
K8s网络问题解决方案
- 网络故障介绍
- 故障解决方案
1 网络故障类型介绍
在 Kubernetes 中,网络故障的类型软件层面可以分为以下几种:
- 容器网络故障
- 网络插件故障
- 网络策略故障
- DNS 故障
2 横向解决思路(横向思路过于宽泛,简单参考即可,不推荐作为排错思路)
1.1 容器网络故障
在 Kubernetes 中,容器网络故障可能会导致应用程序无法正常工作或通信。容器网络故障可以是由各种原因引起的,例如网络配置错误、网络拓扑不正确、网络插件故障、网络设备故障等。
常见原因
以下是一些可能导致容器网络故障的常见原因:
- Pod IP 地址冲突:如果两个 Pod 具有相同的 IP 地址,则将发生 IP 地址冲突,这可能导致容器网络故障。
- 网络插件故障:Kubernetes 使用不同的网络插件来实现容器网络,例如 Flannel、Calico 等。如果网络插件出现故障,可能会导致容器网络故障。
- 网络设备故障:如果网络设备出现故障,例如交换机、路由器、防火墙等,可能会导致容器网络故障。
- 网络配置错误:如果网络配置不正确,例如子网掩码、网关、DNS 等配置错误,可能会导致容器网络故障。
- 网络拓扑不正确:如果网络拓扑不正确,例如存在网络分区或防火墙规则阻止了容器之间的通信,可能会导致容器网络故障。
解决方案
1. 确认容器是否已正确启动并运行,并且是否已被正确配置为使用正确的网络。
- 执行命令,确认 Pod 是否已正确启动并运行。
kubectl get pods - 执行命令,确认容器的网络配置是否正确。
kubectl describe pod <pod-name>


2. 检查 Pod 和容器的网络配置,例如 IP 地址、子网掩码、网关、DNS 等是否正确配置。
- 执行命令查看容器的网络配置信息。kubectl describe pod <pod-name>
- 执行命令 ,查看容器的网络接口信息。kubectl exec <pod-name> -- ifconfig
3. 检查网络插件是否正常工作,并尝试重启网络插件。
- 如果使用 Flannel 网络插件,执行命令 查看 Flannel 的日志信息。kubectl logs -n kube-system -l k8s-app=flannel
- 如果使用 Calico 网络插件,执行命令,查看 Calico 的日志信息。 kubectl logs -n kube-system -l k8s-app=calico-node

- 重启网络插件:如果使用 Flannel 网络插件,执行命令 kubectl delete pod -n kube-system -l k8s-app=flannel
- 如果使用 Calico 网络插件,执行命令 kubectl delete pod -n kube-system -l k8s-app=calico-node
4 检查网络设备是否正常工作,例如交换机、路由器、防火墙等是否出现故障。
- 检查网络设备的日志或配置信息,确认网络设备是否正常工作。
5. 尝试使用 Kubernetes 工具进行诊断,例如 kubectl,以查看 Pod 和容器的状态和日志。
- 执行命令,查看容器的日志信息。kubectl logs <pod-name>

- 执行命令 ,查看容器的状态信息。kubectl describe pod

6. 如果以上方法无法解决问题,可以考虑重新部署容器网络或更换网络插件。
- 如果使用 Flannel 网络插件,执行命令 重新部署 Flannel 网络插件。
kubectl delete -f https://raw.githubusercontent.com/coreos/flannel/master/Documentation/kube-flannel.yml && kubectl apply -f https://raw.githubusercontent.com/coreos/flannel/master/Documentation/kube-flannel.yml,- 如果使用 Calico 网络插件,执行命令重新部署 Calico 网络插件。
kubectl delete -f https://docs.projectcalico.org/manifests/calico.yaml && kubectl apply -f https://docs.projectcalico.org/manifests/calico.yaml1.2 网络插件故障
Kubernetes中的网络插件是负责容器网络连接与管理的重要组件之一。网络插件的故障可能会导致容器之间无法通信、网络延迟等问题。
常见原因
下面是几种可能导致网络插件故障的情况:
- 网络插件配置错误:网络插件的配置文件可能存在错误,例如配置了错误的IP地址、子网掩码、网关、DNS等信息,这可能导致容器无法正确连接到网络。
- 网络插件版本不兼容:Kubernetes的版本更新可能会导致网络插件版本不兼容,从而导致网络插件故障。
- 网络插件容器故障:网络插件通常运行在Kubernetes集群中的容器中,如果容器出现故障,可能会导致网络插件无法正常工作。
- 网络设备故障:网络插件需要依赖底层的网络设备,例如交换机、路由器、防火墙等,如果这些网络设备出现故障,可能会导致网络插件无法正常工作。
当网络插件故障时,可能会出现以下一些常见问题:
- 容器之间无法通信:当网络插件故障时,可能导致容器之间无法互相通信,这可能会影响应用程序的正常运行。
- 网络延迟增加:当网络插件故障时,容器之间的网络延迟可能会增加,这可能会影响应用程序的性能。
- 网络连接不稳定:当网络插件故障时,网络连接可能会不稳定,这可能会导致容器之间的连接断开或丢失数据包。
解决方案
- 解决网络插件故障的方法取决于具体的故障原因,以下是一些常见的解决方法:
- 检查网络插件的配置文件:如果网络插件的配置文件存在错误,可以通过检查和修改配置文件来解决问题。例如,可以检查IP地址、子网掩码、网关、DNS等信息是否正确配置。
- 升级或降级网络插件版本:如果网络插件版本不兼容,可以尝试升级或降级网络插件版本来解决问题。建议在升级或降级前备份网络插件的配置文件,以避免数据丢失。
- 重启网络插件容器:如果网络插件容器出现故障,可以尝试重启容器来解决问题。例如,可以使用kubectl命令重启网络插件的Pod。
- 检查网络设备是否正常工作:如果网络插件依赖的底层网络设备出现故障,可以通过检查网络设备的日志或配置信息来解决问题。例如,可以检查交换机、路由器、防火墙等网络设备的日志或配置信息,确认网络设备是否正常工作。
- 重新部署网络插件:如果以上方法无法解决问题,可以考虑重新部署网络插件。例如,可以使用kubectl命令删除网络插件的Pod和Service,然后重新部署网络插件。在重新部署前建议备份网络插件的配置文件,以避免数据丢失。
解决网络插件故障常用命令
检查网络插件的Pod是否正常运行:kubectl get pods -n <namespace>

查看网络插件的Pod的详细信息:kubectl describe pod <pod-name> -n <namespace>

查看网络插件的日志信息:kubectl logs <pod-name> -n <namespace>

重启网络插件的Pod:kubectl delete <pod-name> pod -n <namespace>
检查集群的网络配置:kubectl cluster-info dump
检查节点的网络配置:kubectl describe node <node-name>

