
一、修改为IPVS模式
集群环境:
kubeadm 1.23
k8s-master:192.168.1.10
k8s-node1:192.168.1.11
k8s-node2:192.168.1.12
网络模式:flannel xvlan前置条件:
关闭SELinux,firewall
开启路由转发功能:
vim /etc/sysctl.conf 需要有:
net.ipv4.ip_forward=1

kubeadm安装的集群修改调度方式:
内核模块加载
cat > /etc/sysconfig/modules/ipvs.modules <<EOF
#!/bin/bash
ipvs_modules="ip_vs ip_vs_lc ip_vs_wlc ip_vs_rr ip_vs_wrr ip_vs_lblc ip_vs_lblcr ip_vs_dh ip_vs_sh ip_vs_fo ip_vs_nq ip_vs_sed ip_vs_ftp nf_conntrack"
for kernel_module in \${ipvs_modules}; do
/sbin/modinfo -F filename \${kernel_module} > /dev/null 2>&1
if [ $? -eq 0 ]; then
/sbin/modprobe \${kernel_module}
fi
done
EOF
chmod 755 /etc/sysconfig/modules/ipvs.modules && bash /etc/sysconfig/modules/ipvs.modules && lsmod | grep ip_vs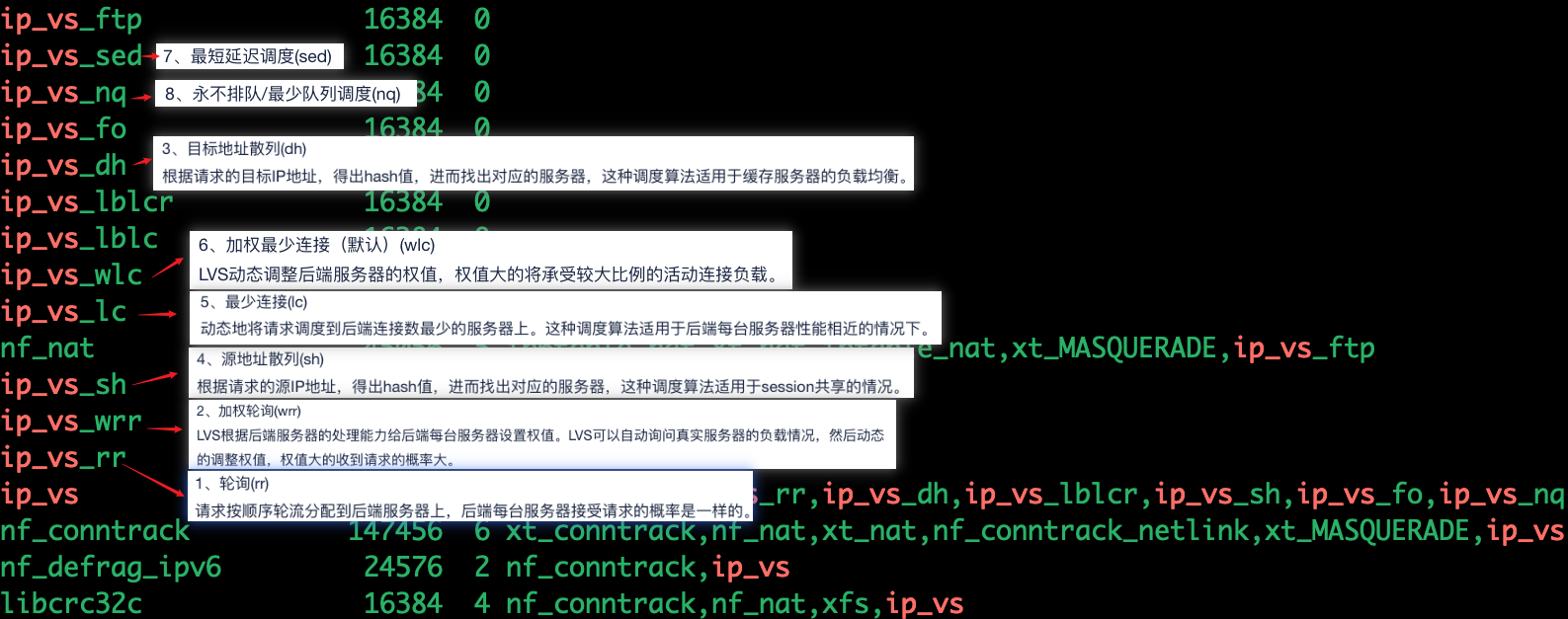
轮巡算法详细参考:https://www.cnblogs.com/xuwymm/p/15010096.html#111-rr%E8%B0%83%E5%BA%A6%E7%AE%97%E6%B3%95
RR:round robin 轮询调度算法,将每一次用户的请求,轮流分配给 Real Server节点。
WRR:weighted round robin 加权轮询调度算法,根据服务器的硬件情况、以及处理能力,为每台服务器分配不同的权值,使其能够接受相应权值的请求。
动态调度算法:
根据算法及 RS 节点负载状态进行调度,较小的 RS 将被调度(保证结果公平)
-----------------------------------------------------------------------------------
LC调度算法:Least-Connection 最少连接数调度算法,哪台 RS 连接数少就将请求调度至哪台 RS ,类似于nginx的least_con算法。
算法: Overhead = ( Active * 256 + Inactive仅连接 ) 一个活动连接相当于256个非活动连接。
