
函数返回多个值
需求:求一个列表数据中的最大值和最小值
def get_max_min():
cl = [1,0,3,5,2,6,8,7,4,9]
ma = max(cl)
mi = min(cl)
print(ma,mi)
# 解释器在执行代码时,发现return 后成如果有多个值 ,那么就会将这多个值 ,直接组包成一个元组
# 然后将这个元组返回。
return ma,mi
ret = get_max_min()
# ret = ma, mi -> ret = (ma, mi) 这个实质就是组包过程
print(ret)
print(type(ret))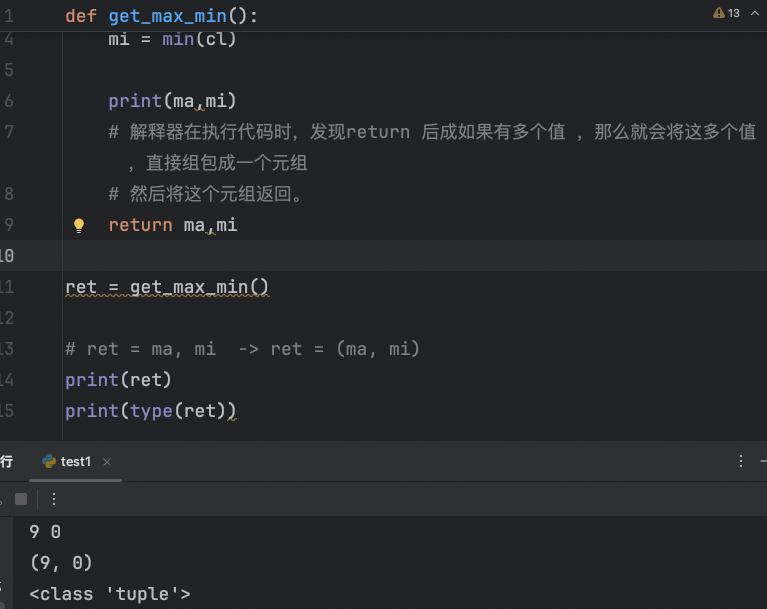

函数嵌套调用
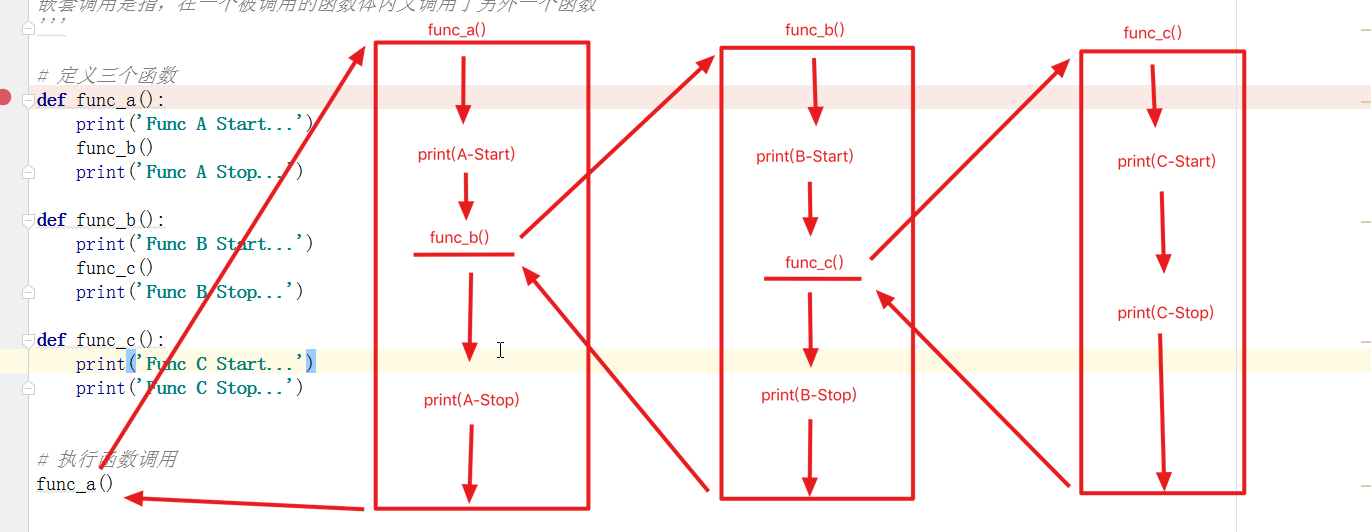
嵌套调用是指在一个被调用的函数体内又调用了另外一个函数
强调一遍调用过程:
- 函数定义:在调用函数之前,该函数必须先被定义。函数的定义包括函数名、参数列表(如果有的话)、以及函数体(代码块)。
- 函数调用:函数通过其名字以及一对圆括号进行调用。如果函数需要参数,则在括号中传入相应的值。
- 参数传递:在函数调用时,传入的实参被赋值给函数定义中的形参。Python 支持多种参数传递方式,包括位置参数、关键字参数、默认参数、以及可变参数(*args 和 **kwargs)。
- 执行函数体:函数被调用时,程序控制流进入函数内部,执行函数体中的语句。执行顺序是自上而下,逐行执行。
- 返回值:使用
return语句将结果传回给调用者。如果没有return语句,函数会在执行完毕后返回None。 - 继续执行调用者的代码:函数执行完并返回结果后,程序控制流返回到函数调用的位置,继续执行后续代码。
# 定义三个函数
def func_a():
print('Func A Start...')