检查Flannel的日志信息:kubectl logs -n kube-system -l k8s-app=flannel
重启Flannel的Pod:kubectl delete pod -n kube-system -l k8s-app=flannel
检查Calico的日志信息:kubectl logs -n kube-system -l k8s-app=calico-node
重启Calico的Pod:kubectl delete pod -n kube-system -l k8s-app=calico-node
1.3 网络策略故障
Kubernetes中的网络策略(Network Policy)是用于控制容器间网络流量的重要组件之一。网络策略可以定义允许或禁止容器间的网络连接,从而增强了容器间网络的安全性。如果网络策略出现故障,可能会导致容器无法正常通信,网络安全性受到威胁等问题。
查看所有网络策略:kubectl get networkpolicies --all-namespaces
查看网络策略的详细信息:kubectl describe networkpolicy <network-policy-name> -n <namespace>
检查网络策略的规则是否正确:kubectl get networkpolicy <network-policy-name> -n -o yaml
检查容器是否正确标记:kubectl get pods --selector=<label-selector> -n <namespace> -o wide
检查容器的端口是否正确配置:kubectl get pods <pod-name> -n -o yaml
检查节点是否正确配置:kubectl get nodes -o wide
检查网络设备是否正常工作:kubectl logs <network-device-pod-name> -n <namespace>
如果你的Kubernetes集群使用的是Calico网络策略,你可以使用以下命令:
查看所有Calico网络策略:kubectl get networkpolicies.projectcalico.org --all-namespaces
查看Calico网络策略的详细信息:kubectl describe networkpolicy <network-policy-name> -n <namespace>
检查Calico网络策略的规则是否正确:kubectl get networkpolicy <network-policy-name> -n <namespace> -o yaml
检查Calico网络设备是否正常工作:kubectl logs -n kube-system -l k8s-app=calico-node
1.4 DNS 故障
常见原因
以下是几种可能导致DNS故障的情况:
- DNS配置错误:Kubernetes中的DNS服务需要正确配置才能正常工作,例如需要配置正确的域名服务器、搜索域等信息。如果DNS配置存在错误,可能会导致DNS服务无法正常工作。
- DNS版本不兼容:Kubernetes的版本更新可能会导致DNS版本不兼容,从而导致DNS故障。
- 网络连接不稳定:网络连接不稳定可能会导致DNS服务无法正常解析域名。
- 容器网络配置错误:如果容器的网络配置存在错误,可能会导致容器无法正确连接到DNS服务,从而导致DNS故障。
常见问题
当DNS服务出现故障时,可能会出现以下一些常见问题:
- 容器无法正确解析域名:当DNS服务故障时,容器无法正确解析域名,这可能会影响应用程序的正常运行。
- DNS解析延迟:当DNS服务故障时,DNS解析可能会变得缓慢,这可能会导致容器之间的通信延迟。
- 容器网络连接不稳定:当DNS服务故障时,网络连接可能会不稳定,这可能会导致容器之间的连接断开或丢失数据包。
- 为了避免DNS故障导致的问题,需要定期对DNS服务进行检查和维护,确保其正常工作。同时,还需要备份DNS的配置文件,并了解网络设备的故障排除方法,以便快速解决问题。
解决方案
检查网络设备是否连通:可以使用ping命令检查网络设备是否连通,例如:ping <network-device-ip> 如果网络设备无法连通,可能是网络设备的IP地址或网络配置存在问题。
检查网络设备的日志信息:可以通过查看网络设备的日志信息来了解网络设备的工作情况,例如:kubectl logs <network-device-pod-name> -n <namespace>
检查网络设备的配置信息:可以通过查看网络设备的配置信息来了解网络设备是否正确配置,例如:kubectl exec -it <network-device-pod-name> -n <namespace> -- <command> <arguments>
检查网络设备的版本信息:可以通过查看网络设备的版本信息来了解网络设备是否需要升级,例如:kubectl exec -it <network-device-pod-name> -n <namespace> -- <command> <arguments>
检查网络设备的连接状态:可以通过查看网络设备的连接状态来了解网络设备的工作情况,例如:kubectl exec -it <network-device-pod-name> -n <namespace> -- <command> <arguments>
3 纵向解决思路(推荐)
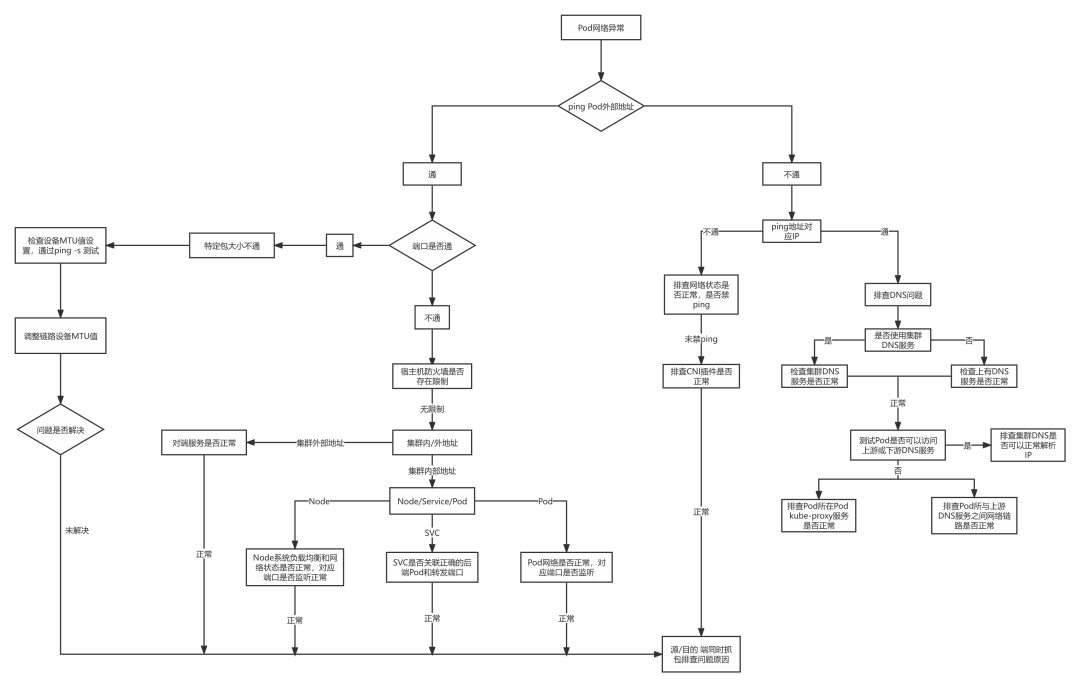
Pod 网络异常
网络异常大概分为如下几类:
- 网络不可达,主要现象为 ping 不通,其可能原因为:
- 源端和目的端防火墙(
iptables,selinux)限制 - 网络路由配置不正确
- 源端和目的端的系统负载过高,网络连接数满,网卡队列满
- 网络链路故障
- 源端和目的端防火墙(
- 端口不可达:主要现象为可以 ping 通,但 telnet 端口不通,其可能原因为:
- 源端和目的端防火墙限制
- 源端和目的端的系统负载过高,网络连接数满,网卡队列满,端口耗尽
- 目的端应用未正常监听导致(应用未启动,或监听为 127.0.0.1 等)
- DNS 解析异常:主要现象为基础网络可以连通,访问域名报错无法解析,访问 IP 可以正常连通。其可能原因为
- Pod 的 DNS 配置不正确
- DNS 服务异常
- pod 与 DNS 服务通讯异常
- 大数据包丢包:主要现象为基础网络和端口均可以连通,小数据包收发无异常,大数据包丢包。可能原因为:
- 可使用
ping -s指定数据包大小进行测试 - 数据包的大小超过了 docker、CNI 插件、或者宿主机网卡的 MTU 值。
- 可使用
- CNI 异常:主要现象为 Node 可以通,但 Pod 无法访问集群地址,可能原因有:
- kube-proxy 服务异常,没有生成 iptables 策略或者 ipvs 规则导致无法访问
- CIDR 耗尽,无法为 Node 注入
PodCIDR导致 CNI 插件异常 - 其他 CNI 插件问题
那么整个 Pod 网络异常分类可以如下图所示:
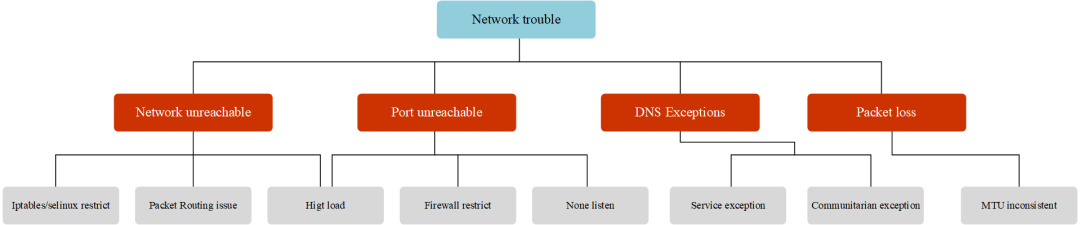
总结:Pod 最常见的网络故障有,网络不可达(ping 不通);端口不可达(telnet 不通);DNS 解析异常(域名不通)与大数据包丢失(大包不通)
二、常用网络排查工具
关于抓包节点和抓包设备的抓包方式
- 抓包节点:通常情况下会在源端和目的端两端同时抓包,观察数据包是否从源端正常发出,目的端是否接收到数据包并给源端回包,以及源端是否正常接收到回包。如果有丢包现象,则沿网络链路上各节点抓包排查。例如,A 节点经过 C 节点到 B 节点,先在 AB 两端同时抓包,如果 B 节点未收到 A 节点的包,则在 C 节点同时抓包。