问题:调度算法是谁的连接少就调度给准,没有考虑到后端主机的性能。
WLC调度算法:Weighted Least-Connection 加权最小连接数(默认调度算法),在服务器性能差异较大的情况下,采用“加权最少链接”调度算法优化负载均衡性能,权值较高的 RS 节点,将承受更多的连接;负载均衡可以自动问询 RS 节点服务器的负载状态,通过算法计算当前连接数最少的节点,而后将新的请求调度至该节点。
算法: Overhead =( Active * 256 + Inactive )/Weight
-----------------------------------------------------------------------------------
SH调度算法:Source Hashing 源地址 hash 调度算法,将请求的源 IP 地址进行 Hash 运算,得到一个具体的数值,同时对后端服务器进行编号,按照源地址IP hash 运算结果将请求分发到对应编号的服务器上。SH算法不能和WRR算法同时使用,配置的RS权重无效。类似于nginx的ip_hash算法。适用于session共享
1.可以实现不同来源 IP 的请求进行负载分发;
2.同时还能实现相同来源 IP 的请求始终被派发至某一台特定的节点
DH调度算法:destination hash 根据目标地址的hash值将客户端的请求始终发往同一个远程服务器 。类似于nginx的hash $request_uri调度算法。应用场景:适用于缓存服务器的负载均衡
问题:如果大量的用户都转发到Cache1,则会造成Cache1节点压力过大,而其他Cache节点无任何压力,违背了均衡特性
SED调度算法:Shortest Expected Delay 最短期望延迟,尽可能让权重高的优先接收请求,不再考虑非活动状态,把当前处于活动状态的数目+1,通过算法计算当前连接数最少的节点,而后将新的请求调度至该节点。
算法:在WLC基础上改进, Overhead = (ACTIVE+1)*256/Weight
NQ调度算法:Never Queue 永不排队/最少队列调度:原理: SED 算法存在的问题是,由于某台服务器的权重较小,比较空闲,甚至接收不到请求,而权重大的服务器会很忙,而 NQ 算法是说不管权重多大都会被分配到请求。简单来说,就是无需队列,如果有台 Real Server 的连接数为0会直接分配过去,后续采用 SED 算法。
算法: Overhead = (ACTIVE+1)*256/Weight
LBLC调度算法:动态目标地址 hash 调度算法,解决 DH调度算法负载不均衡问题
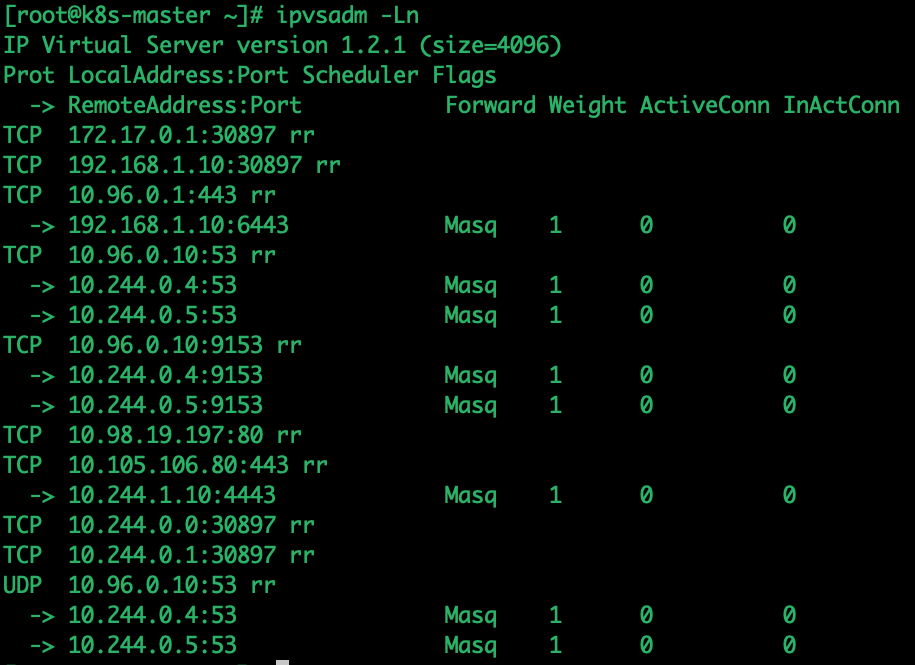
LBLCR调度算法:解决LBLC负载不均衡的问题kubectl edit configmap kube-proxy -n kube-system
kube-system名称空间删除所有kube-proxy pod,等待重启running后查看日志