func_b()
print('Func A Stop...')
def func_b():
print('Func B Start...')
func_c()
print('Func B Stop...')
def func_c():
print('Func C Start...')
print('Func C Stop...')
# 执行函数调用
func_a()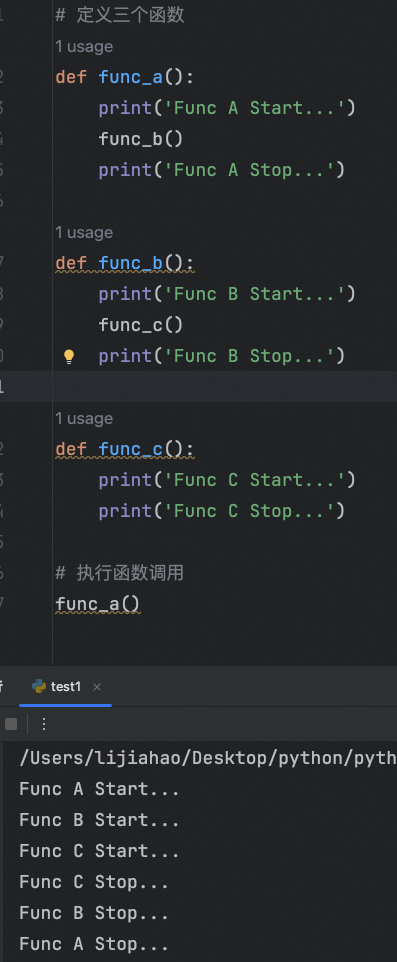
调用过程
函数递归调用
函数在函数体内又调用了自己,这种形式就是递归调用,为了避免死循环,一般会有递归结束条件
自己调用自己会出现死循环
求阶乘
5! = 1 * 2 *3 * 4 * 5
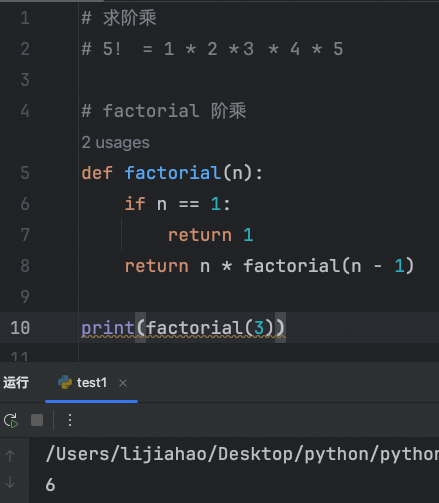
返回过程:
factorial(5) -> 5 * factorial(4) -> reutrn 5 * 24 -> 120
-> 4 * factorial(3) -> return 4 * 6
-> 3 * factorial(2) -> reutrn 3 * 2
-> 2 * factorial(1) -> return 2 * 1
-> return 1变量作用域
全局变量和局部变量
作用域:局部变量的作用域仅限于定义它们的函数或代码块内。它们在函数或块的执行过程中是可见和可访问的,离开该作用域后就不可见了。
- 优点:提供更高的代码安全性,因为局部变量只能在限定范围内访问,减少了意外修改的风险。此外,它们帮助保持代码的可读性和模块化。
- 缺点:如果需要在多个函数之间共享数据,则无法使用局部变量。
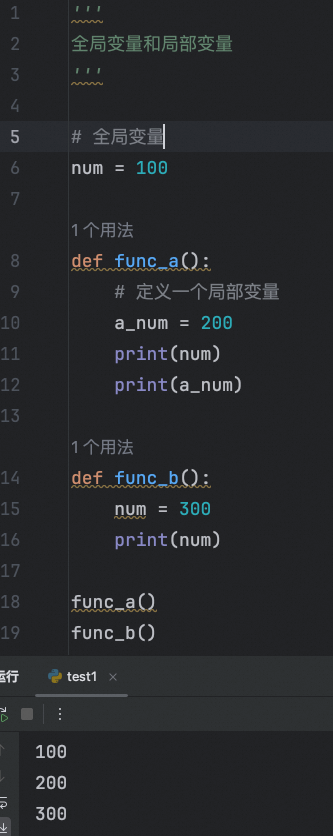
现在局部变量找,然后才会去全局变量找
