
弹性伸缩概述
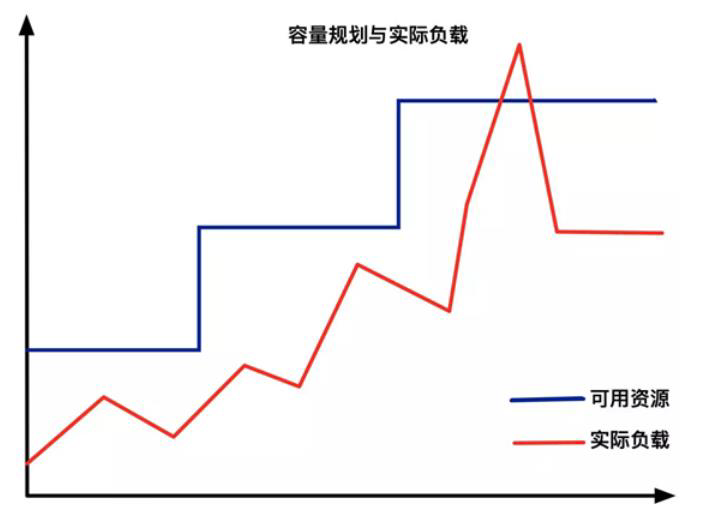
从传统意义上,弹性伸缩主要解决的问题是容量规划与实际负载的矛盾。
蓝色水位线表示集群资源容量随着负载的增加不断扩容,红色曲线表示集群资源实际负载变化。
弹性伸缩就是要解决当实际负载增大,而集群资源容量没来得及反应的问题。

常见资源冗余方案
- 给容量预留资源
- 微服务、网关入口限流
- 弹性伸缩
- 对于突发激增短时的并发,将新创建的服务器抽离出来,放至缓冲处理
在Kubernetes平台中,资源分为两个维度:
- Node级别:K8s将多台服务器抽象一个集群资源池,每个Node提供这些资源
- Pod级别:Pod是K8s最小部署单元,运行实际的应用程序,使用request和limit为Pod配额
因此,K8s实现弹性伸缩也是这两个级别,当Node资源充裕情况下,Pod可任意弹性,当不足情况下需要弹性增加节点来扩容资源池。
- 针对Pod负载:当Pod资源不足时,使用HPA(Horizontal Pod Autoscaler)自动增加Pod副本数量
- 针对Node负载:当集群资源池不足时,使用CA(Cluster Autoscaler)自动增加Node
Node弹性伸缩有两种方案:
- Cluster Autoscaler:是一个自动调整Kubernetes集群大小的组件,需要与公有云一起使用,例如AWS、Azure、Aliyun。项目地址:https://github.com/kubernetes/autoscaler
- 自研发:根据Node监控指标或者Pod调度状态判断是否增加Node,需要一定开发成本
自动缩放方式:
Node自动扩容/缩容:实现思路
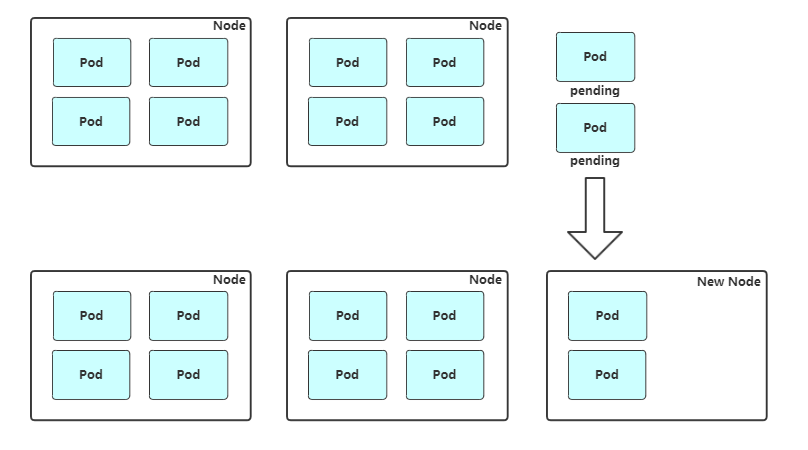
自动增加Node:周期性检查是否有充足集群资源来调度新创建的Pod,当资源不足时会创建新的Node
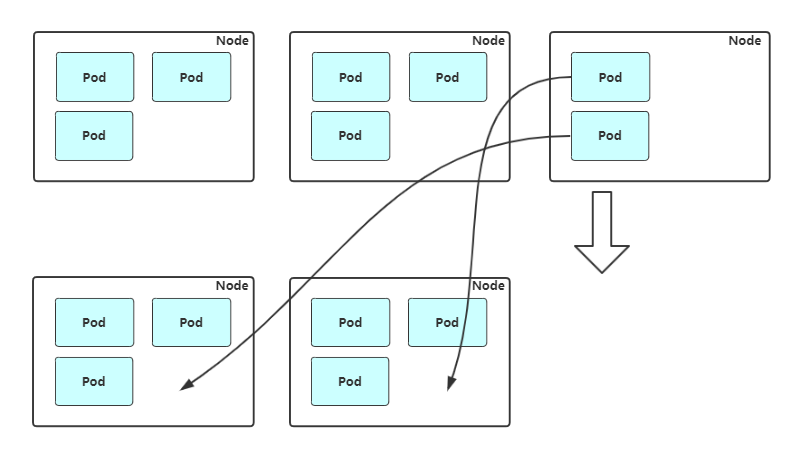
自动减少Node:周期性检查Node资源使用情况,当一个Node长时间资源利用率很低时,自动从集群中下线,原有Pod会自动调度到其他Node上
实现方案
Cluster Autoscaler云提供商:
参考:https://github.com/kubernetes/autoscaler/tree/master/cluster-autoscaler
•阿里云:https://github.com/kubernetes/autoscaler/blob/master/cluster-autoscaler/cloudprovider/alicloud/README.md