二、ipvs原理:
ipvs的模型中有两个角色:
调度器:Director,又称为Balancer。 调度器主要用于接受用户请求。
真实主机:Real Server,简称为RS。用于真正处理用户的请求。
IP地址类型分为三种:
Client IP:客户端请求源IP,简称CIP。
Director Virtual IP:调度器用于与客户端通信的IP地址,简称为VIP。
Real Server IP: 后端主机的用于与调度器通信的IP地址,简称为RIP。
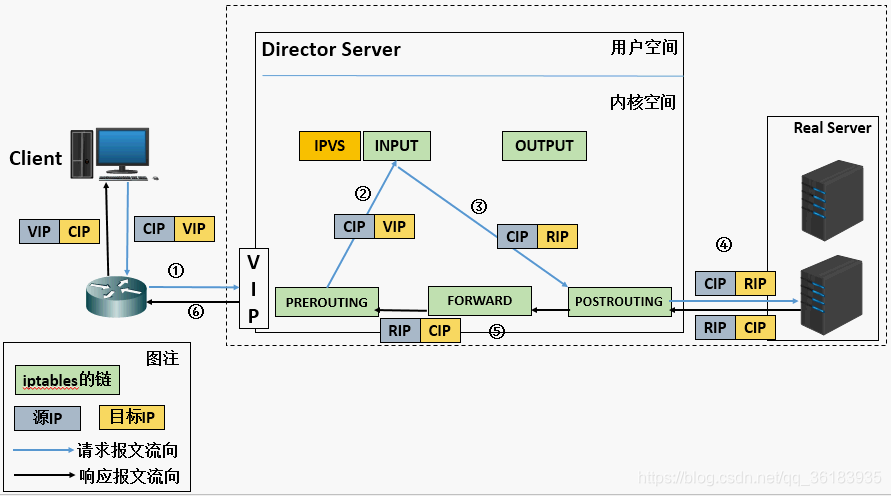
工作过程:
1、当用户请求到达Director Server,此时请求的数据报文会先到内核空间的PREROUTING链。 此时报文的源IP为CIP,目标IP为VIP。
2、PREROUTING检查发现数据包的目标IP是本机,将数据包送至INPUT链。
3、ipvs会监听到达input链的数据包,比对数据包请求的服务是否为集群服务,若是,修改数据包的目标IP地址为后端服务器IP,然后将数据包发至POSTROUTING链。 此时报文的源IP为CIP,目标IP为RIP。
4、POSTROUTING链通过选路,将数据包发送给Real Server
5、Real Server比对发现目标为自己的IP,开始构建响应报文发回给Director Server。 此时报文的源IP为RIP,目标IP为CIP。
6、Director Server在响应客户端前,此时会将源IP地址修改为自己的VIP地址,然后响应给客户端。 此时报文的源IP为VIP,目标IP为CIP。
其他模式详细可见:https://www.ljh.cool/6056.html
三 ipvs在kube-proxy中的使用
开启ipvs后,本机里面的一些信息会改变。
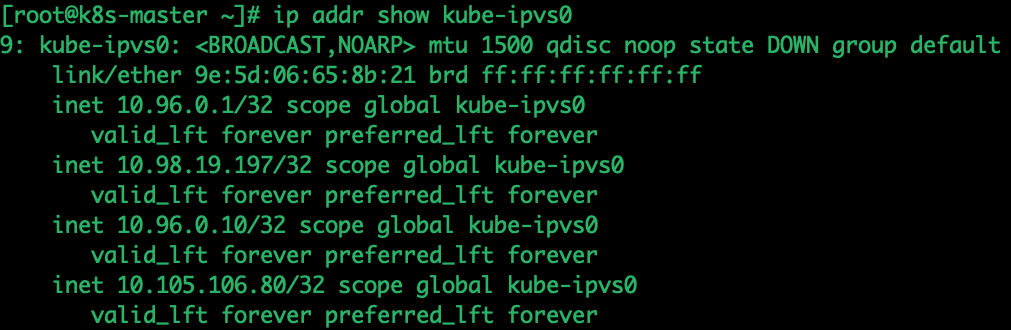
1、网卡:明显的变化是,多了一个绑定很多cluster service ip的kube-ipvs0网卡
2、router:查看router时候,会发现多了一下一些route信息。这些route信息是和上面的网卡信息对应的。

