
pod 是什么
Pod 是一组互相协作的容器,是我们可以在 Kubernetes 中创建和管理的最小可部署单元。同一个 pod 内的容器共享网络和存储,并且作为一个整体被寻址和调度。当我们在 Kubernetes 中创建一个 pod 会创建 pod 内的所有容器,并且将容器的所有资源都被分配到一个节点上。
为什么需要 pod
思考以下问题,为什么不直接在 kubernetes 部署容器?为什么需要把多个容器视作一个整体?为什么不使用同一个容器内运行多个进程的方案?
当一个应用包含多个进程且通过IPC方式通讯,需要运行在同一台主机。如果部署在 kubernetes 环境进程需要运行在容器内,所以可能考虑方案之一是把多个进程运行在同一个容器内以实现类似在同一个主机的部署模式。但是 container 的设计是每个容器运行一个单独的进程,除非进程本身会创建多个子进程,当然如果你选择在同一个容器内运行多个没有联系的进程的话,那么需要自己来管理其他进程,包括每个进程的生命周期(重启挂掉的进程)、日志的切割等。如果多个进程都在标准输出和标准错误输出上输出日志,就会导致日志的混乱,因此 docker 和 kubernetes 希望我们在一个容器内只运行一个进程。
排除在同一个容器内运行多个进程的方案后,我们需要一个更高层级的组织结构实现把多个容器绑定在一起组成一个单元,这就是 pod 概念的由来,Pod 带来的好处:
- Pod 做为一个可以独立运行的服务单元,简化了应用部署的难度,以更高的抽象层次为应用部署管提供了极大的方便。
- Pod 做为最小的应用实例可以独立运行,因此可以方便的进行部署、水平扩展和收缩、方便进行调度管理与资源的分配。
- Pod 中的容器共享相同的数据和网络地址空间,Pod 之间也进行了统一的资源管理与分配。
pause/Infra 容器