- 抓包设备:对于 Kubernetes 集群中的 Pod,由于容器内不便于抓包,通常视情况在 Pod 数据包经过的 veth 设备,docker0 网桥,CNI 插件设备(如 cni0,flannel.1 etc..)及 Pod 所在节点的网卡设备上指定 Pod IP 进行抓包。选取的设备根据怀疑导致网络问题的原因而定,比如范围由大缩小,从源端逐渐靠近目的端,比如怀疑是 CNI 插件导致,则在 CNI 插件设备上抓包。从 pod 发出的包逐一经过 veth 设备,cni0 设备,flannel0,宿主机网卡,到达对端,抓包时可按顺序逐一抓包,定位问题节点。
1、tcpdump:
详见 tcpdump使用
捕获流量输出为文件-w 可以将数据包捕获保存到一个文件中以便将来进行分析。这些文件称为 PCAP(PEE-cap)文件,它们可以由不同的工具处理,包括 Wiresharktcpdump port 80 -w capture_file
2.nsenter
3.paping
paping 命令可对目标地址指定端口以 TCP 协议进行连续 ping,通过这种特性可以弥补 ping ICMP 协议,以及 nmap、telnet 只能进行一次操作的的不足;通常情况下会用于测试端口连通性和丢包率。
RedHat/CentOS:yum install -y libstdc++.i686 glibc.i686
4.mtr
mtr 是一个跨平台的网络诊断工具,将 traceroute 和 ping 的功能结合到一个工具中。与 traceroute 不同的是 mtr 显示的信息比起 traceroute 更加丰富:通过 mtr 可以确定网络的条数,并且可以同时打印响应百分比以及网络中各跳跃点的响应时间。
下面是一些常见的mtr命令参数:
-c <count>:设置要发送的数据包数。
mtr -c 10 google.com
-r:显示IP地址而不是主机名。
mtr -r google.com
-n:禁用DNS解析,只显示IP地址。
mtr -n 8.8.8.8
-b:以批处理模式运行,输出结果以可编辑格式打印。
mtr -b google.com > output.txt
-s <packet size>:设置要发送的ICMP数据包大小。
mtr -s 1500 google.com
-t <ttl>:设置初始TTL值。
mtr -t 5 google.com
-u:使用UDP协议而不是默认的ICMP协议。
mtr -u google.com
-T, --tcp:使用TCP SYN数据包而不是ICMP ECHO。使用该选项的话会忽略修改数据包大小的-s、--psize或者PACKETSIZE,因为SYN数据包不包含数据。最简单的示例,就是后接域名或 IP,这将跟踪整个路由。
mtr www.baidu.com
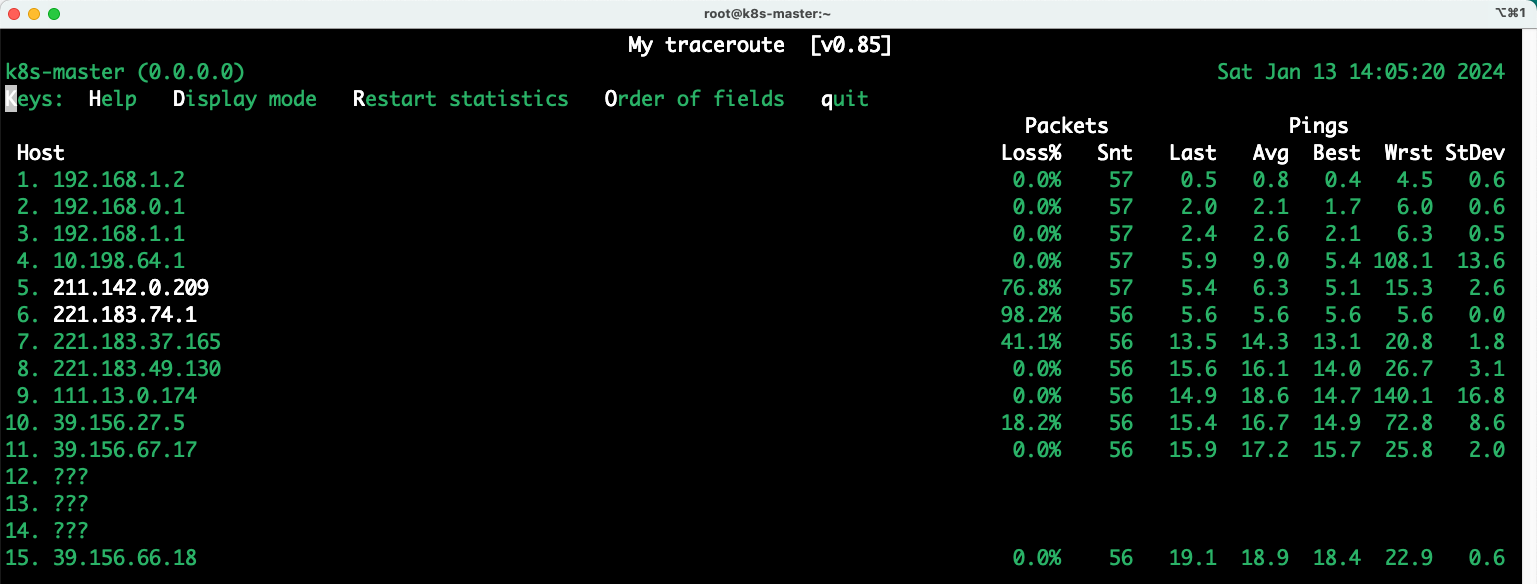
如果需要指定次数,并且在退出后保存这些数据,使用 -r
mtr -r -c 5 www.baidu.com > mtr.log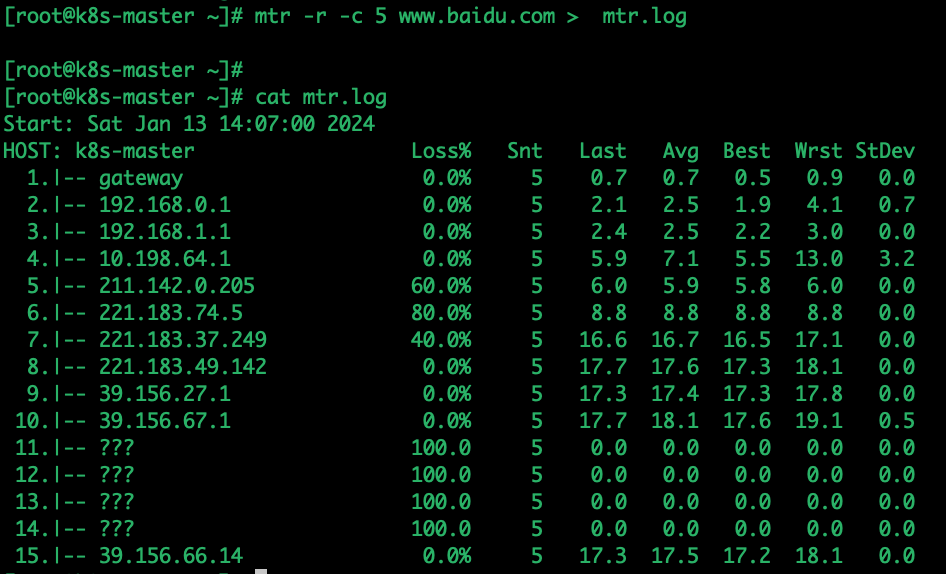
输出结果
Loss%:丢包率。
Snt:已发送的数据包。
Last:最近一次探测到达此地址的时间延迟值(时间单位均是毫秒)
Avg:探测到达此地址时间延迟平均值,计将所有数据相加并除以数据集中的观测次数。
Best:探测到达此地址时间延迟最佳值,通常指数据集中的最小值或最大值,具体取决于分析的问题和目的。
Wrst:探测到达此地址时间延迟最差值,通常指数据集中的最大值或最小值,具体取决于分析的问题和目的。
StDev:标准偏差,是测量数据集中数据离其平均值的距离的一种方式,它告诉我们数据分布的紧密程度。如果标准差较大,则表示数据点不集中于平均值周围;如果标准差较小,表示数据点比较集中,这个值越小延时越稳定。丢包判断:
任一节点的 Loss%(丢包率)如果不为零,则说明这一跳网络可能存在问题。导致相应节点丢包的原因通常有两种。
- 运营商基于安全或性能需求,人为限制了节点的 ICMP 发送速率,导致丢包。
- 节点确实存在异常,导致丢包。可以结合异常节点及其后续节点的丢包情况,来判定丢包原因。
Notes:
- 如果随后节点均没有丢包,则通常说明异常节点丢包是由于运营商策略限制所致。可以忽略相关丢包。
- 如果随后节点也都出现丢包,则通常说明节点确实存在网络异常,导致丢包。对于这种情况,如果异常节点及其后续节点连续出现丢包,而且各节点的丢包率不同,则通常以最后几跳的丢包率为准。如链路测试在第 5、6、7 跳均出现了丢包。最终丢包情况以第 7 跳作为参考。
某个跃点(hop)的位置出现三个问号“???”
这通常表示该节点(路由器)没有响应ICMP(Internet Control Message Protocol)请求。ICMP是用于在IP网络上发送控制消息的协议,而MTR使用ICMP来执行跟踪路由的功能。
有几种可能的原因导致节点不响应ICMP请求:
- 防火墙设置: 节点可能配置了防火墙规则,阻止了ICMP请求的传输。这是一种常见的安全配置,尤其是在公共网络中。
- 网络故障: 有可能存在网络故障,导致节点无法正确处理或响应ICMP请求。这可能是由于网络设备故障、网络拥塞或其他问题引起的。
- 路由策略: 节点可能配置了路由策略,不允许通过MTR的路径进行通信。这是一种安全和隐私保护的做法。
具体案例:首先mtr www.baidu.com
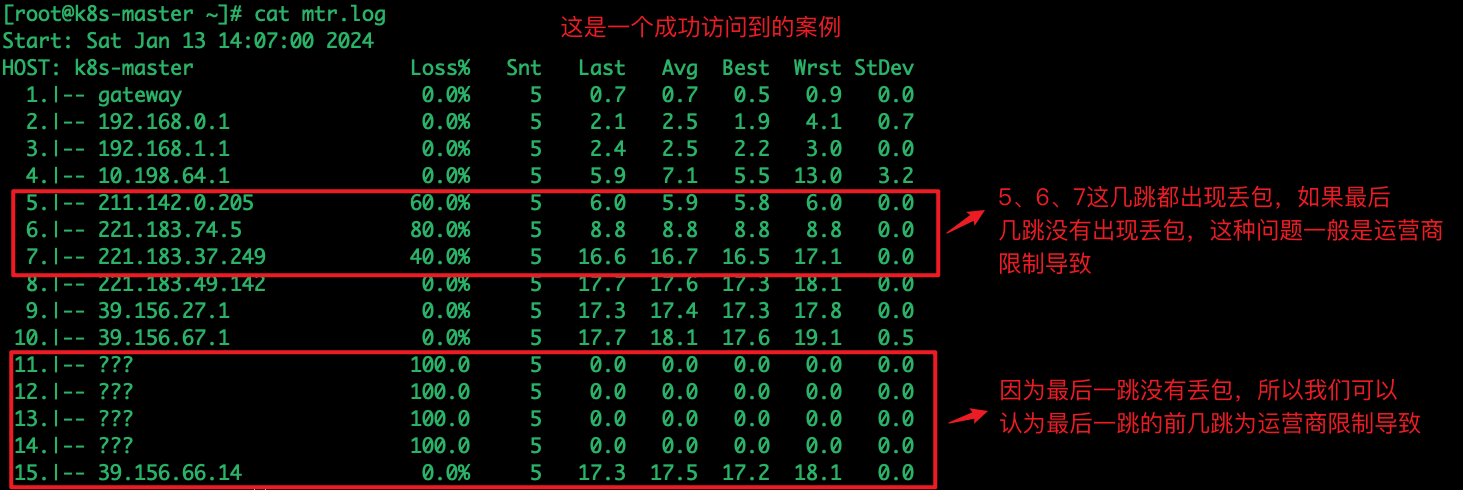
这里我们国内访问:mtr www.onlinesim.io
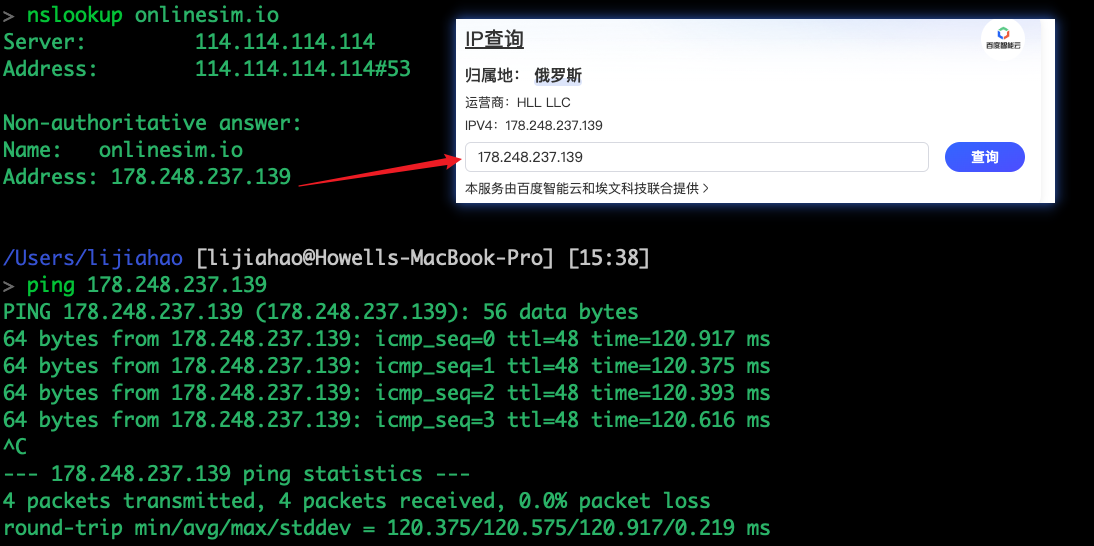
然后mtr测试
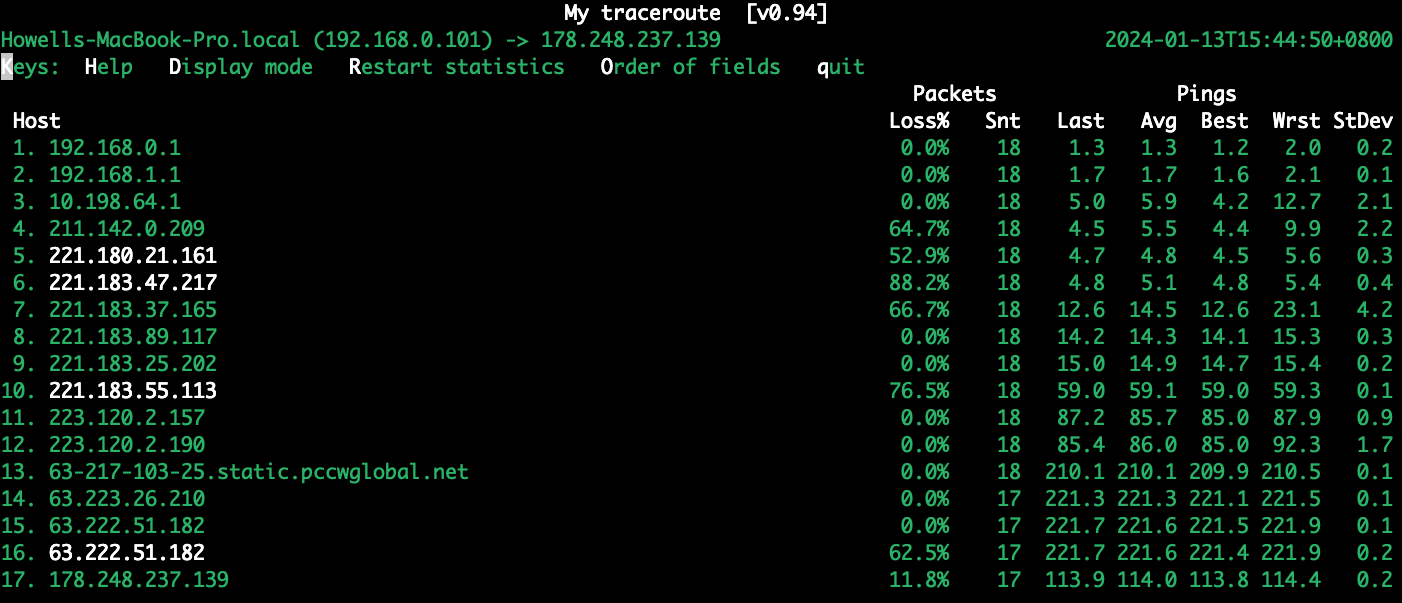
国外最后一跳可能会有少许丢包,这是正常的
延迟判断:
由于链路抖动或其它因素的影响,节点的 Best 和 Worst 值可能相差很大。而 Avg(平均值)统计了自链路测试以来所有探测的平均值,所以能更好的反应出相应节点的网络质量。
而 StDev(标准偏差值)越高,则说明数据包在相应节点的延时值越不相同(越离散)。所以标准偏差值可用于协助判断 Avg 是否真实反应了相应节点的网络质量。
例如,如果标准偏差很大,说明数据包的延迟是不确定的。可能某些数据包延迟很小(例如:25ms),而另一些延迟却很大(例如:350ms),但最终得到的平均延迟反而可能是正常的。所以此时 Avg 并不能很好的反应出实际的网络质量情况。
这就需要结合如下情况进行判断:
- 如果 StDev 很高,则同步观察相应节点的 Best 和 wrst,来判断相应节点是否存在异常。
- 如果 StDev 不高,则通过 Avg 来判断相应节点是否存在异常。
三、Pod 网络排查流程
k8s集群中的网络通信主要有以下几种:
1、同一个pod内的多个容器之间的网络通信
pod自身网络出现问题,会导致pod中的多个容器通信出现异常,具体排查网络组件
2、pod与pod之间的网络通信。
pod与pod之间通信故障是经常会出现的现象,可以排查网络组件Calico和kube-proxy这两个组件
3、pod与Node节点之间的通信故障
当出现此故障时,一般都是Calico网络组件产生了问题,需要排查具体日志
4、Service资源与集群外部的通信
检查网络插件、kube-proxy和服务发现配置等问题
四、案例学习
| 192.168.1.10 | k8s-master | k8s-master 节点 |
| 192.168.1.11 | k8s-node1 | k8s-node1 节点 |
| 192.168.1.12 | k8s-node2 | k8s-node2 节点(本次 nginx 服务 pod 所在 节点) |
- CNI 插件:flannel vxlan
- kube-proxy 工作模式为 iptables
- nginx 服务
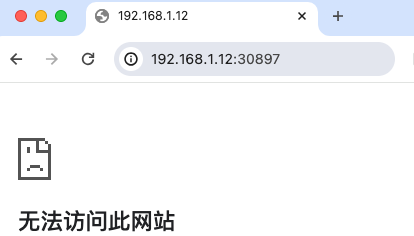
1.外部网络访问nginx service地址不通
问题:使用deployment部署了一个nginx,然后通过service通过NodePort 方式暴露 80端口,名称为nginx-expose,找到pod所在节点上,但是通过映射的30897端口不通

