
如果未接触过docker网络模式,建议先去理解docker网络
flannel 插件的基本介绍
Flannel是CoreOS维护的一个网络组件,Flannel为每个Pod提供全局唯一的IP,Flannel使用ETCD来存储Pod子网与Node IP之间的关系。flanneld守护进程在每台主机上运行,并负责维护ETCD信息和路由数据包。
项目地址:https://github.com/coreos/flannel
YAML地址:https://raw.githubusercontent.com/coreos/flannel/master/Documentation/kube-flannel.yml
部署前有两处可能需要调整:
kube-flannel.yml
net-conf.json: |
{
"Network": "10.244.0.0/16",
"Backend": {
"Type": "vxlan"
}
}1、Network:指定Pod IP分配的网段,与controller-manager配置的保持一样。
- kubeadm部署controller-manager配置文件所在位置:/etc/kubernetes/manifests/kube-controller-manager.yaml
- 二进制部署配置文件所在位置:/opt/kubernetes/cfg/kube-controller-manager.conf
参考配置参数:
--allocate-node-cidrs=true
--cluster-cidr=10.244.0.0/162、Backend:指定工作模式
Flannel网络模式
Flannel 主要提供的是集群内的 Overlay 网络,支持三种后端实现,分别是:UDP 模式、VXLAN 模式、host-gw 模式。
udp模式:使用设备flannel.0进行封包解包,不是内核原生支持,上下文切换较大,性能非常差;
vxlan模式:使用flannel.1进行封包解包,内核原生支持,性能较强;
host-gw模式:无需flannel.1这样的中间设备,直接宿主机当作子网的下一跳地址,性能最强,host-gw的性能损失大约在10%左右,而其他所有基于VXLAN“隧道”机制的网络方案,性能损失在20%~30%左右
Directrouting:同时支持VXLAN和Host-GW工作模式
公有云VPC:ALIYUN,AWS
UDP模式
UDP 模式,是 Flannel 项目最早支持的一种方式,却也是性能最差的一种方式。这种模式提供的是一个三层的 Overlay 网络,即:它首先对发出端的 IP 包进行 UDP 封装,然后在接收端进行解封装拿到原始的 IP 包,进而把这个 IP 包转发给目标容器。工作原理如下图所示。