3、ipvs 规则
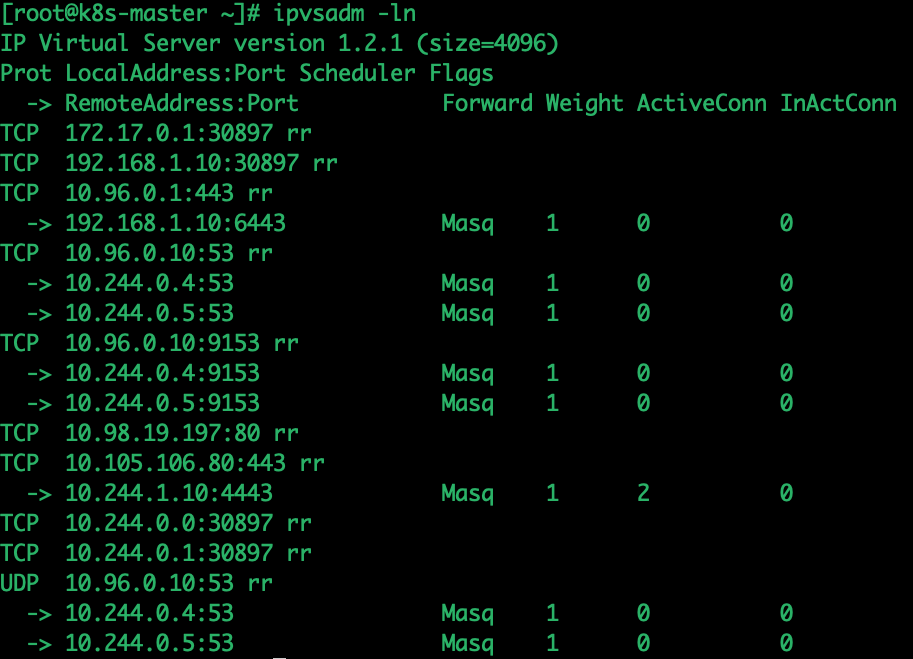
4、新增网卡和route的作用
由于 IPVS 的 DNAT 钩子挂在 INPUT 链上,因此必须要让内核识别 VIP 是本机的 IP。这样才会过INPUT 链,要不然就通过OUTPUT链出去了。k8s 通过设置将service cluster ip 绑定到虚拟网卡kube-ipvs0。
5、使用ipvs的kube-proxy的工作原理
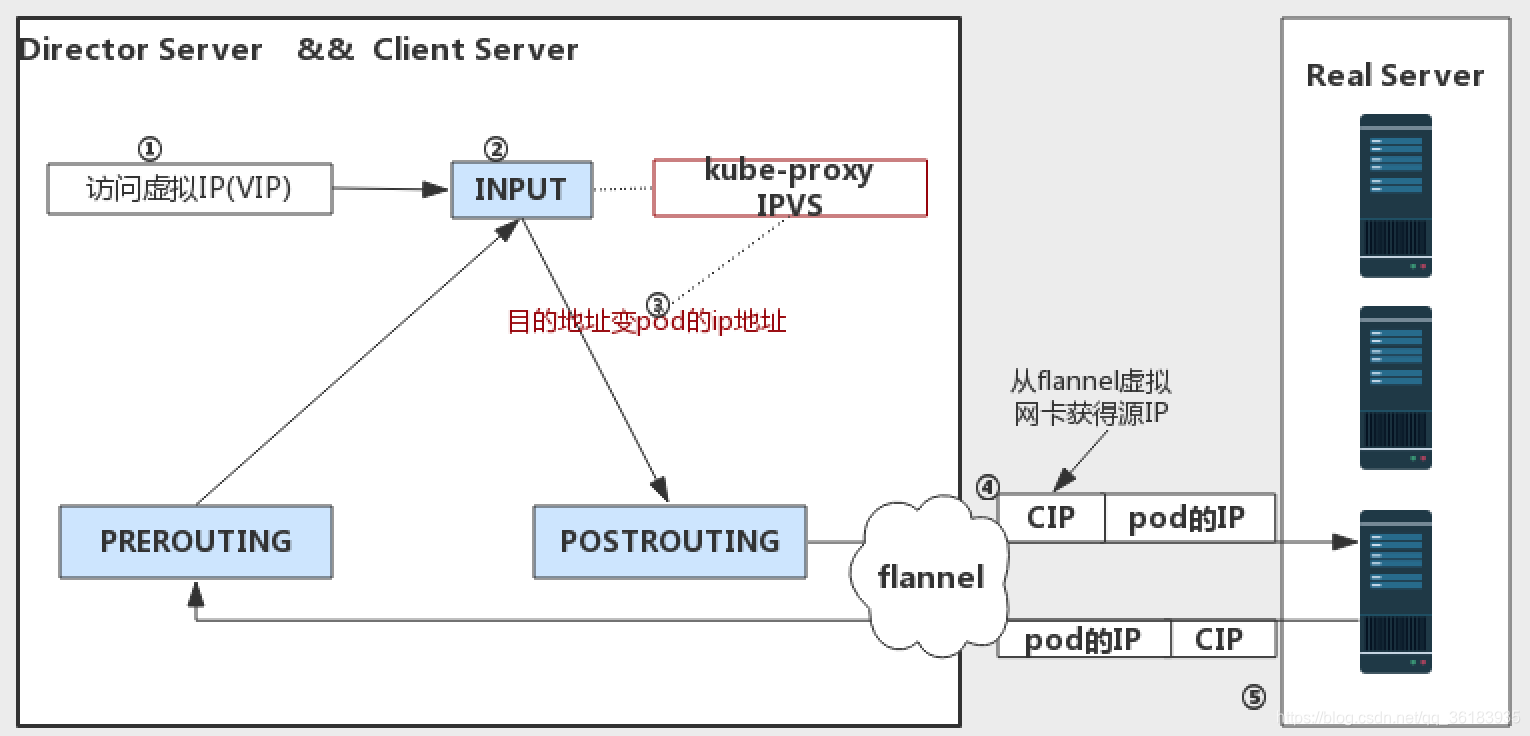
①因为service cluster ip 绑定到虚拟网卡kube-ipvs0上,内核可以识别访问的 VIP 是本机的 IP
②数据包到达INPUT链
③ipvs监听到达input链的数据包,比对数据包请求的服务是为集群服务,修改数据包的目标IP地址为对应pod的IP,然后将数据包发至POSTROUTING链
④数据包经过POSTROUTING链选路,将数据包通过flannel网卡发送出去。从flannel虚拟网卡获得源IP
⑤pod接收到请求之后,构建响应报文,改变源地址和目的地址,返回给客户端。
四、实例-集群内部通过clusterIP访问到pod的流程
本例子中有三台机器,k8s-master、k8s-node1和k8s-node2,pod都在node机器上运行。访问命令为curl 10.106.157.80:80,对应的pod的ip为10.244.1.11、10.244.2.11
kubectl create deployment nginx --image=nginx --replicas=2
kubectl expose deployment nginx --name=nginx-expose --port=80