# 变量查找规则
# LEGB
# Local -> EnClosed -> Global -> Buildins
# 本地 -> 闭包 -> 全局 -> 内建
首先查找局部作用域,然后是嵌套作用域,再是全局作用域,最后是内置作用域。示例:
x = 10 # Global variable
def outer():
x = 20 # Enclosed variable
def inner():
x = 30 # Local variable
print(x) # Outputs 30, finds 'x' in the local scope
inner()
print(x) # Outputs 20, finds 'x' in the enclosed scope
outer()
print(x) # Outputs 10, finds 'x' in the global scope在这个例子中,x在不同的作用域中被定义,并且影射到不同的值。每一个x变量都会被优先查找在最内层的作用域中。
使用全局变量共享数据
# 全局变量
num = 0
# 定义一个用来上传数据的函数
def upoad_data():
# 如果想修改全局变量,需要声明
global num
num = 100
print(num)
# 定义一个用下载数据的函数
def download_data():
print(num)
# 测试
download_data()
upoad_data()
download_data()
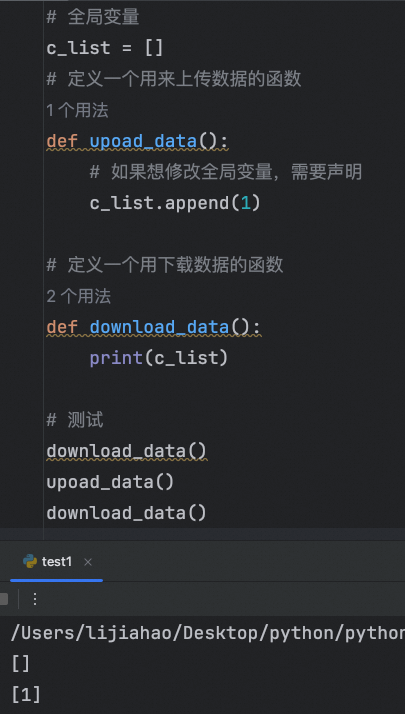
# c_list = []
# c_list.append(1)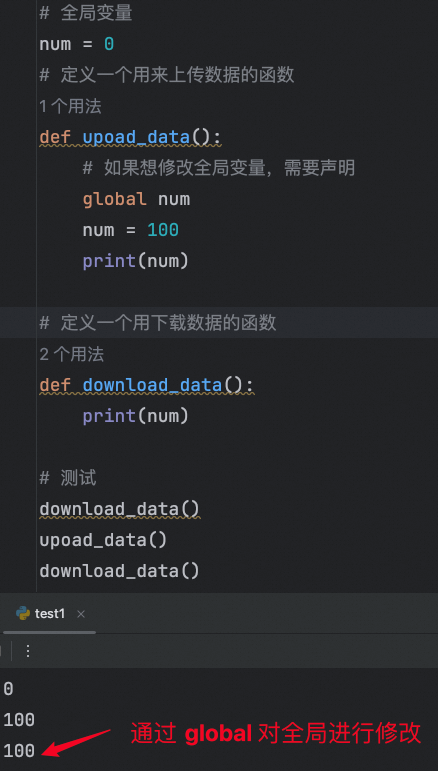
注意:上面对于不可变对象需要使用 global 声明,但是对于可变对象 list[]就不需要声明全局变量了