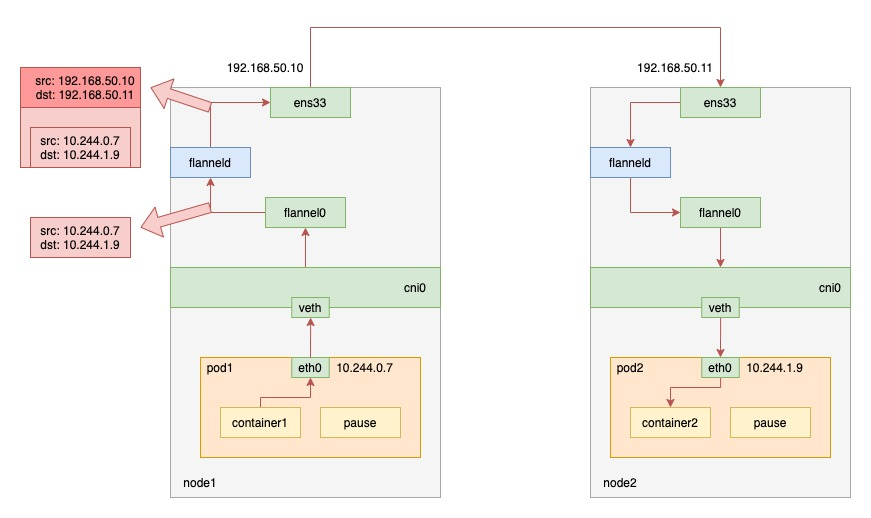

node1 上的 pod1 请求 node2 上的 pod2 时,流量的走向如下:
- pod1 里的进程发起请求,发出 IP 包
- IP 包根据 pod1 里的 veth 设备对,进入到 cni0 网桥
- 由于 IP 包的目的 ip 不在 node1 上,根据 flannel 在节点上创建出来的路由规则,进入到 flannel0 中
- Flannel 在每台主机上运行一个名为 flanneld 的二进制 Agent,此时 flanneld 进程会收到这个包,flanneld 判断该包应该在哪台 node 上,然后将其封装在一个 UDP 包中
- 最后通过 node1 上的网关,发送给 node2
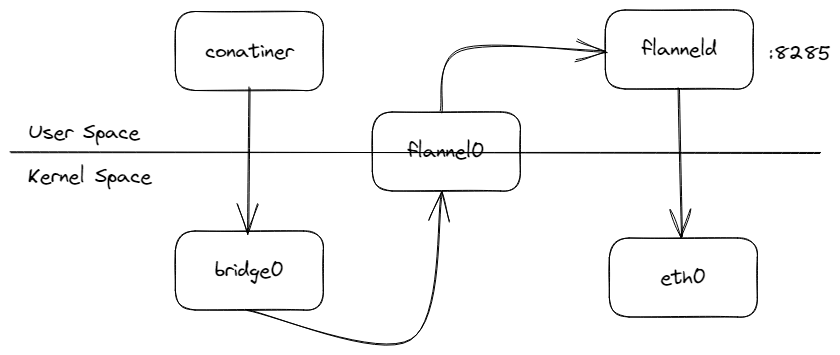
flannel0 是一个 TUN 设备(Tunnel 设备)。在 Linux 中,TUN 设备是一种工作在三层(Network Layer)的虚拟网络设备。TUN 设备的功能:在操作系统内核和用户应用程序之间传递 IP 包。
可以看到,这种模式性能差的原因在于,整个包的 UDP 封装过程是 flanneld 程序做的,也就是用户态,而这就带来了一次内核态向用户态的转换,以及一次用户态向内核态的转换。在上下文切换和用户态操作的代价其实是比较高的,而 UDP 模式因为封包拆包带来了额外的性能消耗。
VXLAN 模式(这个比较常用,重点讲一下)
VXLAN介绍
VXLAN,即Virtual Extensible LAN(虚拟可扩展局域网),是Linux 内核本身就支持的一种网络虚似化技术。VXLAN 可以完全在内核态实现上述封装和解封装的工作,从而通过与前面相似的“隧道”机制,构建出覆盖网络(Overlay Network)。
VXLAN的覆盖网络设计思想:在现有的三层网络之上,覆盖一层二层网络,使得连接在这个VXLAN二层网络上的主机之间,可以像在同一局域网里通信。
为了能够在二层网络上打通“隧道”,VXLAN 会在宿主机上设置一个特殊的网络设备作为“隧道”的两端。这个设备就叫作VTEP,即:VXLAN Tunnel End Point(虚拟隧道端点)。
通讯原理:
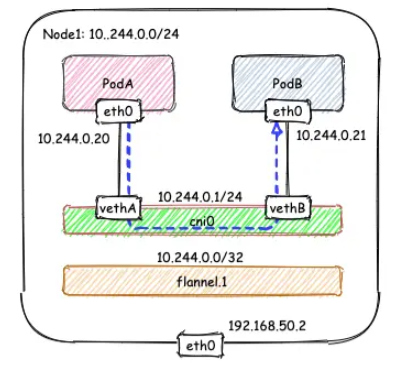
节点内通信:
查看路由规则:
[root@Node1 ~]# ip r
...
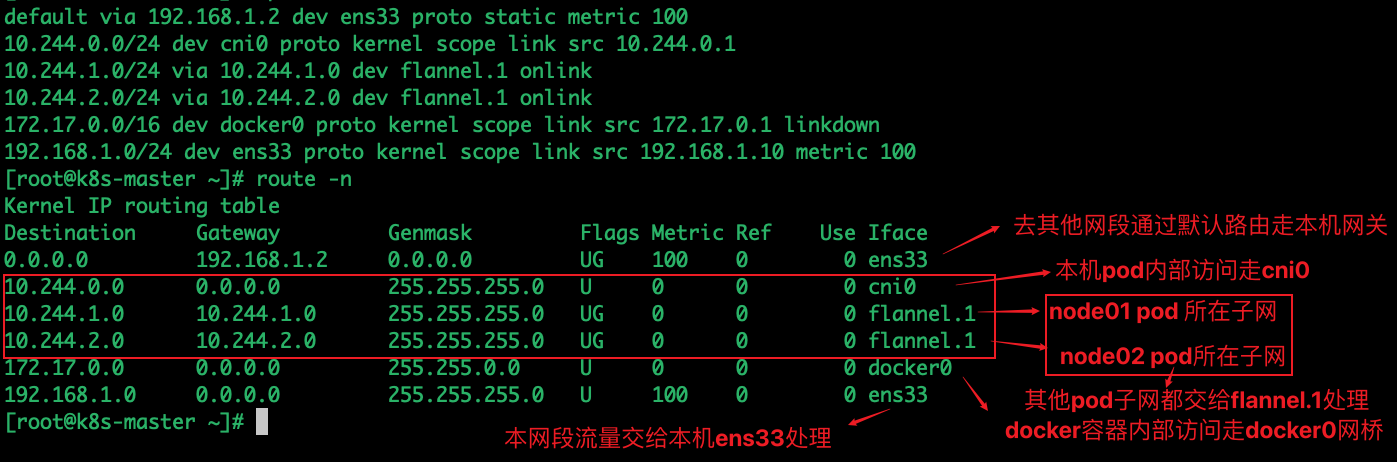
10.244.0.0/24 dev cni0 proto kernel scope link src 10.244.0.1 # Node1子网为10.224.0.0/24, 本机PodIP都交由cni0处理