因为容器之间是使用 Linux Namespace 和 cgroups 隔开的,所以 pod 的实现需要解决怎么去打破这个隔离。为了实现同 pod 的容器可以共享部分资源,引入了 pause 容器。 pause 容器的镜像非常小,运行着一个非常简单的进程。它几乎不执行任何功能,启动后就永远把自己阻塞住。每个 Kubernetes Pod 都包含一个 pause 容器, pause 容器是 pod 内实现 namespace 共享的基础。
假设现在有一个 Pod,它包含两个容器(A 和 B),K8S 是通过让他们加入(join)另一个第三方容器的 network namespace 实现的共享,而这个第三方容器就是 pause 容器。
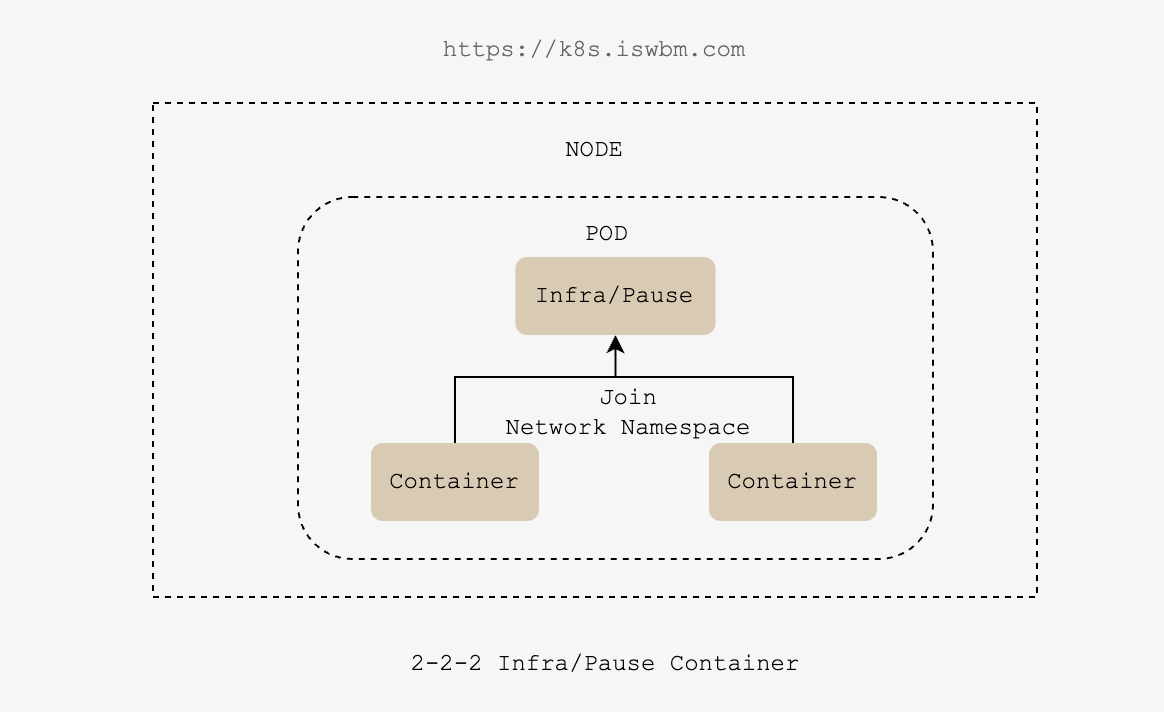

没有 pause 容器,那么 A 和 B 要共享网络,要不就是 A 加入 B 的 network namespace,要嘛就是 B 加入 A 的 network namespace, 而无论是谁加入谁,只要 network 的 owner 退出了,该 Pod 里的所有其他容器网络都会立马异常,这显然是不合理的。
反过来,由于 pause 里只有是挂起一个容器,里面没有任何复杂的逻辑,只要不主动杀掉 Pod,pause 都会一直存活,这样一来就能保证在 Pod 运行期间同一 Pod 里的容器网络的稳定。
我们在同一 Pod 里所有容器里看到的网络视图,都是完全一样的,包括网络设备、IP 地址、Mac 地址等等,因为他们其实全是同一份,而这一份都来自于 Pod 第一次创建的这个 Infra container。
由于所有的业务容器都要依赖于 pause 容器,因此在 Pod 启动时,它总是创建的第一个容器,可以说 Pod 的生命周期就是 pause 容器的生命周期。
手工模拟 Pod