•AWS:https://github.com/kubernetes/autoscaler/blob/master/cluster-autoscaler/cloudprovider/aws/README.md
•Azure:https://github.com/kubernetes/autoscaler/blob/master/cluster-autoscaler/cloudprovider/azure/README.md
•GCE:https://kubernetes.io/docs/concepts/cluster-administration/cluster-management/
•GKE:https://cloud.google.com/container-engine/docs/cluster-autoscalerNode自动扩容/缩容:自研发
当集群资源不足时,触发新增Node大概思路:
1.申请一台服务器
2.调用Ansible脚本部署Node组件并自动加入集群
3.检查服务是否可用,加入监控
4.完成Node扩容,接收新Pod
基于Ansible自动增加Node
自动减少Node:
如果你想从Kubernetes集群中删除节点,正确流程如下:
1、获取节点列表
kubectl get node
2、设置不可调度
kubectl cordon <node_name>
3、驱逐节点上的Pod
kubectl drain <node_name> --ignore-daemonsets
4、移除节点
kubectl delete node <node_name>如果这块自动化的话,前提要获取长期空闲的Node,然后执行这个步骤。
HPA介绍
Horizontal Pod Autoscaler(HPA,Pod水平自动伸缩):根据资源利用率或者自定义指标自动调整Deployment的Pod副本数量,提供应用并发。HPA不适于无法缩放的对象,例如DaemonSet。
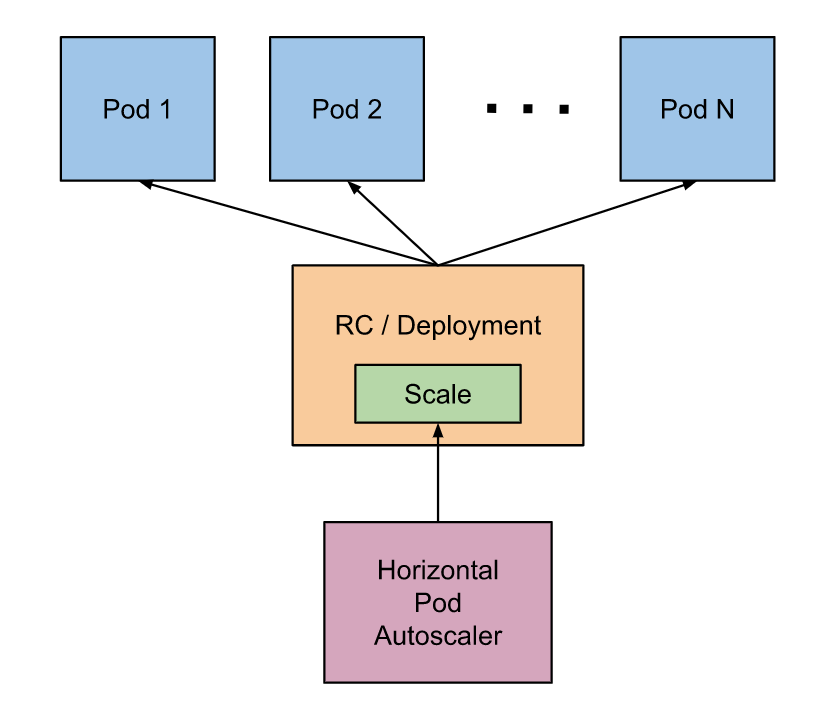
HPA基本工作原理
Kubernetes 中的Metrics Server 持续采集所有Pod 副本的指标数据。HPA 控制器通过Metrics Server 的API(聚合API)获取这些数据,基于用户定义的扩缩容规则进行计算,得到目标Pod 副本数量。当目标Pod 副本数量与当前副本数量不同时,HPA 控制器就向Pod 的Deployment控制器发起scale 操作,调整Pod 的副本数量,完成扩缩容操作。
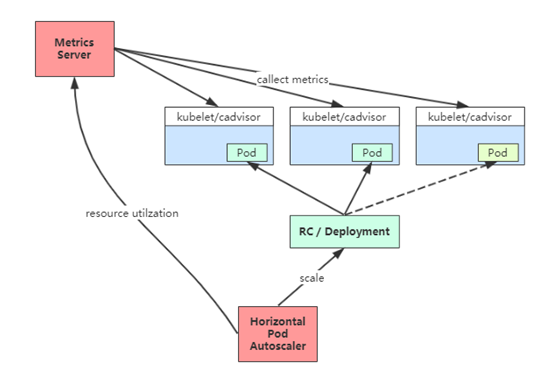
使用HPA前提条件
使用HPA,确保满足以下条件:
1、启用Kubernetes API聚合层
2、相应的API已注册:
•对于资源指标(例如CPU、内存),将使用metrics.k8s.io API,一般由metrics-server提供。