10.244.1.0/24 via 10.244.1.0 dev flannel.1 onlink # Node2子网为10.224.1.0/24,Node2的PodID都交由flannel.1处理
...显然,节点内的容器间通信通过 cni0 网桥就能完成,不涉及任何VXLAN报文的封包解包。例如在下面的图例中,Node1的子网为10.244.0.1/24, PodA 10.244.0.20 和 PodB 10.224.0.21通过 cni0 网桥实现互通。整个过程类似于docker网络的网桥模式,这里只不过是docker0由cni0取代
跨节点通信:
VXLAN,即 Virtual Extensible LAN(虚拟可扩展局域网),是 Linux 内核本身就支持的一种网络虚似化技术。通过利用 Linux 内核的这种特性,也可以实现在内核态的封装和解封装的能力,从而构建出覆盖网络。其工作原理如下图所示:
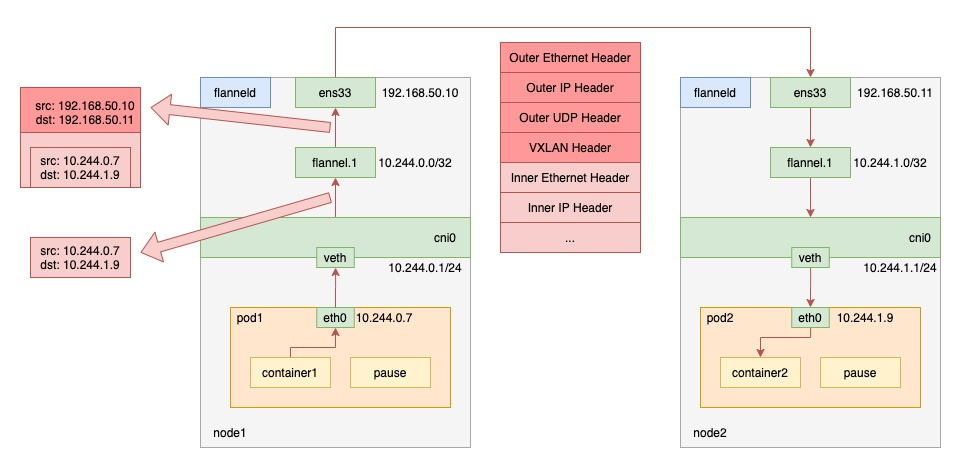
VXLAN 模式的 flannel 会在节点上创建一个叫 flannel.1 的 VTEP (VXLAN Tunnel End Point,虚拟隧道端点) 设备,跟 UDP 模式一样,该设备将二层数据帧封装在 UDP 包里,再转发出去,而与 UDP 模式不一样的是,整个封装的过程是在内核态完成的。
- pod1 里的进程发起请求,发出 IP 包
- IP 包根据 pod1 里的 veth 设备对,进入到 cni0 网桥
- 由于 IP 包的目的 ip 不在 node1 上,根据 flannel 在节点上创建出来的路由规则,进入到 flannel.1 中
- flannel.1 将原始 IP 包加上一个目的 MAC 地址,封装成一个二层数据帧;然后内核将数据帧封装进一个 UDP 包里
- 最后通过 node1 上的网关,发送给 node2
vxlan模式涉及的表
路由表
任何网络设备都需要路由表,路由表用来决定,当收到数据包时,该向哪里进行转发。路由表项通常会包含以下几个字段:
- Destination:目的地
- Gateway:网关
- Mask:掩码
- Interface:网络接口
- NextHop:下一跳
当设备收到网络数据时,从中解析出目的IP地址(假设为DEST_IP),然后遍历Destination不是0.0.0.0的条目,并执行:DEST_IP&Mask == Destination,如果为真说明找到一个转发条目。于是,可以从转发条目中获取到对应的网络接口,就会将数据包从该网络接口转发出去。如果没有找到对应的转发条目,就会转发到默认网关,也就是Destination为0.0.0.0的条目。