先来熟悉下Service工作逻辑:
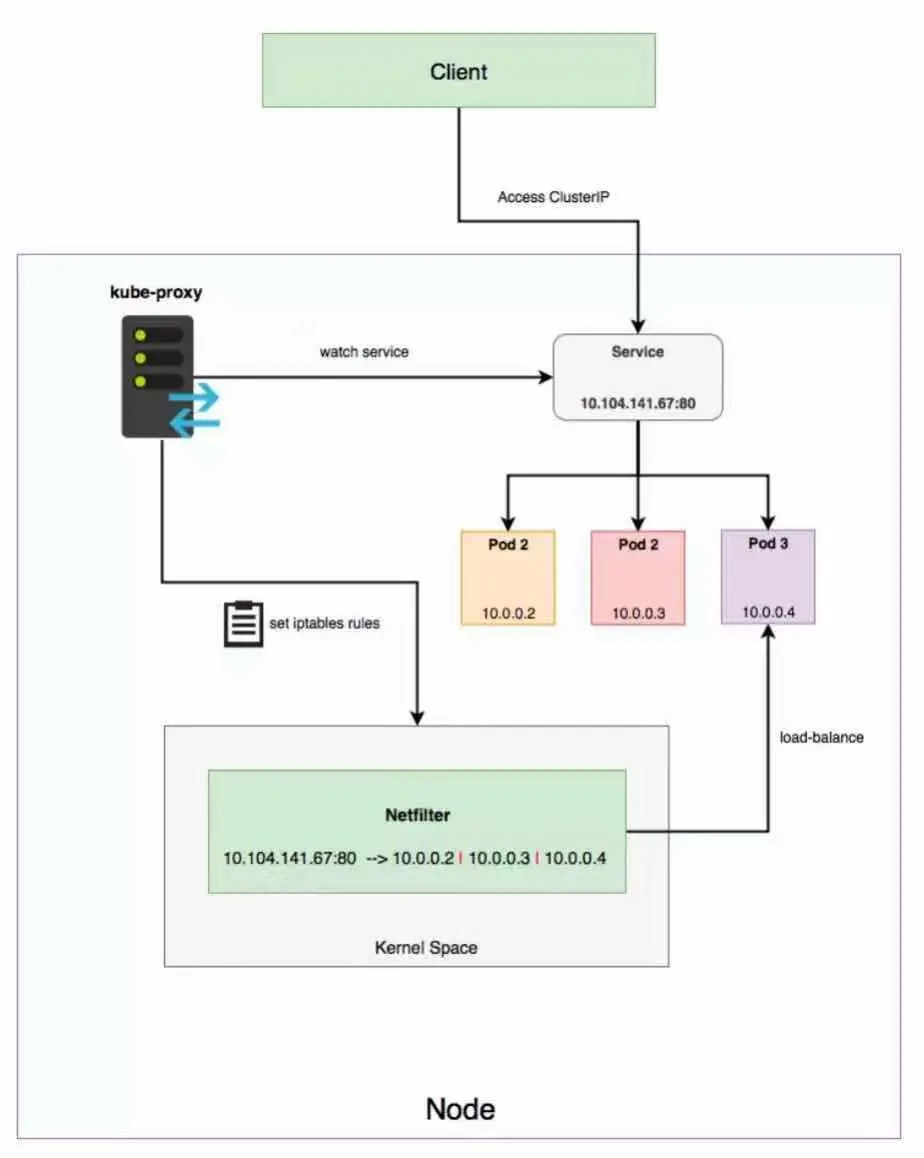
步骤一:是否通过CoreDNS服务访问的内部服务?
如果你是访问的Service名称,需要确保CoreDNS服务已经部署

