
}知识点二:转换字典为列表
字典遍历的方式:将每个元素(键值对)打包成一个元祖 items()
=> 完整格式
# 创建一个空列表
count_list = []
# 遍历字典的键值对
for item,count in count_dict.items(): # 解包思想
# 将每个键值对打包成元组并添加到计数列表中
count_list.append((item,count))count_list = [(item, count) for item, count in count_dict.items()]这行代码使用了一个列表推导式(list comprehension)将 count_dict 字典中的内容转换为一个列表 count_list。这个列表中的每个元素都是一个元组 (item, count),其中 item 是元素,count 是其出现次数。
通过 count_dict.items() 方法,我们可以获取字典中所有的键值对。这一行代码将会生成一个如下的列表:
[
('apple', 3),
('banana', 4),
('orange', 2),
('pear', 1)
]知识点三:排序+lambda 函数(两种组合常用,这里尽量记住)
count_list.sort(key=lambda x: x[1])count_list.sort(...)方法会就地排序count_list列表。key=lambda x: x[1]表示排序的依据是每个元组的第二个元素(即出现次数count)。lambda x: x[1]是一个匿名函数,输入每个元组x,输出元组的第二个元素。
经过这一步,count_list 列表就会按出现次数升序排列。对于示例列表,排序后可能是:
[
('pear', 1),
('orange', 2),
('apple', 3),
('banana', 4)
]有四个数字:1、2、3、4,能组成多少个互不相同且无重复数字的三位数?各是多少?请用 python 写出
numbers = [1, 2, 3, 4]
unique_numbers = []
for i in numbers:
for j in numbers:
for k in numbers:
if i != j and j != k and i != k:
num = i * 100 + j * 10 + k
unique_numbers.append(num)
print("可以组成的三位数数量:", len(unique_numbers))
print("这些三位数是:", unique_numbers)
这段代码通过三个嵌套循环,遍历所有可能的组合,并确保每个数字在每种组合中都是唯一的。最终,它会输出所有符合条件的三位数以及它们的数量。运行这段代码,将会看到12个不重复的三位数。

求出100以内的所有质数(只能被1和本身除尽的数)
我们定义了一个 is_prime 函数来判断一个数字是否为质数。然后,我们使用列表推导式找出 2 到 100 之间的所有质数,并将它们存储在 prime_numbers 列表中。最后打印出这些质数。
def is_prime(num):
if num <= 1:
return False
for i in range(2, int(num ** 0.5) + 1):
if num % i == 0:
return False
return True
prime_numbers = [num for num in range(2, 101) if is_prime(num)]
print(prime_numbers)
在这里,我们定义了一个 is_prime 函数来判断一个数字是否为质数。然后,我们使用列表推导式找出 2 到 100 之间的所有质数,并将它们存储在 prime_numbers 列表中。最后打印出这些质数。
运行结果:

求出所有三位数中的水仙花数(水仙花数: 首先是一个三位数,其每一位上的数字的立方和等于该数字本身。例: 153 = 1 + 125 + 27)
# 水仙花数示例
def find_narcissistic_numbers():
# 创建一个列表用于存储水仙花数
narcissistic_numbers = []
# 遍历所有三位数
for number in range(100, 1000):
# 将数字划分为百位、十位和个位
hundreds_digit = number // 100
tens_digit = (number // 10) % 10
units_digit = number % 10
# 计算各个位数字的立方和
sum_of_cubes = hundreds_digit**3 + tens_digit**3 + units_digit**3
# 如果立方和等于原数,则认定为水仙花数
if sum_of_cubes == number:
narcissistic_numbers.append(number)
return narcissistic_numbers
# 打印输出所有三位数的水仙花数
narcissistic_numbers = find_narcissistic_numbers()
print("三位数中的水仙花数有:", narcissistic_numbers)

使用 python 实现输入若干数字,当输入quit时退出输入,计算输入数字中的最大值,最小值,总和,平均值
代码说明
- 输入循环:程序在无限循环中持续接收用户输入。
- 退出机制:当用户输入 "quit" 时,退出输入循环。
- 输入处理:尝试将输入转换为浮点数,如果失败(即输入的不是数字),则提示用户输入有效的数字,并继续下次循环。
- 计算结果:在用户输入数字后,如果列表
numbers中有数据,则计算并打印最大值、最小值、总和和平均值。 - 边界处理:如果用户没有输入任何数字而直接退出,则显示一条信息告知没有输入数据。
def main():
numbers = [] # 用于存储用户输入的数字
while True:
user_input = input("请输入一个数字(输入 'quit' 退出):")
if user_input.lower() == 'quit':
break # 退出循环
try:
number = float(user_input) # 将输入转换为浮点数
numbers.append(number) # 将数字添加到列表中
except ValueError:
print("请输入一个有效的数字!")