因此,路由表是从三层的层面解决包的转发问题,Linux中通过ip route或者route -n可以查看路由表。
arp表
当网络数据包转发时,底层还是要通过一个或者多个二层网络,在二层网络中就需要知道对方的MAC地址。于是,当内核的链路层收到包要进行转发时,就会去arp表查询接收方/网关的MAC地址。
arp表维护的就是ip->mac的对应关系,Linux中通过arp -a可以查看arp表。
fdb表
前面的路由表是三层的转发信息,当需要跨网络转发时就需要查找路由表,然后将包转发给下一跳。如果在当前网络进行转发时就需要查找fdb表,fdb表主要包含的字段有:
MAC地址:用目的MAC地址在该字段查找
老化时间:表项在一定时间如果没有被刷新则会被删除
类型:permanent(永久)、temporary(临时)
使用bridge fdb show dev flannel.1可以查看flannel.1虚拟网络设备的fdb转发表。
flannel.1 的封包过程
VXLAN的封包是将二层以太网帧封装到四层UDP报文中的过程。
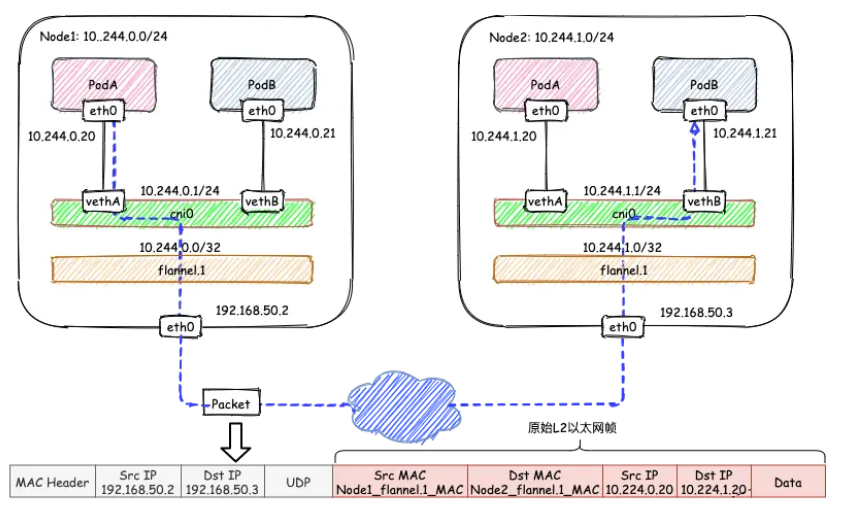
1、原始L2帧封装过程
要生成原始的L2帧, flannel.1 需要得知:
- 内层源/目的 IP地址
- 内层源/目的 MAC地址
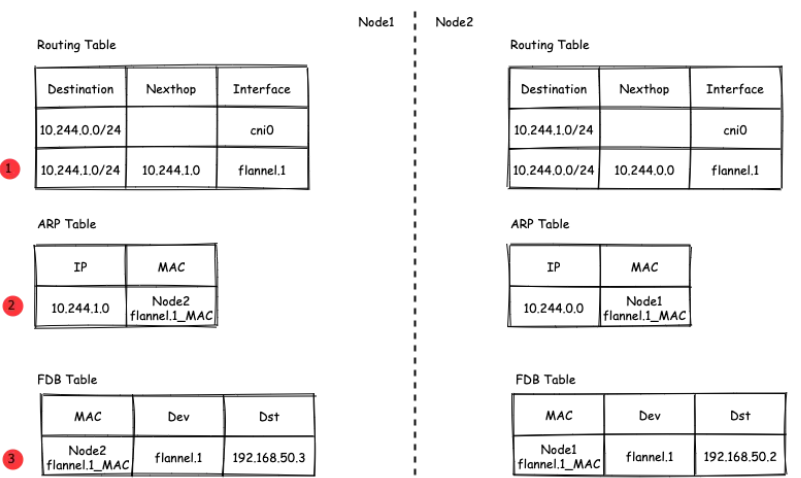
内层的源/目的IP地址是已知的,即为PodA/PodB的PodIP,在图例中,分别为10.224.0.20和10.224.1.20。 内层源/目的MAC地址要结合路由表和ARP表来获取。根据路由表①得知:
- 下一跳地址是10.224.1.0,关联ARP表②,得到下一跳的MAC地址,也就是目的MAC地址:
Node2_flannel.1_MAC; - 报文要从
flannel.1虚拟网卡发出,因此源MAC地址为flannel.1的MAC地址。
要注意的是,这里ARP表的表项②并不是通过ARP学习得到的,而是 flanneld 预先为每个节点设置好的,由 flanneld负责维护,没有过期时间。
# 查看ARP表,确定目标MAC地址
[root@Node1 ~]# ip neigh show dev flannel.1
10.244.1.0 lladdr ae:8f:fa:0b:3d:46 PERMANENT # PERMANENT 表示永不过期有了上面的信息, flannel.1 就可以构造出内层的2层以太网帧:

2、外层VXLAN UDP报文封装过程
要将原始L2帧封装成VXLAN UDP报文, flannel.1 还需要填充源/目的IP地址。前面提到,VTEP是VXLAN隧道的起点或终点。因此,目的IP地址即为对端VTEP的IP地址,通过FDB表获取。在FDB表③中,dst字段表示的即为VXLAN隧道目的端点(对端VTEP)的IP地址,也就是VXLAN UDP报文的目的IP地址。FDB表也是由 flanneld 在每个节点上预设并负责维护的。