从上面我们已经知道,一个 Pod 从表面上来看至少由一个容器组成,而实际上一个 Pod 至少要有包含两个容器,一个是业务容器,一个是 pause 容器。
理解了这个模型,我们就可以用以前熟悉的 docker 容器,手动创建一个真正意义上的 Pod。
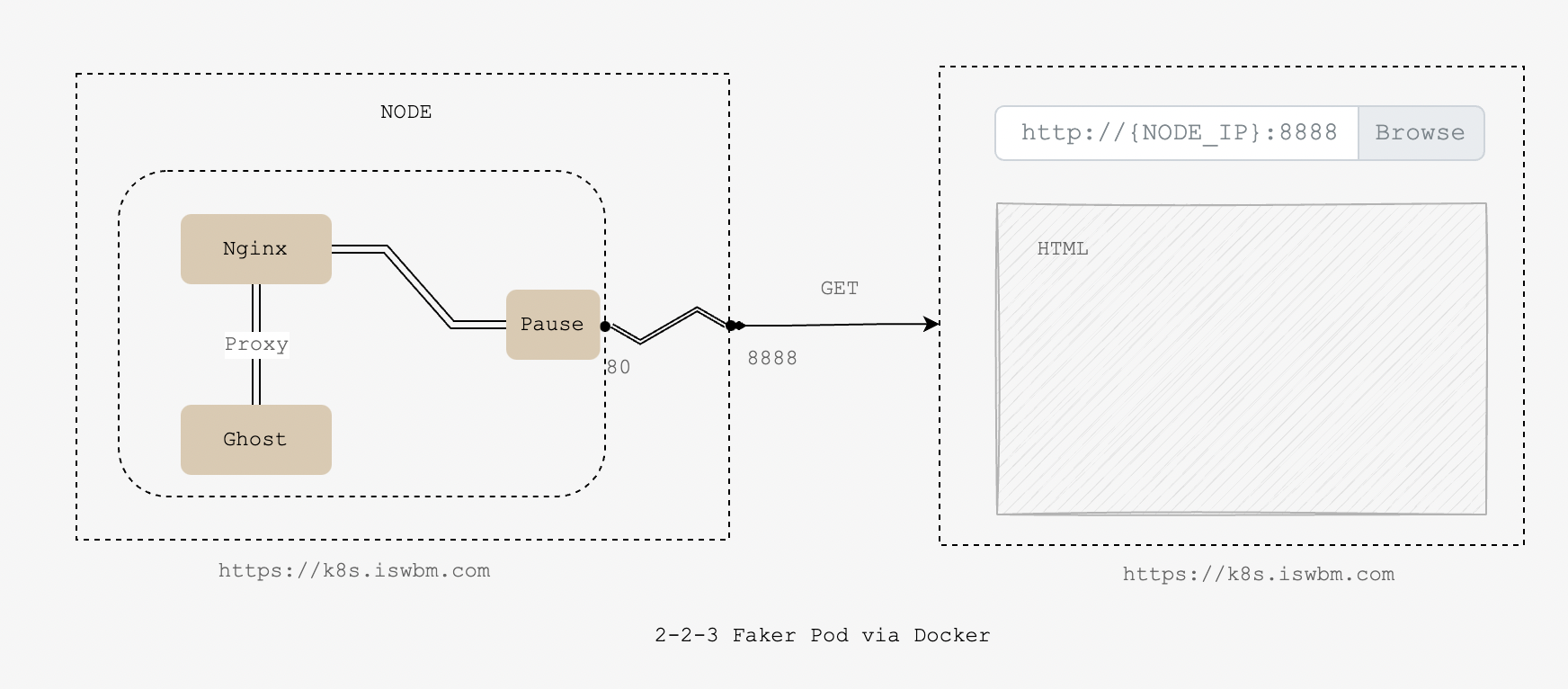
1、创建 pause 容器
使用 docker run 加如下参数:
--name:指定 pause 容器的名字,fake_k8s_pod_pause-p 8888:80:将宿主机的 8888 端口映射到容器的 80 端口
sudo docker run -d -p 8888:80 \
--ipc=shareable \
--name fake_k8s_pod_pause \
registry.cn-hangzhou.aliyuncs.com/google_containers/pause:3.62、创建 nginx 容器
创建容器之前先准备一下 nginx.conf 配置文件
cat <<EOF >> nginx.conf
error_log stderr;
events { worker_connections 1024; }
http {
access_log /dev/stdout combined;
server {
listen 80 default_server;
server_name iswbm.com www.iswbm.com;
location / {
proxy_pass http://127.0.0.1:2368;
}
}
}
EOF然后运行如下命令创建名字 fake_k8s_pod_nginx 的 nginx 容器
sudo docker run -d --name fake_k8s_pod_nginx \