确认CoreDNS已部署,如果状态不是Running,请检查容器日志进一步查找问题。
测试pod DNS解析是否正常
获取kube-dns pod地址并使用dig或者是nslookup解析,查看是否可以成功解析到service的地址
kubectl get svc -n kube-system
dig -t -A nginx-expose.default.svc.cluster.local @10.96.0.10
nslookup nginx-expose.default.svc.cluster.local 10.96.0.10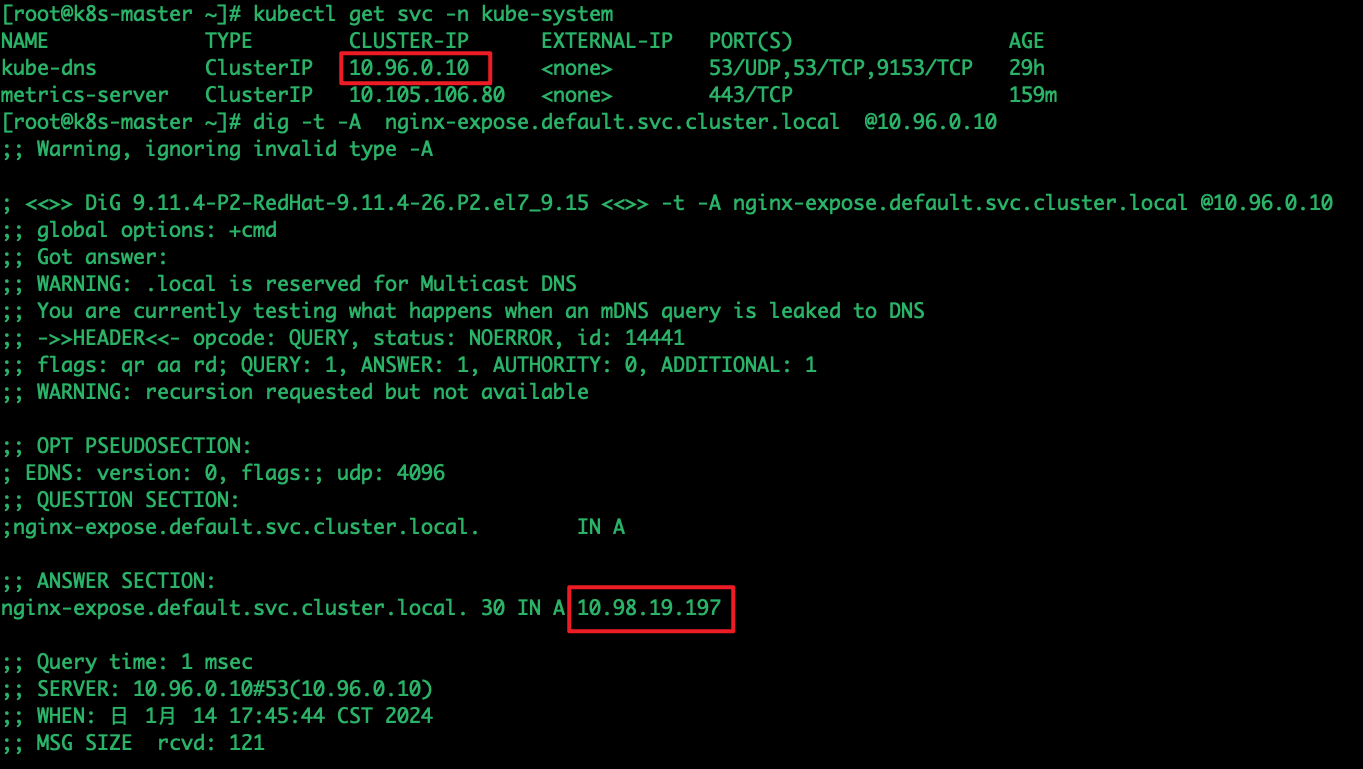