FDB表(Forwarding database)用于保存二层设备中MAC地址和端口的关联关系,就像交换机中的MAC地址表一样。在二层设备转发二层以太网帧时,根据FDB表项来找到对应的端口。例如cni0网桥上连接了很多veth pair网卡,当网桥要将以太网帧转发给Pod时,FDB表根据Pod网卡的MAC地址查询FDB表,就能找到其对应的veth网卡,从而实现联通。可以使用 bridge fdb show 查看FDB表:
[root@Node1 ~]# bridge fdb show | grep flannel.1
ba:74:f9:db:69:c1 dev flannel.1 dst 192.168.50.3 self permanent源IP地址信息来自于 flannel.1 网卡设置本身,根据 local 192.168.50.2 可以得知源IP地址为192.168.50.2。
[root@Node1 ~]# ip -d a show flannel.1
6: flannel.1: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1450 qdisc noqueue state UNKNOWN group default
link/ether 32:02:78:2f:02:cb brd ff:ff:ff:ff:ff:ff promiscuity 0
vxlan id 1 local 192.168.50.2 dev eth0 srcport 0 0 dstport 8472 nolearning ageing 300 noudpcsum noudp6zerocsumtx noudp6zerocsumrx numtxqueues 1 numrxqueues 1 gso_max_size 65536 gso_max_segs 65535
inet 10.244.0.0/32 brd 10.244.0.0 scope global flannel.1
valid_lft forever preferred_lft forever
inet6 fe80::3002:78ff:fe2f:2cb/64 scope link
valid_lft forever preferred_lft forever涉及参数:
-d: 选项用于启用调试模式,显示更详细的信息,如果不添加这个参数是无法看出vxlan local地址的a: 是address的缩写,表示显示网络接口的地址信息。show: 用于显示信息。