-v `pwd`/nginx.conf:/etc/nginx/nginx.conf \
--net=container:fake_k8s_pod_pause \
--ipc=container:fake_k8s_pod_pause \
--pid=container:fake_k8s_pod_pause \
nginx其中 -v 参数是将宿主机上的 nginx.conf 文件挂载给 nginx 容器
除此之外,还有另外三个核心参数:
--net:指定 nginx 要 join 谁的 network namespace,当然是前面创建的fake_k8s_pod_pause
--ipc:指定 ipc mode, 一样指定前面创建的fake_k8s_pod_pause
--pid:指定 nginx 要 join 谁的 pid namespace,照旧是前面创建的fake_k8s_pod_pause
3、创建 ghost 容器
有了 nginx 还不够,还需要有人提供网页的数据,这里使用 ghost 这个博客应用,参数和上面差不多,这里不再赘述。
sudo docker run -d --name ghost \
--net=container:fake_k8s_pod_pause \
--ipc=container:fake_k8s_pod_pause \
--pid=container:fake_k8s_pod_pause \
daocloud.io/ghost到这里,我就纯手工模拟出了一个符合 K8S Pod 模型的 “Pod” ,只是它并不由 K8S 进行管理。
这个 “Pod” 由一个 fake_k8s_pod_pause 容器(负责提供可稳定共享的命名空间)和两个共享 fake_k8s_pod_pause 容器命名空间的两业务容器。
访问 “Pod” 服务