continue
if numbers:
max_value = max(numbers)
min_value = min(numbers)
total_sum = sum(numbers)
average = total_sum / len(numbers)
print(f"最大值:{max_value}")
print(f"最小值:{min_value}")
print(f"总和:{total_sum}")
print(f"平均值:{average}")
else:
print("没有输入任何数字。")
if __name__ == "__main__":
main()
使用 python 实现: 输入两个数字 a, b 求s=a+aa+aaa+aaaa+aa...a的值 ,有b个这样的项,然后将它们相加。例如输入 2, 5 输出结果 2+22+222+2222+22222 = 24690(此时共有5个数相加)
我们使用一个循环来反复构建每一个项。每次迭代,我们将数字 a 转换为字符串并附加到 current_number 中,然后转换回整数并加到 total_sum。这样就可以获得所需的序列和。
def compute_sum(a, b):
total_sum = 0
current_number = ""
for _ in range(b):
current_number += str(a) # 构建当前的数
total_sum += int(current_number) # 将当前的数转换为整数并累加到总和中
return total_sum
# 示例用法
a = 2
b = 5
result = compute_sum(a, b)
print(result) # 输出: 24690
python 实现 自定义实现 int(),将一个数字字符串转换成真正的数字,并返回
要自定义实现 int() 函数,将一个数字字符串转换为整数,可以手动解析字符串中的每个字符,将其转换为对应的数字,然后根据其位置计算结果。
def custom_int(s):
# 检查是否为空字符串
if not s:
raise ValueError("输入字符串为空")
# 设定初始值
num = 0
# 用来标识符号
is_negative = False
# 处理负号
start_index = 0
if s[0] == '-':
is_negative = True
start_index = 1
# 构建数字
for i in range(start_index, len(s)):
char = s[i]
# 检查字符是否为数字
if '0' <= char <= '9':
digit = ord(char) - ord('0')
num = num * 10 + digit
else:
raise ValueError(f"无效字符: {char}")
if is_negative:
num = -num
return num
# 示例用法
try:
print(custom_int("123")) # 输出: 123
print(custom_int("-456")) # 输出: -456
print(custom_int("0")) # 输出: 0
print(custom_int("00012")) # 输出: 12
except ValueError as e:
print(e)
现有 姓氏 和 名字 若干,设计函数得到一个随机的名字
示例数据:
# 示例数据
surnames = ["张", "李", "王", "刘", "陈"]
given_names = ["伟", "娜", "敏", "静", "磊"]要生成一个随机的名字,你可以使用 Python 的 random 模块。假设你有两个列表:一个包含不同的姓氏,另一个包含不同的名字。你可以编写一个函数来随机选择一个姓氏和一个名字,然后将它们组合成一个完整的名字。以下是示例代码:
import random
def generate_random_name(surnames, given_names):
"""
从给定的姓氏和名字列表中随机生成一个名字。
:param surnames: 包含多个姓氏的列表
:param given_names: 包含多个名字的列表
:return: 随机生成的名字(姓氏和名字组合)
"""
# 从姓氏列表中随机选择一个
surname = random.choice(surnames)
# 从名字列表中随机选择一个
given_name = random.choice(given_names)
# 返回组合后的全名
return f"{surname}{given_name}"
# 示例数据
surnames = ["张", "李", "王", "刘", "陈"]
given_names = ["伟", "娜", "敏", "静", "磊"]
# 生成一个随机名字
random_name = generate_random_name(surnames, given_names)
print(random_name)
说明:
- random.choice(): 该函数从提供的列表中随机返回一个元素。在这个例子中,它用于从姓氏和名字列表中分别选择一个随机项。
- 字符串格式化: 使用简单的字符串拼接 (
f"{surname}{given_name}") 来生成完整的名字。
使用 python 实现:利用随机数得到一个随机的字母和数字组成的四位验证码,然后输入看到的验证码,如果输入正确结束程序,输入错误持续输入直到正确为止。如果输入三次不正确,更换验证码后继续
import random
import string
def generate_verification_code():
"""生成一个四位由字母和数字组成的验证码"""
all_chars = string.ascii_letters + string.digits
return ''.join(random.choice(all_chars) for _ in range(4))
def input_with_prompt(prompt):
"""提示用户输入,并返回其输入的字符串"""
return input(prompt)
def verification_process():
"""进行验证码验证的主要流程"""
attempts = 0 # 当前错误次数
max_attempts = 3 # 每验证码允许输入错误的最大次数
code = generate_verification_code() # 生成初始验证码
print(f"验证码是: {code}")
while True:
user_input = input_with_prompt("请输入验证码: ")
if user_input == code:
print("验证码正确,程序结束!")