•对于自定义指标(例如QPS),将使用custom.metrics.k8s.io API,由相关适配器(Adapter)服务提供。
已知适配器列表:
https://github.com/kubernetes/metricsKubernetes API聚合层:
在Kubernetes 1.7 版本引入了聚合层,允许第三方应用程序通过将自己注册到kube-apiserver上,仍然通过API Server 的HTTP URL 对新的API 进行访问和操作。为了实现这个机制,Kubernetes 在kube-apiserver 服务中引入了一个API 聚合层(API Aggregation Layer),用于将扩展API 的访问请求转发到用户服务的功能。
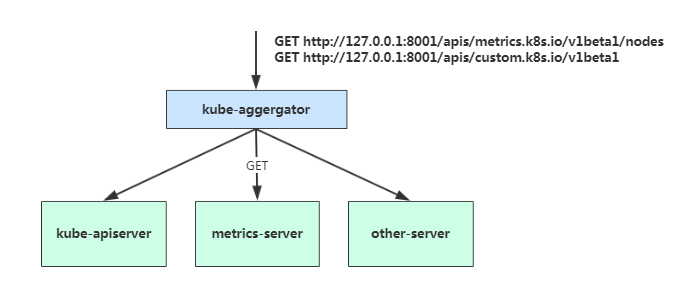
启用聚合层:
如果你使用kubeadm部署的,默认已开启。如果你使用二进制方式部署的话,需要在kube-APIServer中添加启动参数,增加以下配置:
# vi /opt/kubernetes/cfg/kube-apiserver.conf
...
--requestheader-client-ca-file=/opt/kubernetes/ssl/ca.pem \
--proxy-client-cert-file=/opt/kubernetes/ssl/server.pem \
--proxy-client-key-file=/opt/kubernetes/ssl/server-key.pem \
--requestheader-allowed-names=kubernetes \
--requestheader-extra-headers-prefix=X-Remote-Extra-\
--requestheader-group-headers=X-Remote-Group \
--requestheader-username-headers=X-Remote-User \
--enable-aggregator-routing=true \
...Metrics Server:是一个数据聚合器,从kubelet收集资源指标,并通过Metrics API在Kubernetes apiserver暴露,以供HPA使用。
项目地址:https://github.com/kubernetes-sigs/metrics-server
Metrics Server部署:
# wget https://github.com/kubernetes-sigs/metrics-server/releases/download/v0.6.2/components.yaml
# vi components.yaml
...