至此, flannel.1 已经得到了所有完成VXLAN封包所需的信息,最终通过 eth0 发送一个VXLAN UDP报文:
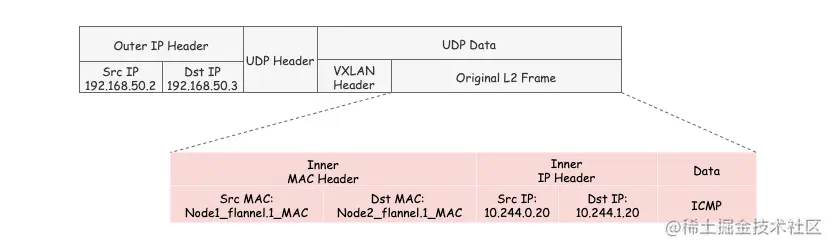
Flannel的VXLAN模式通过静态路由表(flanneld维护的路由表规则),ARP表(获取目的mac)和FDB表(获取目的IP)的信息,结合VXLAN虚拟网卡 flannel.1 ,实现了一个所有Pod同属一个大二层网络的VXLAN网络模型。
实验+抓包验证:
集群网络环境如下:
在 node1 上部署一个 nginx pod1,node2 上部署一个 nginx pod2。然后在 pod1 的容器中 curl pod2 容器的 80 端口。可以使用deployment创建,但是确保部署在跨节点的两台node上
kubectl create deployment nginx-web-1 --image=nginx --replicas=2
master 网卡 ens33:192.168.1.10
master cni0:10.244.0.1
master flannel.1:10.244.0.0
node1 网卡 ens33:192.168.1.11
pod1 eth0:10.244.1.14
node1 cni0:10.244.1.1
node1 flannel.1:10.244.1.0
node2 网卡 ens33:192.168.1.12
pod2 eth0:10.244.2.15
node2 cni0:10.244.2.1
node2 flannel.1:10.244.2.0路由查看:
这里就在master上查看了。node01和node02概念相同,如果集群一共有三台node,那么网络规则大致为下面这么六条

追踪数据包封包过程:
我们假想pod1要和pod2进行网络互通:
内层源IP地址为10.244.1.14,目标源地址为10.244.2.15
这里我们记录下:
| Src IP | Dst IP |
| 10.244.1.14 | 10.244.2.15 |
1.容器路由:容器根据路由表,将数据包发送下一跳10.244.1.1,从eth0网卡出。可以使用ip route命令查看路由表
进入容器内部,查看容器内部网卡和路由:
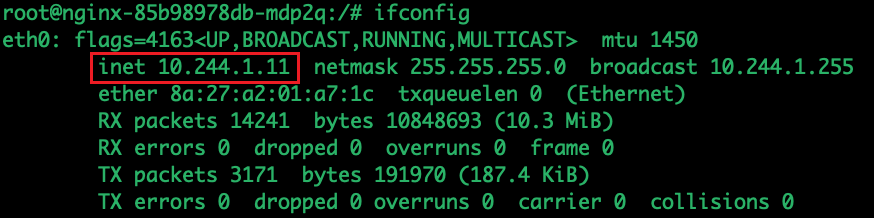


容器通过默认路由从10.244.1.1,从eth0网卡出
可以通过pod内部的/sys/class/net/eth0/iflink,查找容器中的网卡与宿主机的 veth 网卡之间的对应关系,在宿主机上做 ip link | grep "刚才获取的数字:" 操作即可定位vethxxx
根据容器内部的默认路由可以确定出流量网关最终到达宿主机虚拟网卡cni0