默认值参数
在 Python 中,默认参数值是在函数定义时指定的。当函数被调用时,如果没有为具有默认值的参数提供实参(实际参数),那么该参数将使用其默认值。使用默认参数值能够使函数更加灵活,因为它允许调用者在需要时提供额外的参数,而在大多数情况下则可以依赖默认行为。
加入函数定义了参数,如果不传参直接调用会报错,多给少给参数也会报错
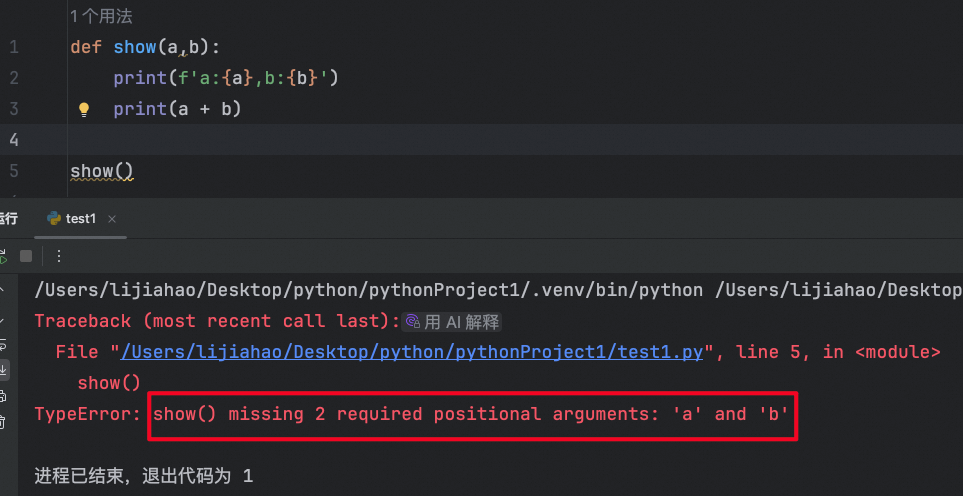
假如添加了默认值:
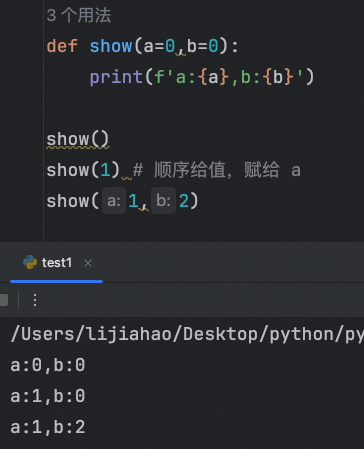
使用默认值参数时,需要注意:
在默认值参数的右侧,不能再出现没有默认参数
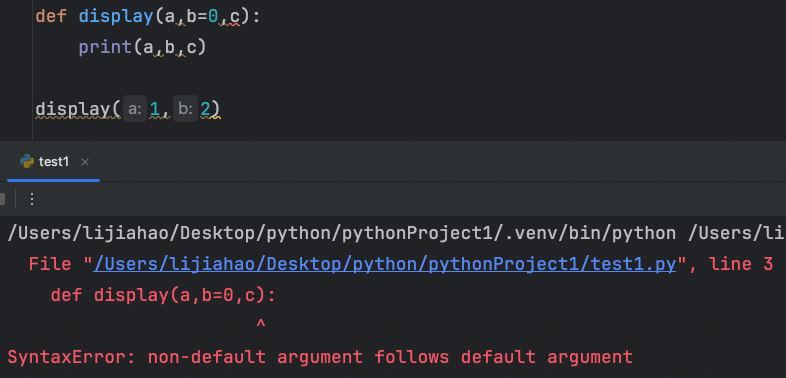
c 此时没有被赋值,只赋值给了 a 和 b
位置参数和关键字参数
位置参数
位置参数是指传递给函数的参数按其位置进行匹配。换句话说,函数调用时传入的第一个参数赋给函数定义中的第一个参数,第二个传入参数赋给第二个,以此类推。例如:
def greet(name, greeting):
print(f"{greeting}, {name}!")
# 调用时按位置提供参数
greet("Alice", "Hello")在上述代码中,"Alice" 会被赋给参数 name,而 "Hello" 则被赋给参数 greeting。
关键字参数
关键字参数在调用函数时明确指定参数名,因此参数的顺序可以与定义顺序不同。通过使用关键字参数,可以使代码更具可读性,并且不必担心传递参数的顺序。例如:
def greet(name, greeting):
print(f"{greeting}, {name}!")