接下来创建一个临时Pod使用nslookup解析相对名称测试下DNS解析是否正常:
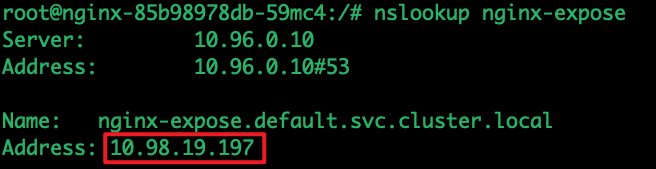
如果你能使用完全限定的名称查找,但不能使用相对名称,则需要检查 /etc/resolv.conf 文件是否正确:

说明:
- nameserver:行必须指定CoreDNS Service,它通过在kubelet设置 --cluster-dns 参加自动配置。
- search :行必须包含一个适当的后缀,以便查找 Service 名称。在本例中,它在本地 Namespace(default.svc.cluster.local)、所有 Namespace 中的 Service(svc.cluster.local)以及集群(cluster.local)中查找服务。
- options :行必须设置足够高的 ndots,以便 DNS 客户端库优先搜索路径。在默认情况下,Kubernetes 将这个值设置为 5。
步骤二:是否通过 Service IP访问
假设可以通过Service名称访问(CoreDNS正常工作),那么接下来要测试的 Service 是否工作正常。从集群中的一个节点,访问 Service 的 IP:

如果 Service 是正常的,你应该看到正确的状态码。如果没有,有很多可能出错的地方,请继续。
步骤二排查问题思路:
思路1:Service 端口配置是否正确?
检查 Service 配置和使用的端口是否正确:
kubectl get svc nginx-expose -o yaml
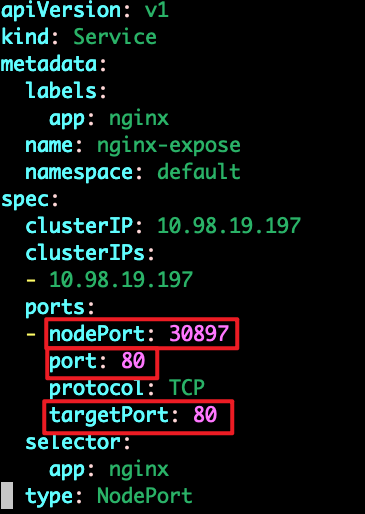
这里重点关注targetPort是否和容器默认暴露端口一致
思路2:Service 是否正确关联到Pod?

在 Kubernetes 系统中有一个控制循环,它评估每个 Service 的选择器,并将结果保存到 Endpoints 对象中。

结果所示, endpoints 控制器已经为 Service 找到了 Pods。但并不说明关联的Pod就是正确的,还需要进一步确认Service 的 spec.selector 字段是否与Deployment中的 metadata.labels 字段值一致。
kubectl get svc nginx-expose -o yaml | grep -A 1 labels:
kubectl get deployment nginx --show-labels
思路3:Pod 是否正常工作?
检查Pod是否正常工作,绕过Service,直接访问Pod IP:
kubectl get pod nginx -o wide

如果不能正常响应,说明容器中服务有问题, 这个时候可以用kubectl logs查看日志或者使用 kubectl exec 直接进入 Pod检查服务。
这里我们可以先通过ksniff抓包进行判断
kubectl sniff nginx-85b98978db-59mc4 -n default

可见,建立TCP三次握手时,服务器主动拒绝连接,这里只能检测pod内container相关问题了
kubectl debug -it nginx-85b98978db-59mc4 --image=nicolaka/netshoot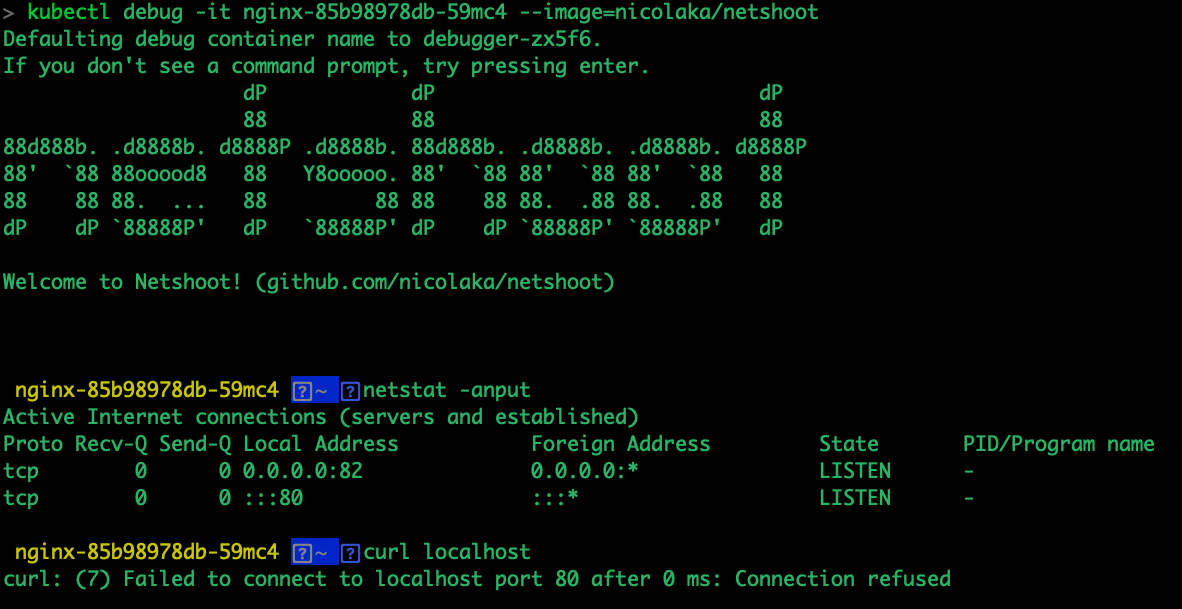
这里发现容器内部居然开了82端口,而不是80端口,最后通过登陆main container后修改nginx相关配置文件/etc/nginx/conf.d/default.conf的默认监听端口,问题才解决,但是希望继续看下后续排错步骤
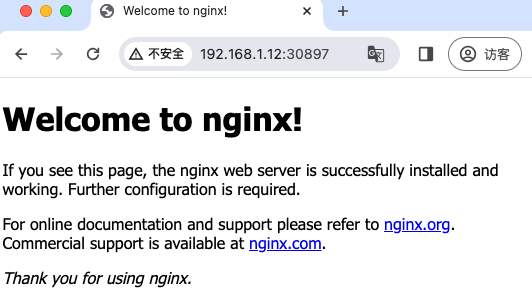
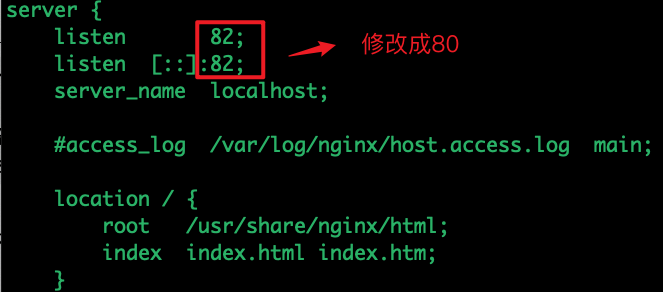
除了本身服务问题外,还有可能是CNI网络组件部署问题,现象是:curl访问10次,可能只有两三次能访问,能访问时候正好Pod是在当前节点,这并没有走跨主机网络。
如果是这种现象,检查网络组件运行状态和容器日志:
kubectl get pods -n kube-flannel -o wide
kubectl -n kube-flannel logs kube-flannel-ds-4zwrm
思路4:kube-proxy 组件正常工作吗?
如果到了这里,你的 Service 正在运行,也有 Endpoints, Pod 也正在服务。
接下来就该检查负责 Service 的组件kube-proxy是否正常工作。
登陆pod所在节点,确认 kube-proxy 运行状态:
ps -ef |grep kube-proxy

如果有进程存在,下一步确认它有没有工作中有错误,比如连接主节点失败。
要做到这一点,必须查看日志。查看日志方式取决于K8s部署方式,如果是kubeadm部署,直接查看业务pod所在节点上的kube-proxy日志:
kubectl -n kube-system logs kube-proxy-krqkb
如果是二进制方式部署:journalctl -u kube-proxy
思路5:kube-proxy 是否在写 iptables 规则?
kube-proxy 的主要负载 Services 的 负载均衡 规则生成,默认情况下使用iptables实现,检查一下这些规则是否已经被写好了。
iptables-save | grep nginx-expose

如果你已经讲代理模式改为IPVS了,可以通过ipvsadm -ln方式查看
2.k8s pod之间访问不通
这种问题范围也比较大,排查思路具体如下
1、pod 与所在宿主机网络不通
2、pod 与同主机 pod 网络不通
3、pod 与跨主机网络不通
5、pod 通过 svc 访问 pod 网络不通(这种和上一种问题类似,在这里就不讲了)
这里以跨主机网络问题为例进行讲解
问题:这里我们跑一个busybox在另一台node上,想要通过跨节点方式访问nginx的服务,但是两个node网络不通,为了模拟实验故障,我们将nginx所在的节点上的flannel.1关闭:ifconfig down flannel.1,并将nginx内部默认监听端口修改成82
kubectl run busybox --image=busybox -- sleep 36000