2.主机路由:数据包进入到宿主机虚拟网卡cni0,根据node1预设好的路由规则,下一跳地址必定会走10.244.2.0/24,,可以看到会走设备flannel.1转发到flannel.1虚拟网卡,也就是来到了隧道的入口。
10.244.2.0/24 via 10.244.2.0 dev flannel.1 onlink # 凡是发往10.244.2.0/24网段的数据包,都需要经过flannel.1设备发出,并且下一跳是10.244.2.0,即Node2 VTEP设备flannel.1。

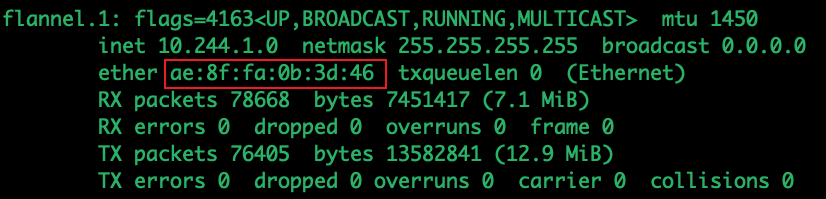
查看flannel.1的网卡设备Mac地址是 ae:8f:fa:0b:3d:46,即Src MAC为 ae:8f:fa:0b:3d:46
接下来是VXLAN封包过程:目前Vxlan采用的如下图的MAC in UDP的封装格式:其封装思维是将原始数据报文当做用户数据包,VTEP当做大二层接入,那么VTEP会依次进行传输层封装,网络层封装,以太网头部封装
3.VXLAN 二层封包:而这些VTEP设备之间组成一个二层网络,但是二层网络必须要知道目的MAC地址,那这个MAC地址从哪获取到呢?其实在flanneld进程启动后,就会自动添加其他节点ARP记录,可以通过ip neigh show dev flannel.1命令查看
查看flanneld 预先为每个节点设置好的ARP表表,确定目标MAC地址,没有过期时间。

因为,下一跳地址为10.244.2.0/24,目标地址锁定成为 72:83:00:93:3c:69
这里我们记录下:
| Src MAC | Dst MAC | Src IP | Dst IP |
| ae:8f:fa:0b:3d:46 | 72:83:00:93:3c:69 | 10.244.1.14 | 10.244.2.15 |
内层的2层以太网帧就构造好了,将网帧打上VXLAN Header
4.UDP二次封包:对于宿主机网络来说这个二层帧并不能在宿主机之间二层网络传输(本身二层数据是内层容器内部的数据,宿主机不认识,为什么不用IP层封包:使用IP网络层的封装不涉及端口号以及NAT穿透等问题)。所以接下来,Linux内核还要把这个数据帧进一步封装成为宿主机网络的一个普通数据帧,好让它载着内部数据帧,通过宿主机的eth0网卡进行传输。
5.封装的UDP包发送:封装成VXLAN UDP报文,成为宿主机网络可传输的数据帧后,还需要添外层原始IP和目标IP,VTEP是VXLAN隧道的起点或终点,终点需要在flanneld为每个节点上预设并维护的FDB表中获取。根据Pod网卡的MAC地址查询FDB表
源IP地址信息来自于 flannel.1 网卡设置本身,显示出详细信息