# 使用关键字参数
greet(greeting="Hello", name="Alice")混合使用
可以调用一个函数时同时使用位置参数和关键字参数,但位置参数必须在关键字参数之前。例如:
def greet(name, greeting, punctuation):
print(f"{greeting}, {name}{punctuation}")
# 混合使用
greet("Alice", greeting="Hello", punctuation="!")不定长参数
不定长位置参数
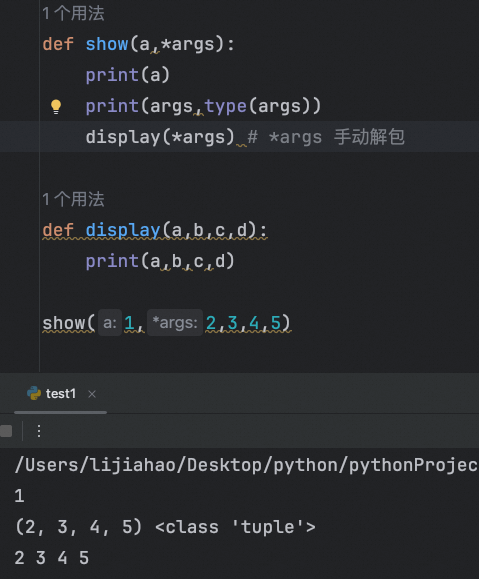
*args 允许函数接收任意数量的位置参数,并将它们作为一个元组传递给函数。
def print_args(*args):
for arg in args:
print(arg)
print_args(1, 2, 3)例子:要求多个值的和(不确定多少个值)
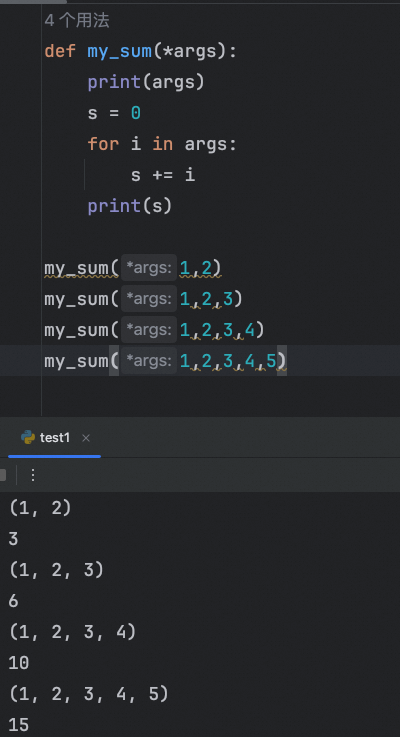
不定长关键字参数
**kwargs 允许函数接收任意数量的关键字参数,并将它们作为一个字典传递给函数。例如:
def print_kwargs(**kwargs):
for key, value in kwargs.items():
print(f"{key}: {value}")