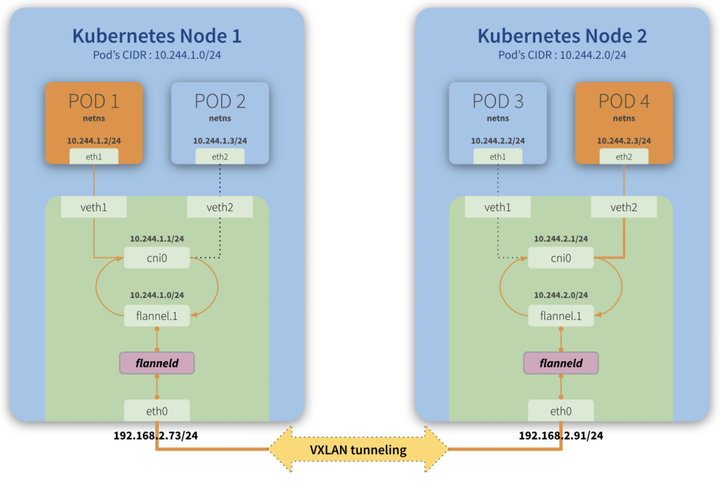
这里先给一张网络拓扑图感受下
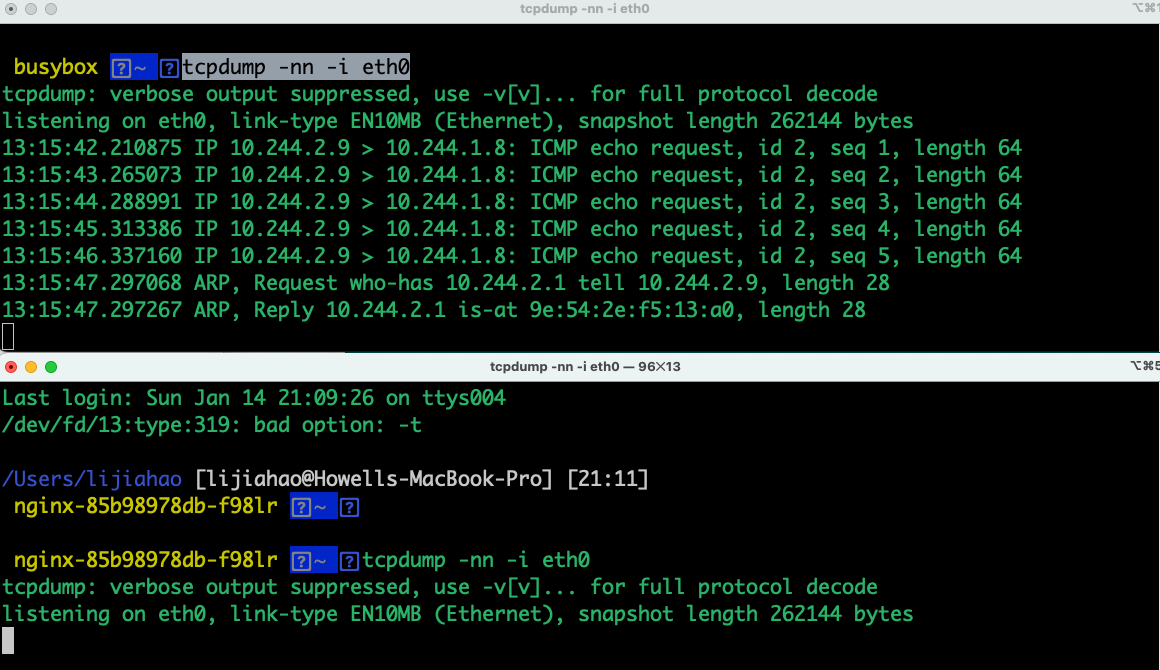
使用netshoot进入容器,两端同时抓包,此时显示只有busybox发送包,nginx所在的pod没有包信息
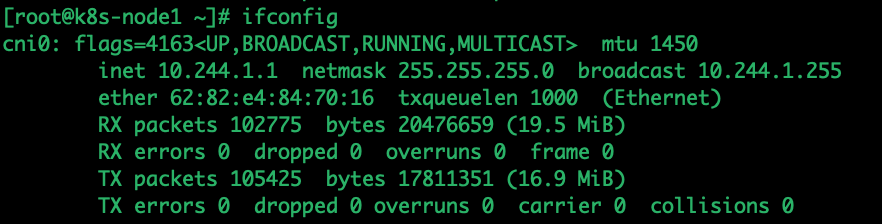
此时我们退一步,尝试ping nginx pod所在节点cni0接口IP地址
这里发现依然没有回应。那么问题继续往前找
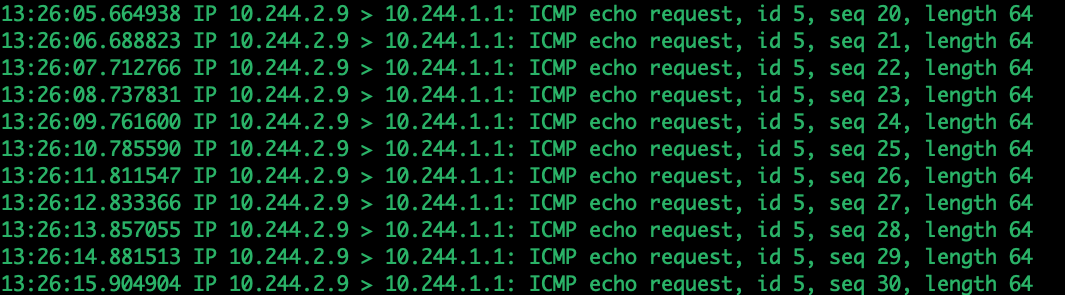
此时,再尝试下ping nginx pod所在节点的ip地址,发现有回应了

那么基本可以确定是nginx pod所在节点的flannel.1接口出现问题了,在nginx pod所在node,使用过ifconfig发现flannel.1消失不见
再恢复之前,我们先看下路由规则,busybox pod所在节的路由规则将目标流量发送给了flannel.1进行udp封装,到达对面网卡后进行拆封,相同node中pod路由只需要经过cni0网卡即可
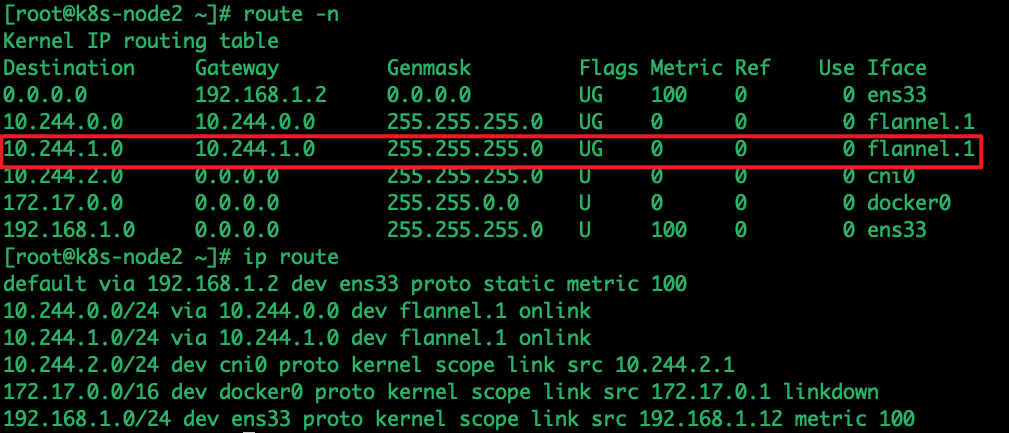

然而在nginx所在的node上面,flannel.1接口找不到,应该是挂掉了,路由规则也没有flannel.1
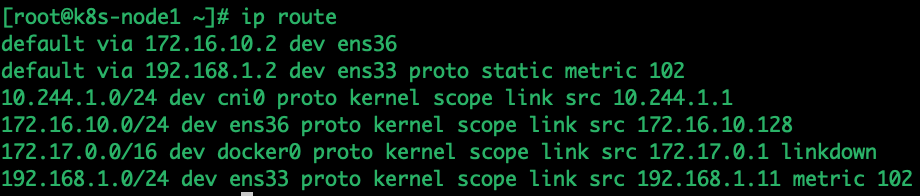
将nginx所在node上的flannel pod删除掉,发现重新恢复了!