containers:
-args:
---cert-dir=/tmp
---secure-port=4443
---kubelet-preferred-address-types=InternalIP,ExternalIP,Hostname
---kubelet-use-node-status-port
---kubelet-insecure-tls
image: registry.cn-hangzhou.aliyuncs.com/google_containers/metrics-server:v0.6.2
...kubelet-insecure-tls:不验证kubelet提供的https证书
测试:
kubectl get apiservices |grep metrics # 查看注册的聚合层
kubectl get --raw /apis/metrics.k8s.io/v1beta1/nodes
kubectl get --raw /apis/metrics.k8s.io/v1beta1/pods
也可以使用kubectl top访问Metrics API:
kubectl top node #查看Node资源消耗
kubectl top pod #查看Pod资源消耗:如果能正常显示资源消耗说明Metrics Server服务工作正常。

测试应用
1、部署应用
kubectl create deployment web --image=nginx --dry-run=client --replicas=3 -o yaml > deployment.yaml
kubectl expose deployment web --port=80 --target-port=80 --dry-run=client -o yaml > service.yaml
注意:修改yaml,增加resources.requests.cpu
resources:
requests:
memory: "512Mi"
cpu: "0.5"
limits:
memory: "612Mi"
cpu: "0.6"
2、创建HPA
kubectl autoscale deployment web --min=2 --max=10 --cpu-percent=20 --dry-run=client -o yaml > hpa1.yaml
kubectl get hpa
说明:为名为web的deployment创建一个HPA对象,目标CPU使用率为20%(生产环境配置到80%),副本数量配置为2到10之间。
3、压测service地址
yum install httpd-tools
ab -n 200000 -c 2000 http://10.106.157.80/index.html # 总20w请求,并发1000
4、观察扩容状态
kubectl get hpa
kubectl get pods在弹性伸缩中,冷却周期是不能逃避的一个话题,由于评估的度量标准是动态特性,副本的数量可能会不断波动,造成丢失流量,所以不应该在任意时间扩容和缩容。
在HPA 中,为缓解该问题,默认有一定控制:
---horizontal-pod-autoscaler-downscale-delay :当前操作完成后等待多次时间才能执行缩容操作,默认5分钟
---horizontal-pod-autoscaler-upscale-delay :当前操作完成后等待多长时间才能执行扩容操作,默认3分钟可以通过调整kube-controller-manager组件启动参数调整。
基于自定义指标
为满足更多的需求,HPA也支持自定义指标,例如QPS、5xx错误状态码等,实现自定义指标由autoscaling/v2版本提供,而v2版本又分为beta1和beta2两个版本。
- Resource Metrics(资源指标)
- •Custom Metrics(自定义指标)
而在autoscaling/v2beta2的版本中额外增加了External Metrics(扩展指标)的支持。
对于自定义指标(例如QPS),将使用custom.metrics.k8s.io API,由相关适配器(Adapter)服务提供。
已知适配器列表:https://github.com/kubernetes/metrics/blob/master/IMPLEMENTATIONS.md#custom-metrics-api
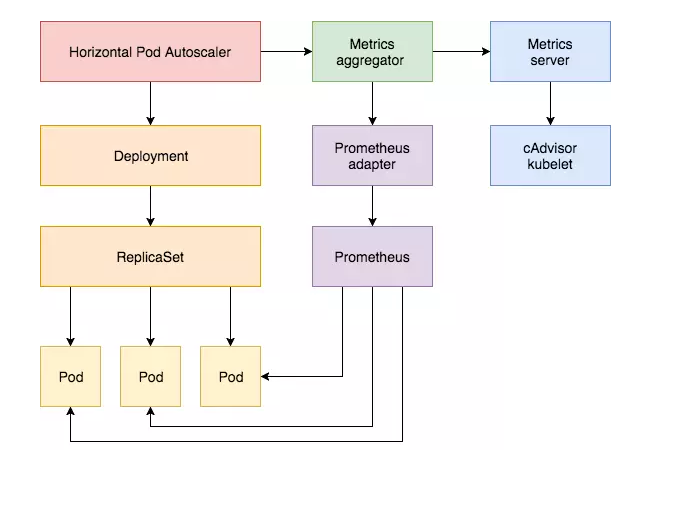
资源指标与自定义指标工作流程图
假设我们有一个网站,想基于每秒接收到的HTTP请求对其Pod进行自动缩放,实现HPA大概步骤:
1、部署Prometheus
2、对应用暴露指标,部署应用,并让Prometheus采集暴露的指标