print_kwargs(name="Alice", age=30)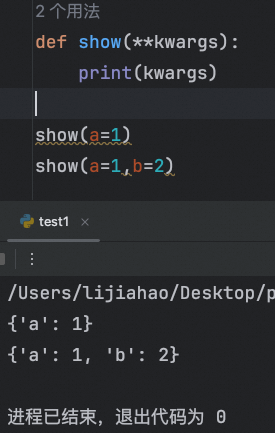
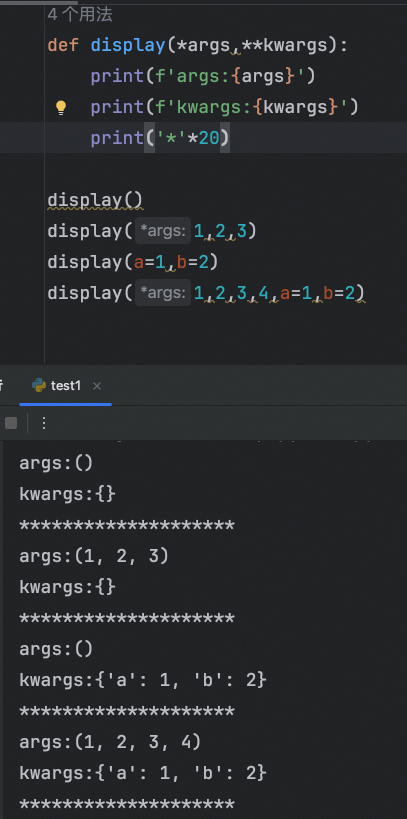
不定长位置参数 、不定长关键字参数混合使用
记住这种函数定义格式:当定义函数时,如果函数的参数想要接收任意类型和个数,那么定义格式如下:
def 函数名(*args, **kwargs):
函数体内容你可以在同一个函数中同时使用 *args 和 **kwargs,使得函数可以接收任意数目的位置参数和关键字参数:
*args和**kwargs可以用任何名称替换,但按惯例通常使用这两个名字。- 在函数定义中,
*args必须放在**kwargs之前。 - 它们也可以与其他参数类型(如普通位置参数和关键字参数)结合使用。
定义一个可以接收任何参数的函数
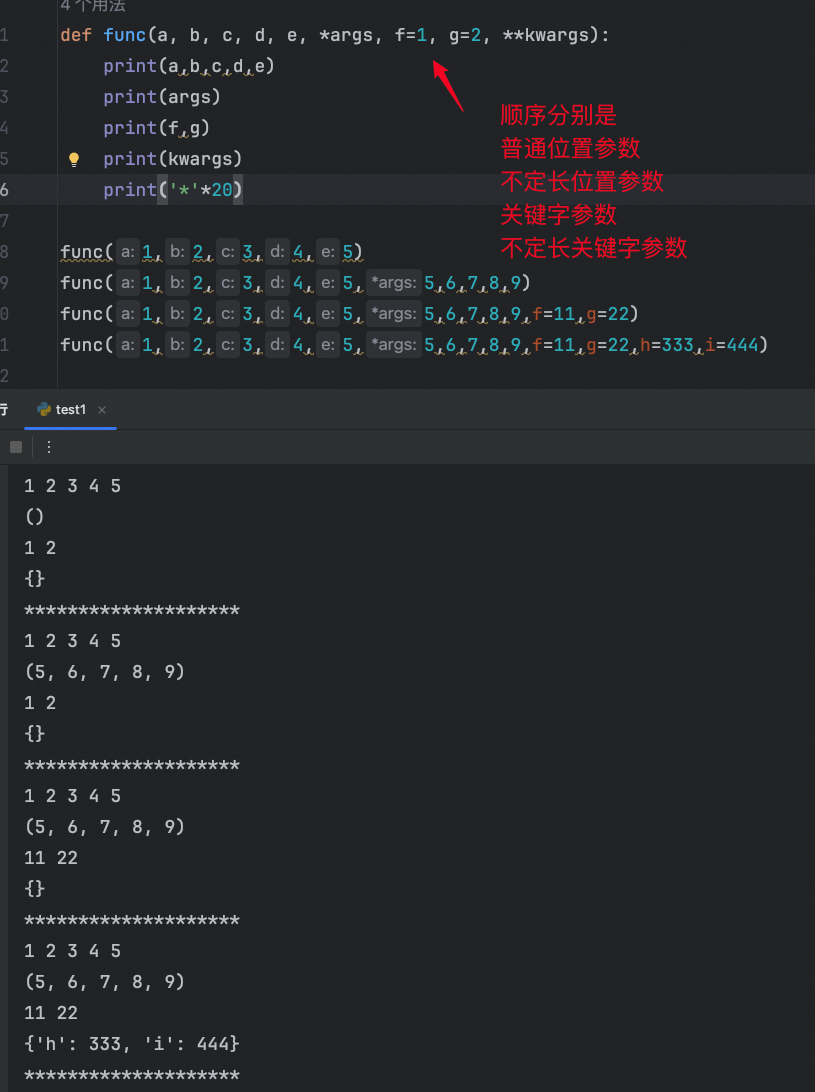
普通位置参数、关键字参数、不定长位置参数 、不定长关键字参数混合使用
函数可变参数的二次传递
我们知道,*args 会将匹配长度的元素自动打包成一个元祖,当需要将元祖中的元素传参给其他函数时,如果不将元祖解包,导致报错
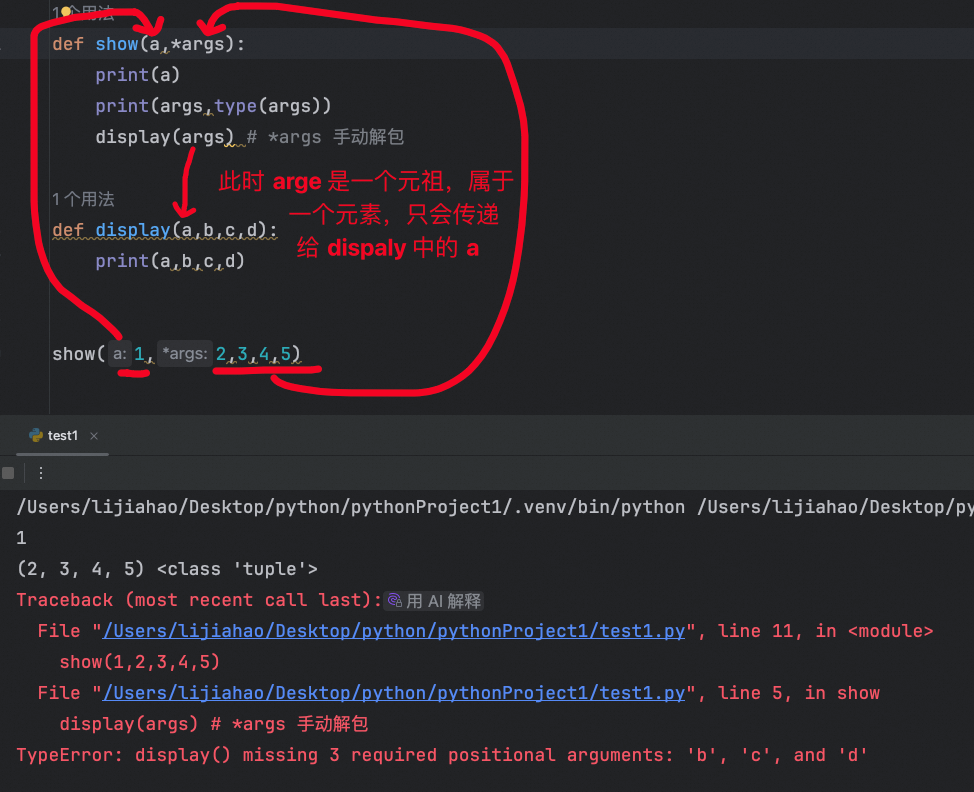
使用 *args 或 **kwargs 来解包参数,以便将它们完整地传递给另一个函数。
引用