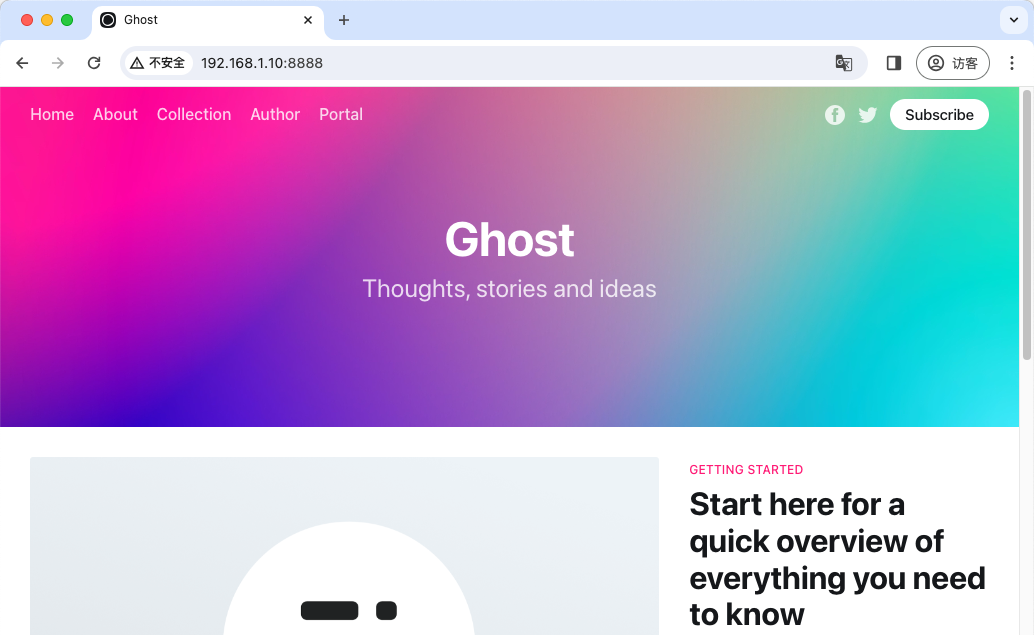
通过 localhost:8080 访问 ghost 页面,那么应该能够看到 ghost 通过 Nginx 代理运行,因为 pause、nginx 和 ghost 容器之间共享 network namespace,如下图所示:
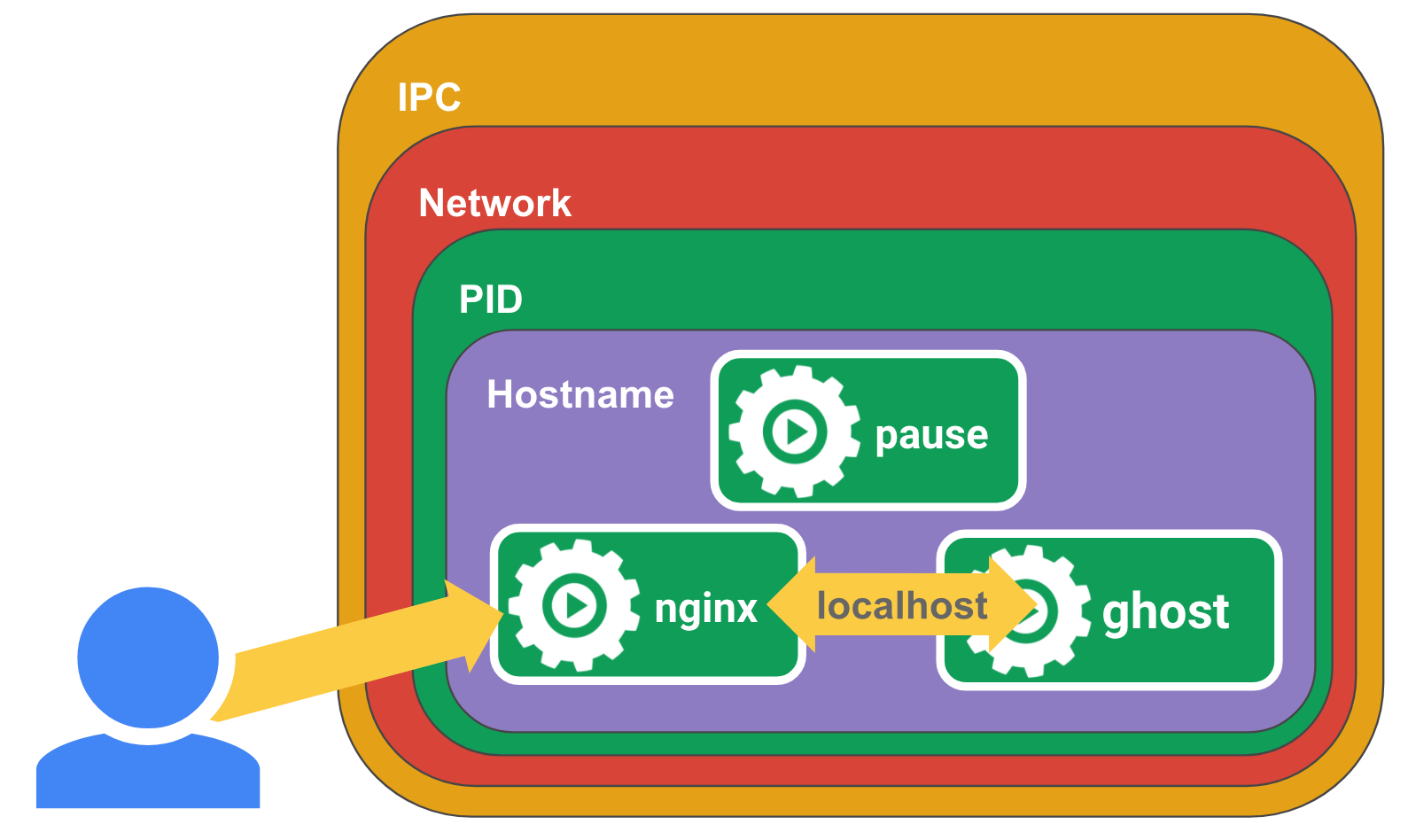
创建真正的 Pod
刚才在 K8S 生态之外,单纯使用 Docker 创建了三个容器(Pause、Nginx、Ghost),这三个容器的的组合,在 K8S 中称之为 Pod。
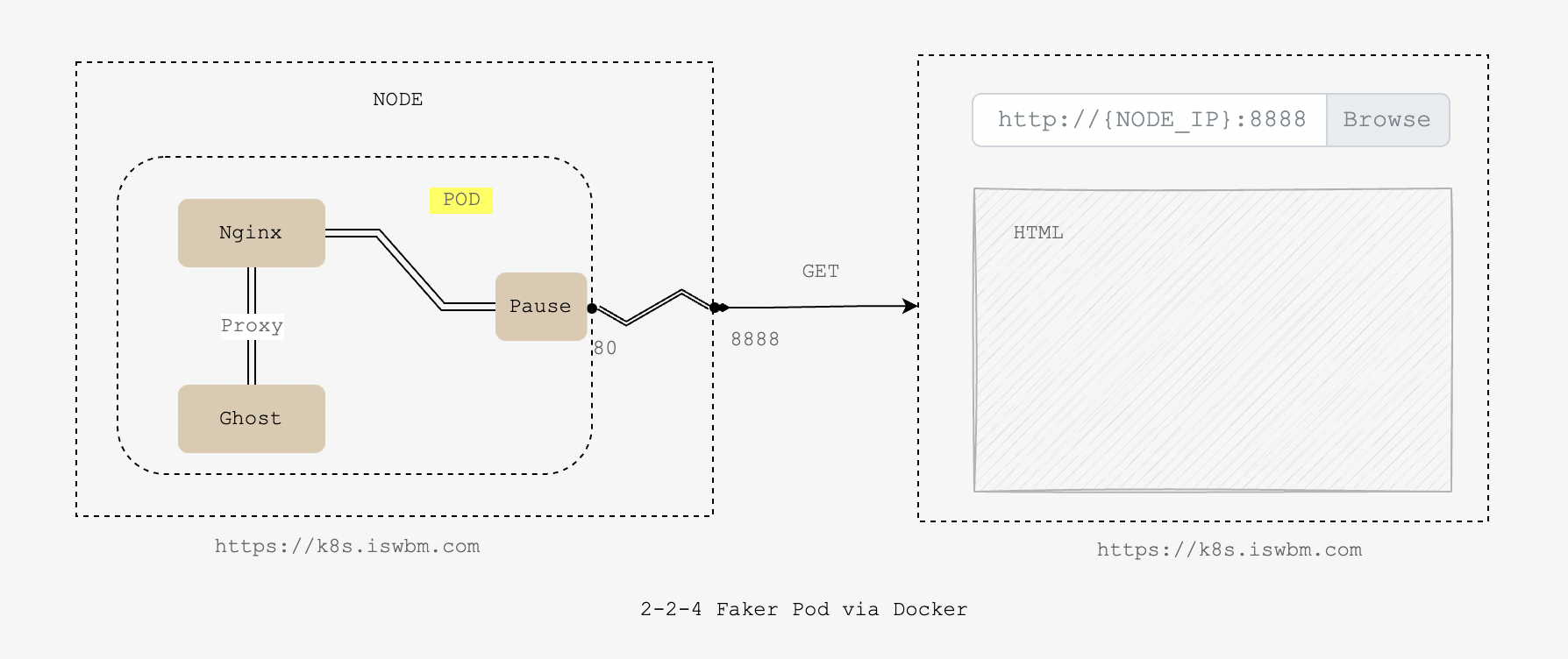
如果没有 K8S 的 Pod ,你启动一个 ghost 博客服务,你需要手动创建三个容器,当你想销毁这个服务时,同样需要删除三个容器。
而有了 K8S 的 Pod,这三个容器在逻辑上就是一个整体,创建 Pod 就会自动创建三个容器,删除 Pod 就会删除三个容器,从管理上来讲,方便了不少。
这正是 Pod 存在的一个根本意义所在。
下面创建一个像上面一样的博客应用
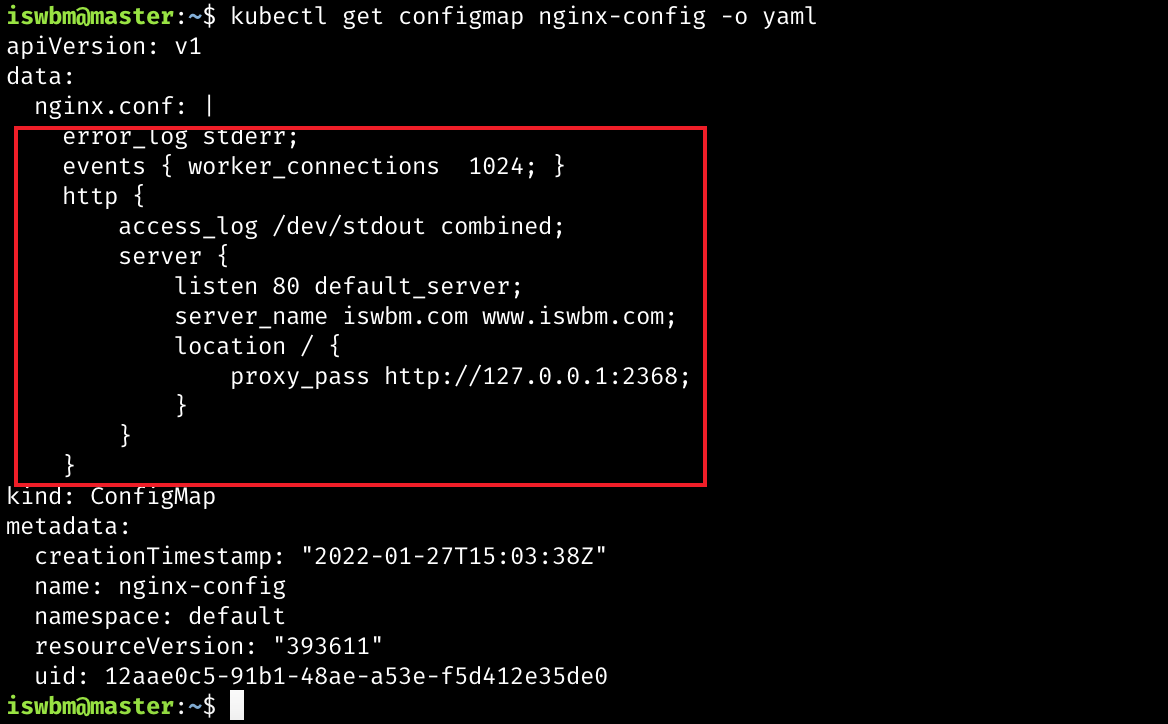
1、创建 ConfigMap
kubectl create configmap nginx-config --from-file=nginx.conf查看 nginx.conf 文件中的内容
2、创建 Pod
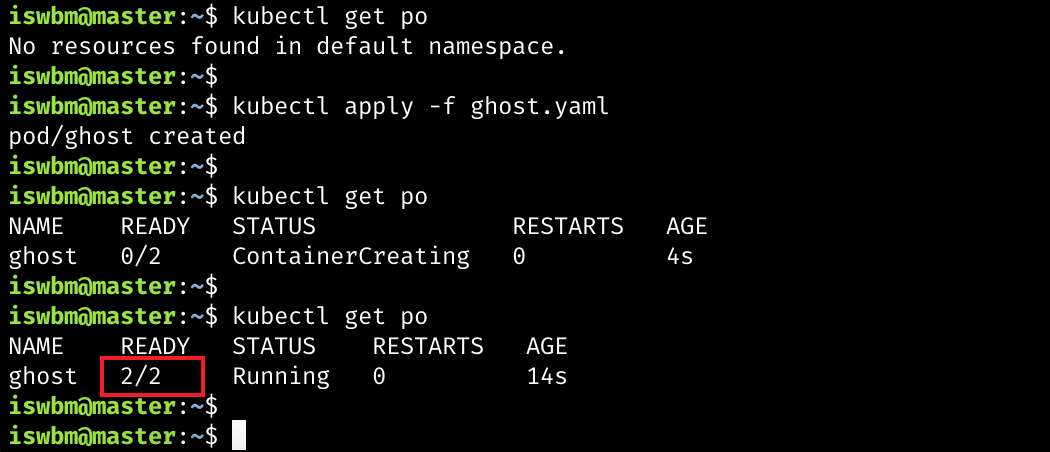
接着执行如下命令创建一个 ghost.yaml 文件
cat <<EOF >> ghost.yaml
apiVersion: v1
kind: Pod
metadata:
name: ghost
namespace: default
spec:
containers:
- image: nginx
imagePullPolicy: IfNotPresent
name: nginx
ports:
- containerPort: 80
protocol: TCP
hostPort: 8888
volumeMounts:
- mountPath: /etc/nginx/
name: nginx-config
readOnly: true
- image: daocloud.io/ghost
name: ghost
volumes:
- name: nginx-config
configMap:
name: nginx-config
EOF然后直接 apply 该文件就可以创建一个 ghost 服务,从输出可以看到这里的 READY 变成了 2/2,意思是该 Pod 总共包含 2 个容器,目前已经全部准备就绪。
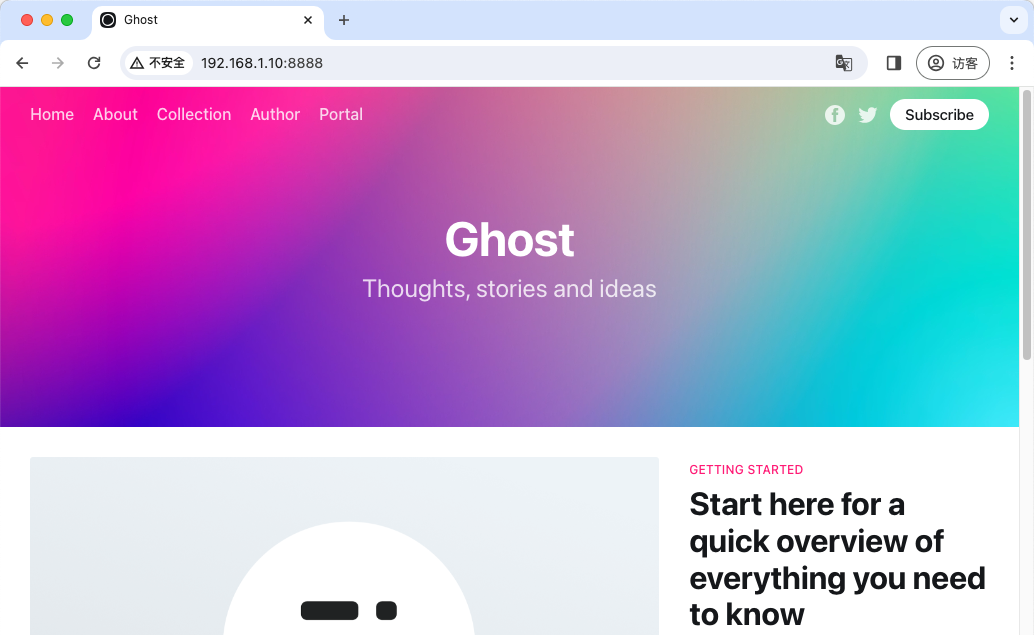
此时再去访问
pod 常用方式
pod 使用方式可以被分为两种类型:
- pod 内只运行一个容器。这种情况可把 pod 视为容器的包装器,kubernetes 通过管理 pod 方式管理容器;
- pod 内运行多个需要共享资源紧密协作的容器。如下图所示,两个容器通过 Volume 共享文件,Filer Puller 从远端更新文件,Web Server 负责文件的展示。
是否把两个容器分配在不同或同一个 pod,通常需要考虑以下几点:
- 它们是否有必要运行在同一个 kubernetes 节点?
- 它们代表一个整体,还是独立的组成部分?
- 它们是否有必要整体扩缩容?
pod 的生命周期
Pod 创建完成后,遵循定义的生命周期,从 Pending 阶段开始,如果 pod 内至少一个容器启动正常,则进入 Running,然后根据 Pod 中的任何容器是否因故障终止而进入 Succeeded 或 Failed 阶段,pod 在其生命周期可能处于以下几种状态