pod1 IP地址:10.244.1.11 所属节点:k8s-node1:192.168.1.11
pod2 IP地址:10.244.2.11 所属节点:k8s-node2:192.168.1.121、本机接受请求
内核通过本机的路由和虚拟网卡,可以识别访问的 VIP 是本机的 IP
路由

网卡
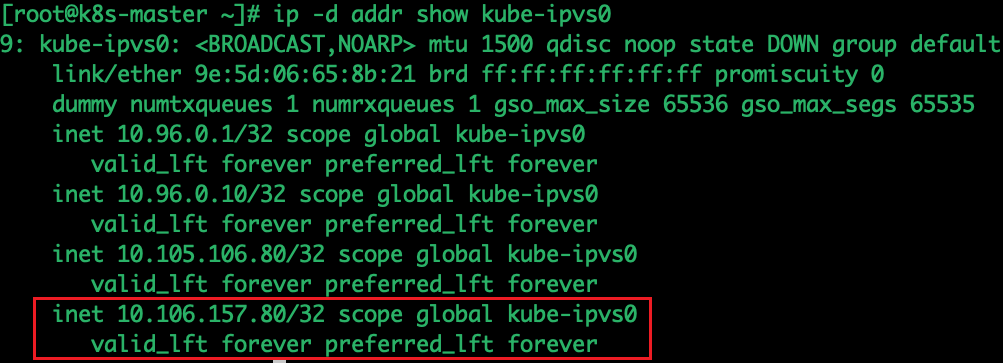
2、将数据包送至INPUT链。
验证是否经过INPUT链
首先、我们在INPUT链中加入一条如下过滤规则。该规则的意思是当有目的地址为172.18.13.222时,都拒绝掉。
iptables -t filter -I INPUT -d 10.106.157.80 -j DROP
iptables --line-number -nvxL INPUT
之后,我们watch INPUT链
watch -n 0.1 "iptables --line-number -nvxL INPUT"当我们访问10.106.157.80时

发现无法访问,并且watch到INPUT确实有拒绝的包。验证成功
删除规则:iptables -t filter -D INPUT 1
3、ipvs对请求做转发
ipvs会监听到达input链的数据包,比对数据包请求的服务是为集群服务,所以修改数据包的目标IP地址为真实服务器IP,然后将数据包发至POSTROUTING链。 此时报文的源IP为CIP,目标IP为RIP(真实ip)

4、通过网卡发出数据包
数据包经过POSTROUTING链选路,将数据包通过flannel网卡发送出去,pod所在机器也通过flannel网卡进行接收。数据包经过master上的flannel网卡第一次被赋予源IP。此时源IP是10.244.0.0/32,目的IP分别是10.244.1.11 、10.244.2.11
k8s-master flannel.1网卡

k8s-node1 网卡

k8s-node2网卡

当我们从master上进行curl svc命令时 curl 10.106.157.80
tcpdump -ni flannel.1 -nn -qt
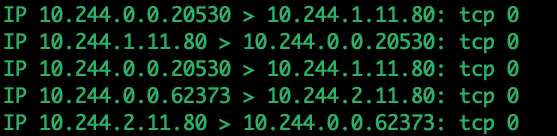
发现是请求从10.244.0.0/32发送的。10.244.0.0正是master上的flannel网卡信息,收到的信息来自于两个不同的后端pod
5、pod接收到请求,处理,返回
pod接收到请求之后,开始构建响应报文返回给客户端。 此时报文的源IP为pod的IP:10.244.1.11 、10.244.2.11,目标IP为10.244.0.0。最终又通过flannel网络将响应报文发回master。
注意:
我们上文所说的通过flannel网络进行通信,最终还是要过机器的真实网卡,因为flannel网络设置的网卡也是虚拟的。
例如我们监听机器的真实网卡eth0
tcpdump -nn -i ens33 src port not 22 and dst port not 22

发布者:LJH,转发请注明出处:https://www.ljh.cool/40287.html