引用就是数据在内存中存储时的内存编号
int 类型引用样例
数字类型和字符串类型数据的缓存区:为了在程序中使用数据时,效率更高,ptyhon解释会在程序加载后,产生一个缓存区,缓存区中存放是常用的数据
- 数字:-5~255
- 字符串:长度为小于20的字符串
通过 id() 函数可以得到数据在内存中的地址
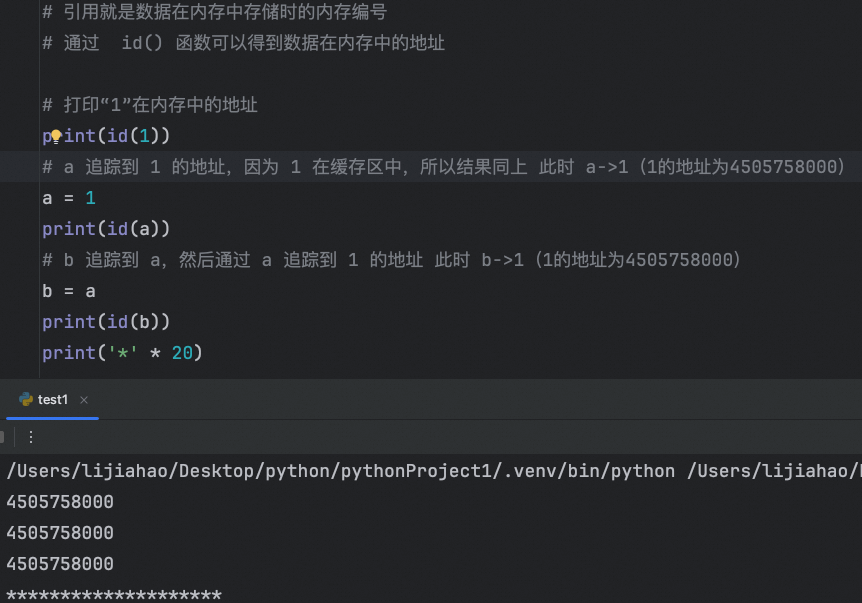
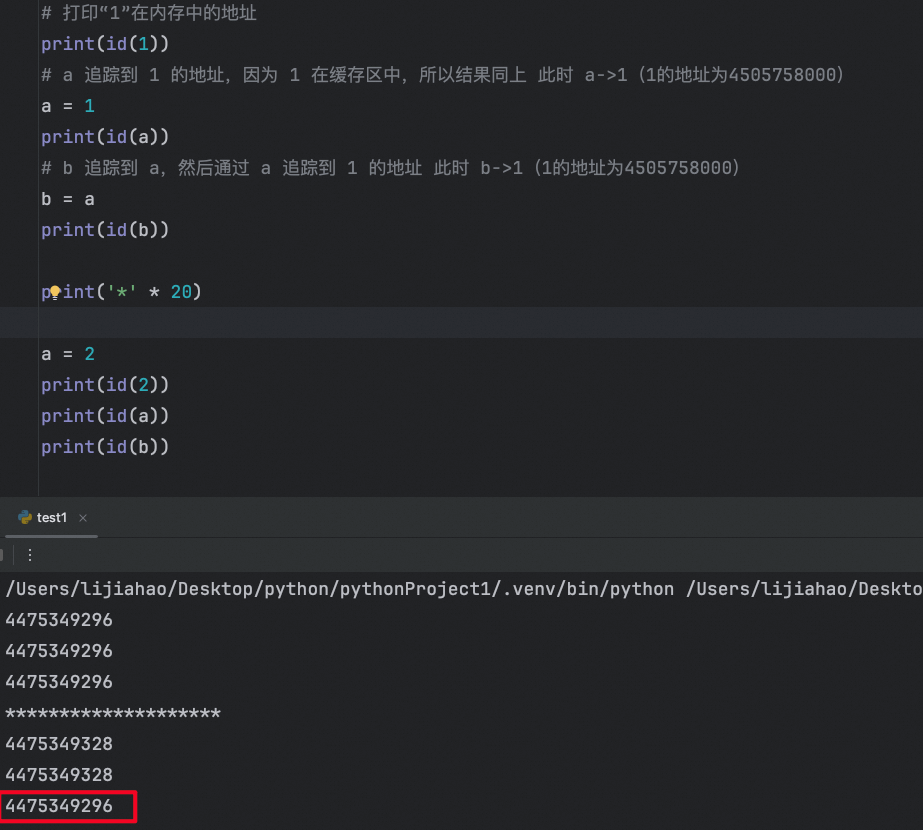
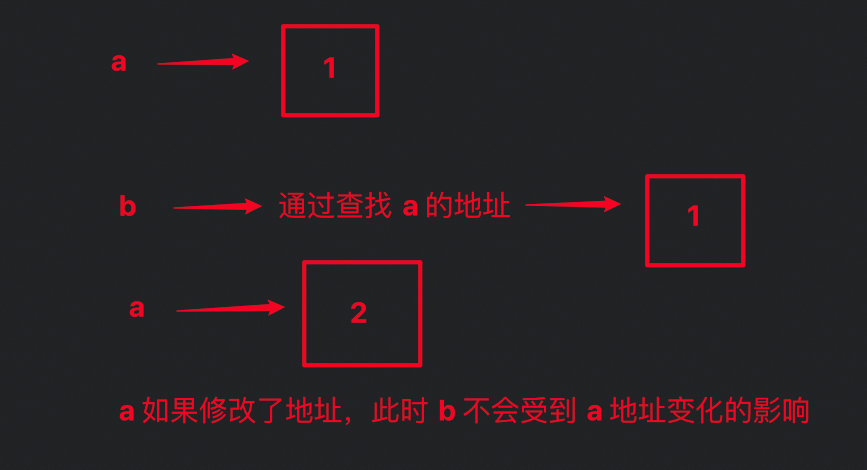
a 赋值给 b,单是假如之后修改 a,b 不会跟着a修改内存地址位置
原理:
列表类型引用样例
下面列表添加一个元素,为什么内存空间位置没有改变呢?
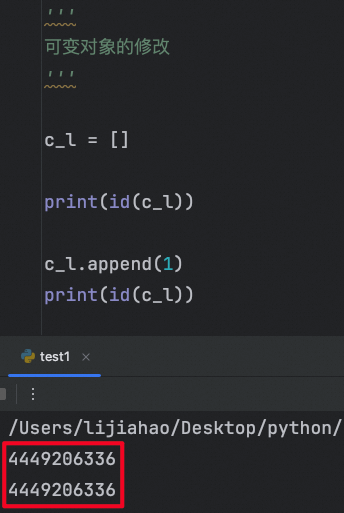
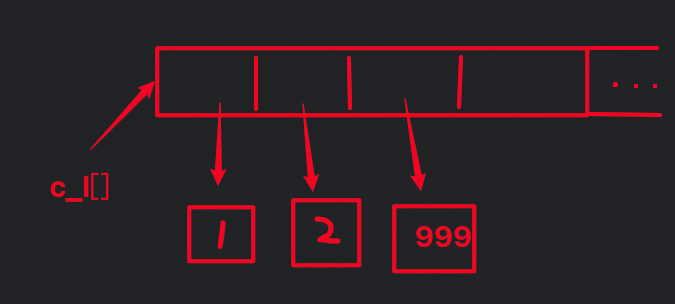
原理:
将列表看做是一个容器,如果有值添加,会装在这个容器的内部,但是容器的地址永远不会改变
可变对象和不可变对象初步理解
在 Python 中,「引用」(reference) 是一个重要的概念,它指的是变量名与实际存储在内存中的对象之间的关系。每个变量名实际上是一个引用,它引用了内存中的某个对象。
x = [1, 2, 3]在这个例子中,变量 x 是一个引用,它指向了内存中的列表对象 [1, 2, 3]。