- Pending: Pod 已被 Kubernetes 集群接受,但一个或多个容器尚未准备好运行。这包括 Pod 等待调度所花费的时间以及通过网络下载容器镜像所花费的时间。
- Running: Pod 已绑定到一个节点,并且所有容器都已创建。至少有一个容器仍在运行,或者正在启动或重新启动过程中。
- Succeeded: Pod 中的所有容器都已成功终止,不会重新启动。
- Failed:Pod 中的所有容器都已终止,并且至少有一个容器因故障而终止。也就是说,容器要么以非零状态退出,要么被系统终止。
- Unknown: 由于某种原因,无法获取 Pod 的状态。此阶段通常是由于与应该运行 Pod 的节点通信时出错而发生。
pod 创建流程
所有的 Kubernetes 组件 Controller, Scheduler, Kubelet 都使用 Watch 机制来监听 API Server,来获取对象变化的事件,创建 pod 的大致流程如下:
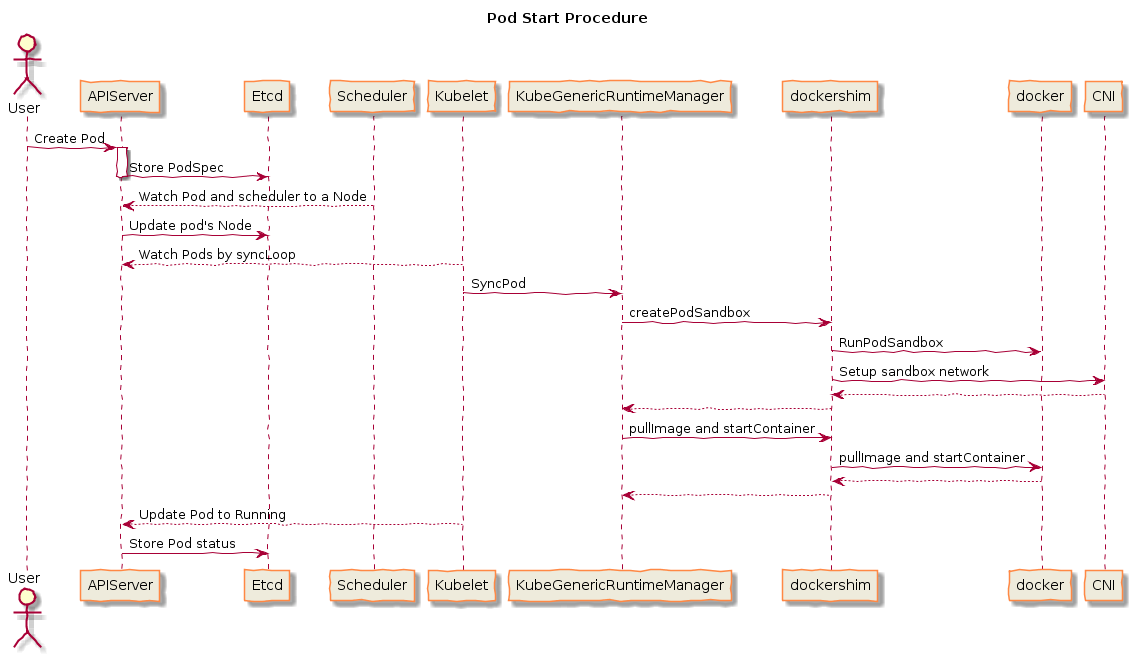
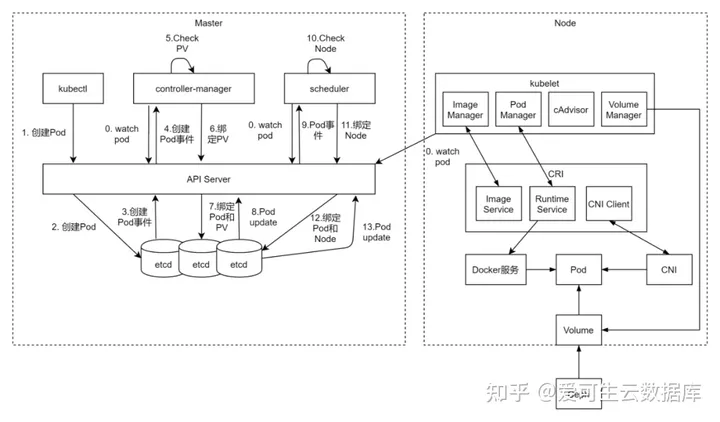
1、用户通过 REST API 提交 Pod`描述文件到 API Server;
API Server 将 Pod 对象的信息存入 Etcd;
Pod 的创建会生成事件,返回给 API Server;
2、Controller-manager 监听到事件;
Pod 如果需要要挂载盘,Controller 会检查是否有满足条件的 PV;
若满足条件的 PV,Controller 会绑定 Pod 和 PV,将绑定关系告知 API Server;