此时再用ping进行测试,ping成功
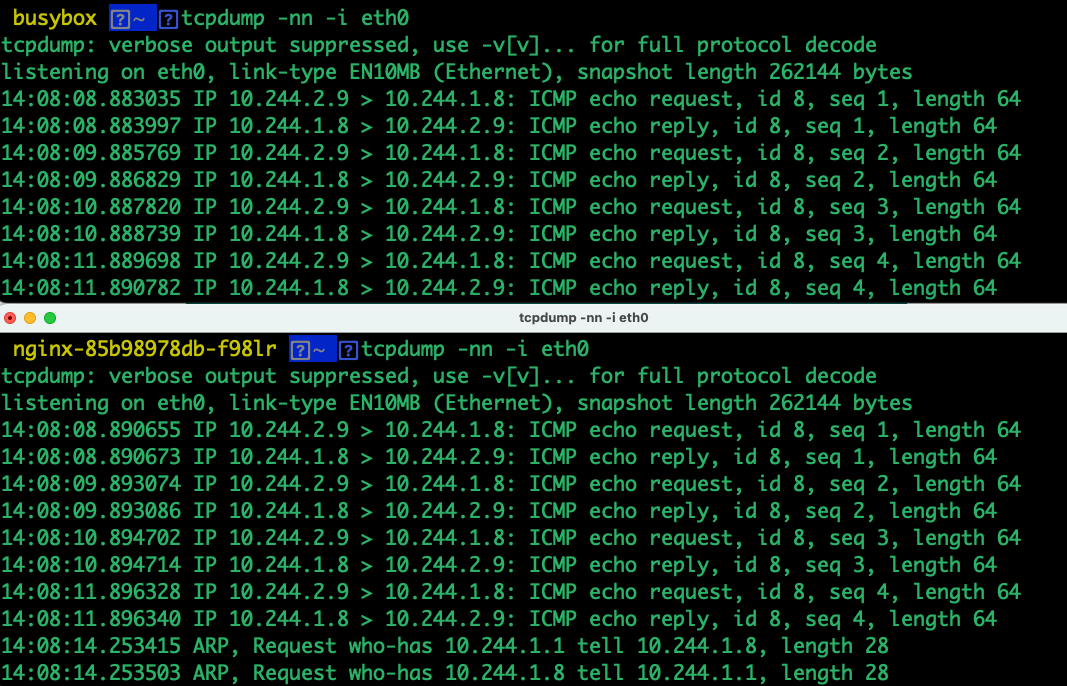
上面的方法可以使用直接登陆目标所在的node,然后获取接口路径,分别在cni0、flannel.1、ens33上双向侦听网络流量状况
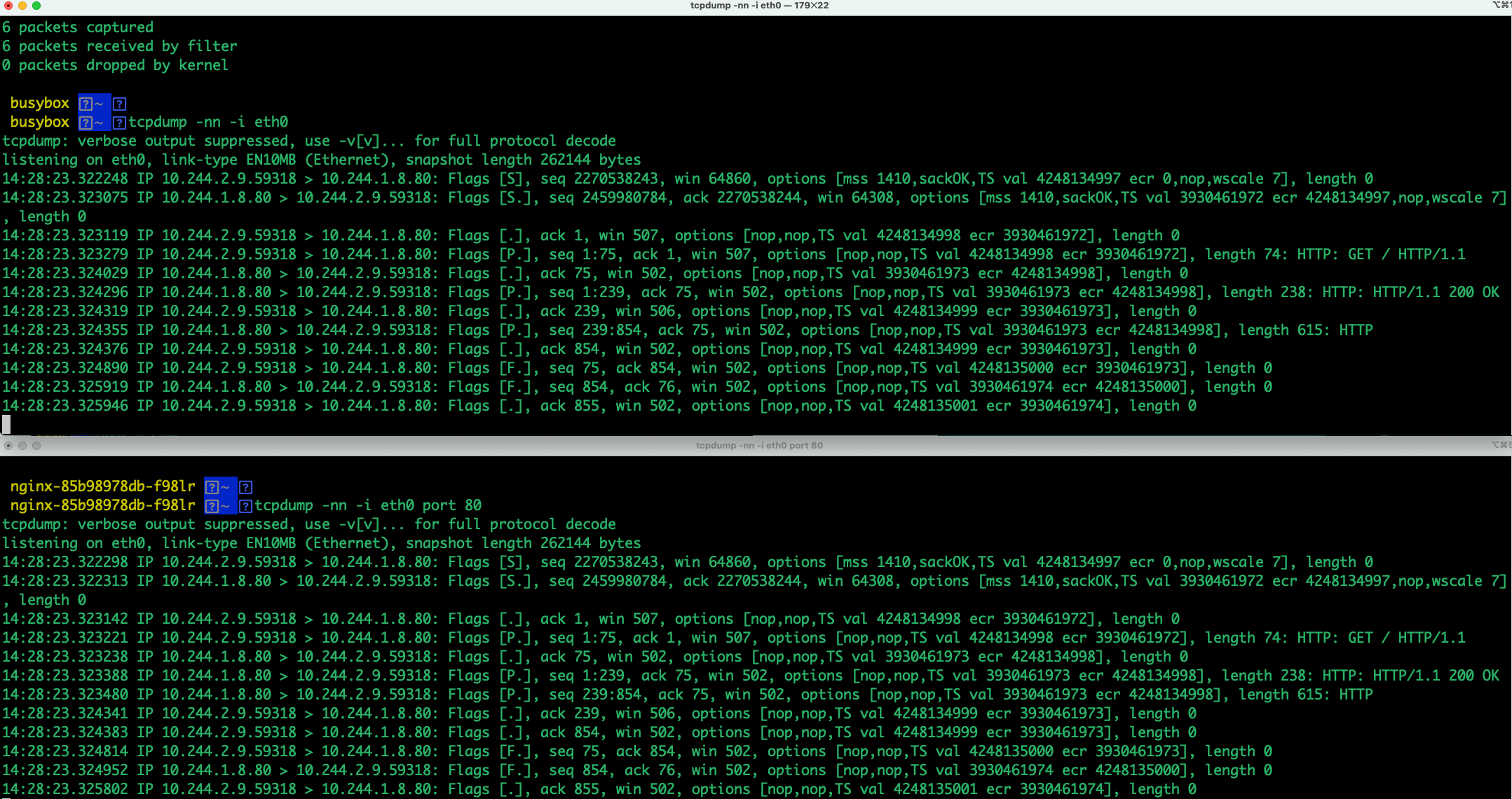
解决了ping的问题后,下面解决TCP端口不通问题,如果curl nginx的podIP,网络监测TCP没有成功握手
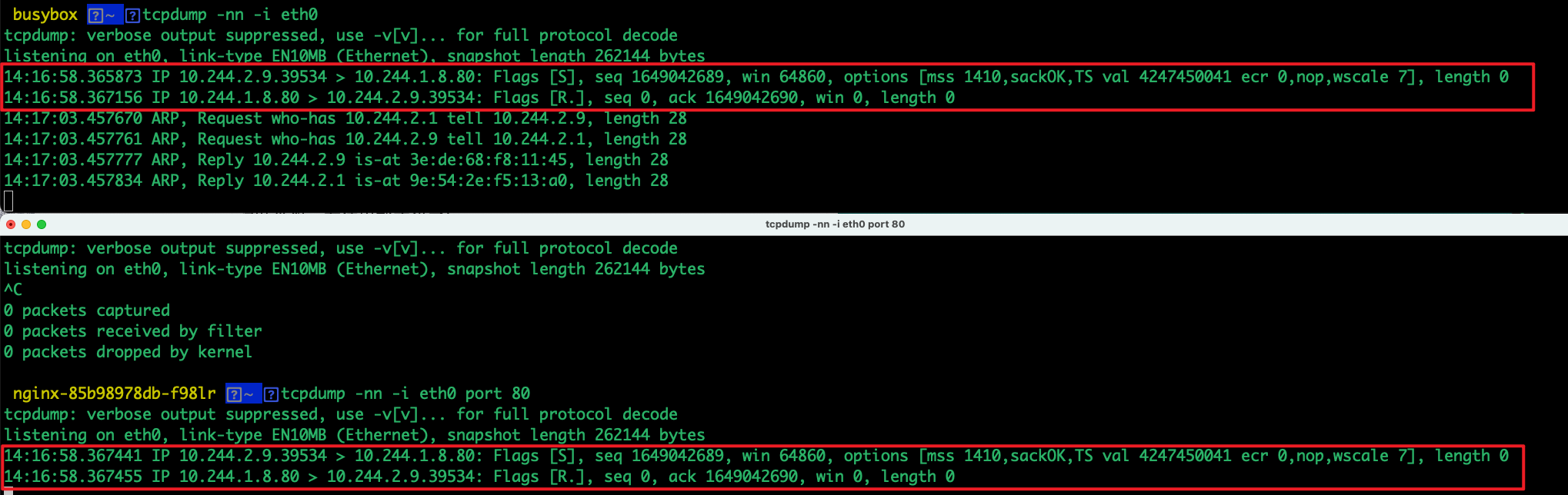
此时,我们在外面网卡设备监听流量分析,两边流量其实是通的,只是被拒绝掉了,所以只需要进入nginx 所在的pod中差错即可,若pod是通过service访问另外的pod,根据上个案例查错即可
下面是TCP握手成功后流量展示
发布者:LJH,转发请注明出处:https://www.ljh.cool/39758.html