对象的引用计数: Python 使用引用计数来管理内存。每当有一个新的引用指向一个对象时,该对象的引用计数增加。当引用被删除或指向不同的对象时,引用计数减少。引用计数为零的对象会被内存管理器自动释放。
引用与可变对象: 对于可变对象(如列表或字典),多个变量可以引用同一个对象。如果通过一个引用对该对象进行了改变,其他引用也会反映出这种改变。
a = [1, 2, 3]
b = a # b 也是引用同一个列表
b.append(4)
print(a) # 输出 [1, 2, 3, 4]不可变对象: 对于不可变对象(如整数、字符串、元组),即使多个变量引用了同一个对象,也不能更改该对象的值。所有改变操作都会创建一个新的对象。
a = 10
b = a
a = a + 1
print(b) # 输出 10 而不是 11可变对象和不可变对象总结
由上可知:
不可变类型:
数字 int
字符串 str
浮点数 float
布尔类型 bool
元组 tuple
特点: 这些数据都是不可以直接修改的,如果在修改或赋值时,都会开辟一个新空间
可变类型:
列表 list
字典 dict
集合 set
特点: 这个些数据类型,是可以直接在原对象上进行修改数据,修改完成后,并不影响原对象地址发布者:LJH,转发请注明出处:https://www.ljh.cool/41743.html