API Server 将绑定信息写入 Etcd;
生成 Pod Update 事件;
3、Scheduler 监听到 Pod Update 事件;
Scheduler 会为 Pod 选择 Node;
如有满足条件的 Node,Scheduler 会绑定 Pod 和 Node,并将绑定关系告知 API Server;
API Server 将绑定信息写入 Etcd;
生成 Pod Update 事件;
3、Scheduler 监听到 Pod Update 事件;
Scheduler 会为 Pod 选择 Node;
如有满足条件的 Node,Scheduler 会绑定 Pod 和 Node,并将绑定关系告知 API Server;
API Server 将绑定信息写入 Etcd;
生成 Pod Update 事件;
4、Kubelet 监听到 Pod Update 事件,创建 Pod;下面 4.1、4.2、4.3步骤为同时进行
4.1:Kubelet 通过 Volume Manager,调用CSI,将盘挂载到 Node 同时挂载到 Pod;
4.2:kubelet通过cAdvisor监控pod情况
4.3:Kubelet 通过ImageManager和PodManager告知调用CRI ,下面 4.3.1、4.3.2、4.3.3步骤为同时进行
4.3.1:CRI通过 Kubelet ImageManager服务调用,从而继续调用ImageService下载镜像;
4.3.2:CRI 通过Kubelet PodManager服务调用,从而继续调用RuntimeService调用dockerd启动容器;
4.3.3:CRI 通过CNI Client 调用 CNI(容器网络接口) 配置容器网络;发布者:LJH,转发请注明出处:https://www.ljh.cool/39671.html