break
else:
attempts += 1
print("验证码错误!")
if attempts >= max_attempts:
code = generate_verification_code() # 更换新的验证码
print(f"验证码错误次数过多,生成新的验证码: {code}")
attempts = 0 # 重置错误次数
# 运行验证过程
verification_process()
代码说明:
- generate_verification_code(): 生成一个四位随机的验证码,该验证码由字母和数字组成。
- input_with_prompt(): 提示用户输入,并返回输入的字符串。这样可以将用户输入的逻辑独立出来,便于后续扩展。
- verification_process(): 验证码验证的主要流程。它初始化错误次数,并在每次用户输入时检查其是否正确。若正确,程序结束;若连续三次错误,更换新的验证码并继续,直到用户输入正确为止。
运行示例:
- 生成初始验证码并提示用户输入。
- 如果用户输入正确,打印“验证码正确,程序结束!”并结束程序。
- 如果用户输入错误,增加错误计数并提示“验证码错误!”。
- 如果错误计数达到三次,生成新的验证码并重置错误计数,继续提示用户输入新验证码。
使用 python求出所有字符串的最小前缀
def find_smallest_common_prefix(strs):
if not strs:
return ""
# 假设第一个字符串的全部是最小公共前缀
prefix = strs[0]
# 逐个比较其他字符串
for s in strs[1:]:
# 缩短 prefix 直到它适合当前字符串
while not s.startswith(prefix):
prefix = prefix[:-1]
if not prefix:
return ""
return prefix
# 示例用法
strings = ["flower", "flow", "flight"]
result = find_smallest_common_prefix(strings)
print(f"最小公共前缀是: '{result}'")
代码说明:
- 初始条件:首先检查输入的字符串列表是否为空。如果为空,直接返回空字符串。
- 初始前缀:假设第一个字符串的全部是最小公共前缀。
- 逐步缩短:使用
startswith()检查当前前缀是否是其他字符串的前缀。若不是,则逐个缩短前缀,直到找到一个共同前缀,或者前缀变为空。 - 返回结果:一旦找出最小公共前缀,就返回它。如果找不到任何公共前缀,返回空字符串。
使用 python 按从高到低的顺序统计文章text中所有单词的使用频率
我们可以使用基本的 Python 数据结构(如字典)来统计每个单词的频率,然后对结果进行排序。
import re
def count_word_frequency(text):
# 移除标点符号,并将文本转换为小写
cleaned_text = re.sub(r'[^\w\s]', '', text).lower()
# 拆分文本为单词列表
words = cleaned_text.split()
# 使用字典统计单词频率
word_count = {}
for word in words:
if word in word_count:
word_count[word] += 1
else:
word_count[word] = 1
# 根据频率排序
sorted_word_count = sorted(word_count.items(), key=lambda item: item[1], reverse=True)
return sorted_word_count
# 示例文本
text = """
Python is an interpreted, high-level, general-purpose programming language.
Created by Guido van Rossum and first released in 1991, Python has a design philosophy that emphasizes code readability, notably using significant whitespace.
It provides constructs that enable clear programming on both small and large scales.
"""
# 统计词频
word_frequency = count_word_frequency(text)
# 打印结果
for word, freq in word_frequency:
print(f"{word}: {freq}")
代码说明:
- 正则表达式 (
re):用于去掉所有非字母数字的字符,让文本只保留单词字符和空白符。 - 字典 (
dict):用于存储每个单词及其对应的出现次数。 - 字典填充:遍历单词列表时,对每个单词在字典中进行计数。
- 排序:使用列表的
sorted()函数对字典的项按频率排序,key=lambda item: item[1]表示按频率排序,reverse=True用于从高到低排序。
发布者:LJH,转发请注明出处:https://www.ljh.cool/42175.html