3、部署Prometheus Adapter
4、为指定HPA配置Prometheus Adapter
5、创建HPA
6、压测、验证
1、部署Prometheus
参考:https://www.ljh.cool/37775.html
2、对应用暴露指标,部署应用,并让Prometheus采集暴露的指标。
在做这步之前先了解下Prometheus如何监控应用的。
如果要想监控,前提是能获取被监控端指标数据,并且这个数据格式必须遵循Prometheus数据模型,这样才能识别和采集,一般使用exporter提供监控指标数据。但对于自己开发的项目,是需要自己实现类似于exporter的指标采集程序。
exporter列表:https://prometheus.io/docs/instrumenting/exporters
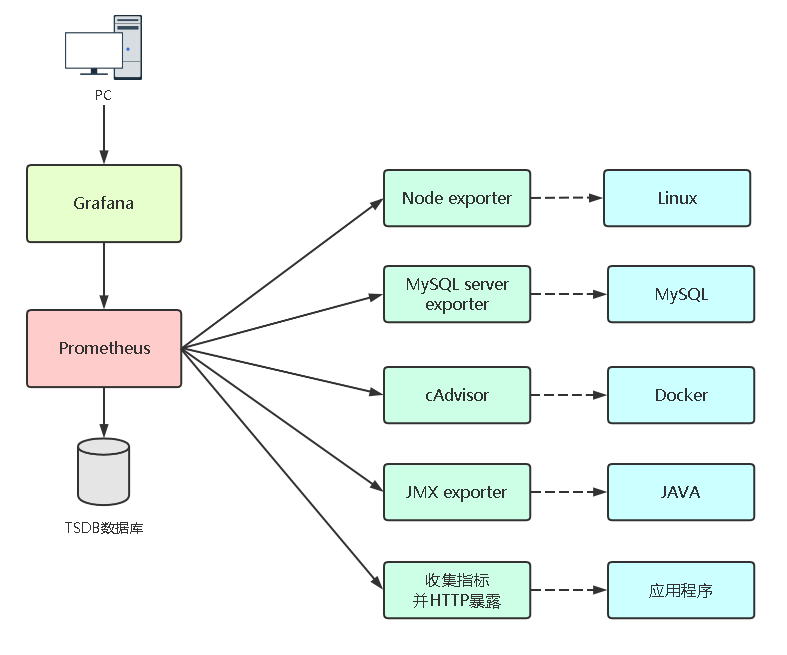
先模拟自己开发一个网站,采用Python Flask Web框架,写两个页面:
- / 首页
- /metrics 指标
然后使用Dockefile制作成镜像并部署到Kubernetes平台。
main.py
import prometheus_client
from prometheus_client import Counter
from flask import Response, Flask
app = Flask(__name__)
requests_total = Counter("request_count","统计HTTP请求")
@app.route("/metrics")
def requests_count():
requests_total.inc()
return Response(prometheus_client.generate_latest(requests_total),
mimetype="text/plain")
@app.route('/')
def index():
requests_total.inc()
return "Hello World"
if __name__ == "__main__":
app.run(host="0.0.0.0",port=80)
Dockerfile
FROM python
RUN pip install flask -i https://mirrors.aliyun.com/pypi/simple/ && \
pip install prometheus_client -i https://mirrors.aliyun.com/pypi/simple/
COPY main.py /
CMD python main.pymetrics-flask-app.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: metrics-flask-app
spec:
replicas: 3
selector:
matchLabels:
app: flask-app
template:
metadata:
labels:
app: flask-app
# 声明Prometheus采集
annotations:
prometheus.io/scrape: "true"
prometheus.io/port: "80"
prometheus.io/path: "/metrics"
spec:
containers:
- image: lizhenliang/metrics-flask-app
name: web
---
apiVersion: v1
kind: Service
metadata:
name: metrics-flask-app
spec:
ports:
- port: 80
protocol: TCP
targetPort: 80
selector:
app: flask-app部署:
kubectl create -f metrics-flask-app.yaml
查看
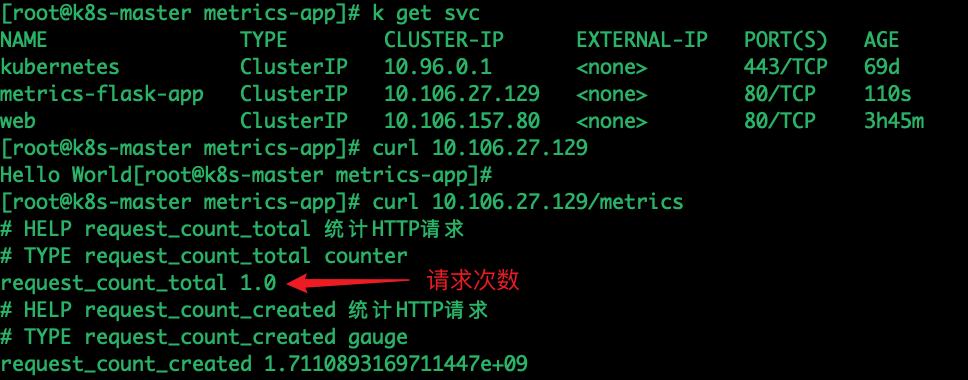
发布者:LJH,转发请注明出处:https://www.ljh.cool/41175.html
评论列表(2条)
At this time I am going to do my breakfast, afterward having my breakfast
coming over again to read additional news.
I am sure this post has touched all the internet people, its really really nice piece of writing on building up
new webpage.