ip -d a show flannel.1
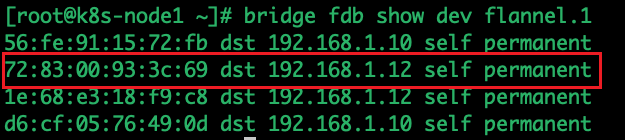
使用 bridge fdb show dev flannel.1 查看FDB表获取终点IP,通过目标MAC地址(实质为目标node的flannel.1设备MAC)为72:83:00:93:3c:69即可定位目标IP:
最后总结一下:
| Outer Src IP | Outer Dst IP | Outer UDP Header | VXLAN Header | Src MAC | Dst MAC | Src IP | Dst IP |
| 192.168.1.11 | 192.168.1.12 | UDP data | ae:8f:fa:0b:3d:46 | 72:83:00:93:3c:69 | 10.244.1.14 | 10.244.2.15 |
包数据来源总结:
内层Src IP、Dst IP:已知
内层Src MAC:pod内部eth0连接外部vethxxx->通过路由表查到数据交给flannel.1
内层Dst MAC:flanneld维护的arp表查询:ip neigh show dev flannel.1
外层Outer Src IP:ip -d a show flannel.1
外层Outer Dst IP:通过flanneld维护的FDB表获取终点IP:bridge fdb show dev flannel.1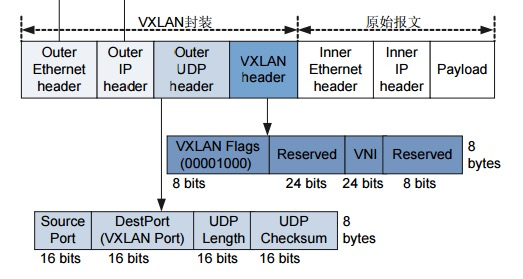
6.数据包到达目的宿主机:接下来,就是宿主机与宿主机之间通信了,数据包从Node1的eth0网卡发出去,Node2接收到数据包,解封装发现是VXLAN数据包,把它交给flannel.1设备。flannel.1设备则会进一步拆包,取出原始IP包(源容器IP和目标容器IP),通过cni0网桥二层转发给容器。
抓包验证
node1 的网卡 ens33 的抓包情况:
tcpdump -i ens33 -w /tmp/tcpdump.pcap过滤选择:udp && ip.src==192.168.1.11 && ip.dst==192.168.1.12
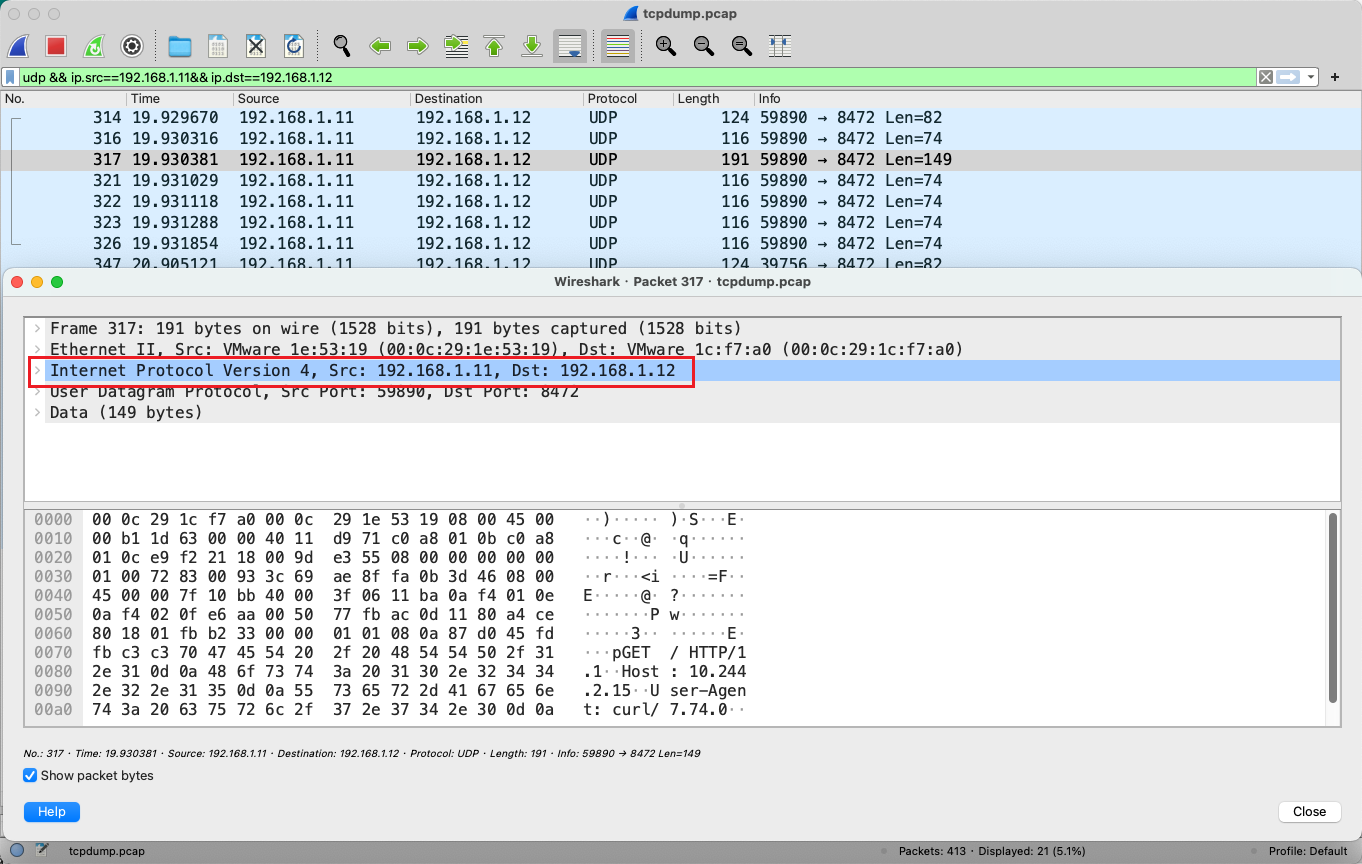
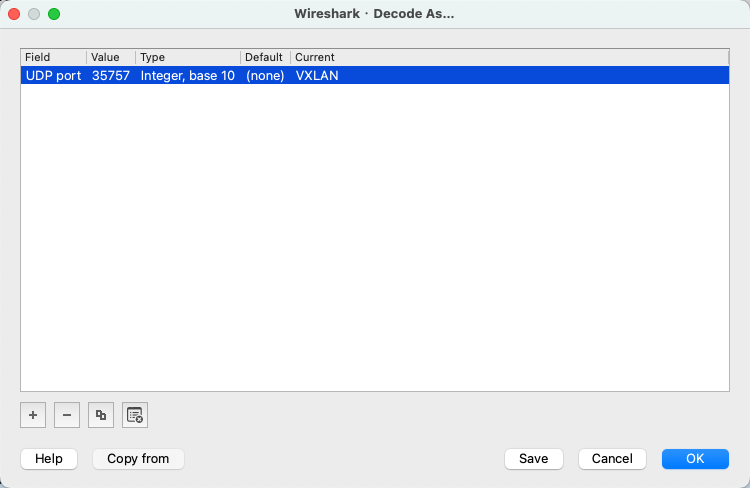
只能看到源 ip 为 node1 ip、目的 ip 为 node2 ip 的 UDP 包。由于 flannel.1 进行了一层 UDP 封包,这里我们在 Wireshark 中设置一下将 UDP 包解析为 VxLAN 格式(端口为 8472),设置过程为 Analyze->Decode As:
然后再来看一下 node1 网卡上收到的包:
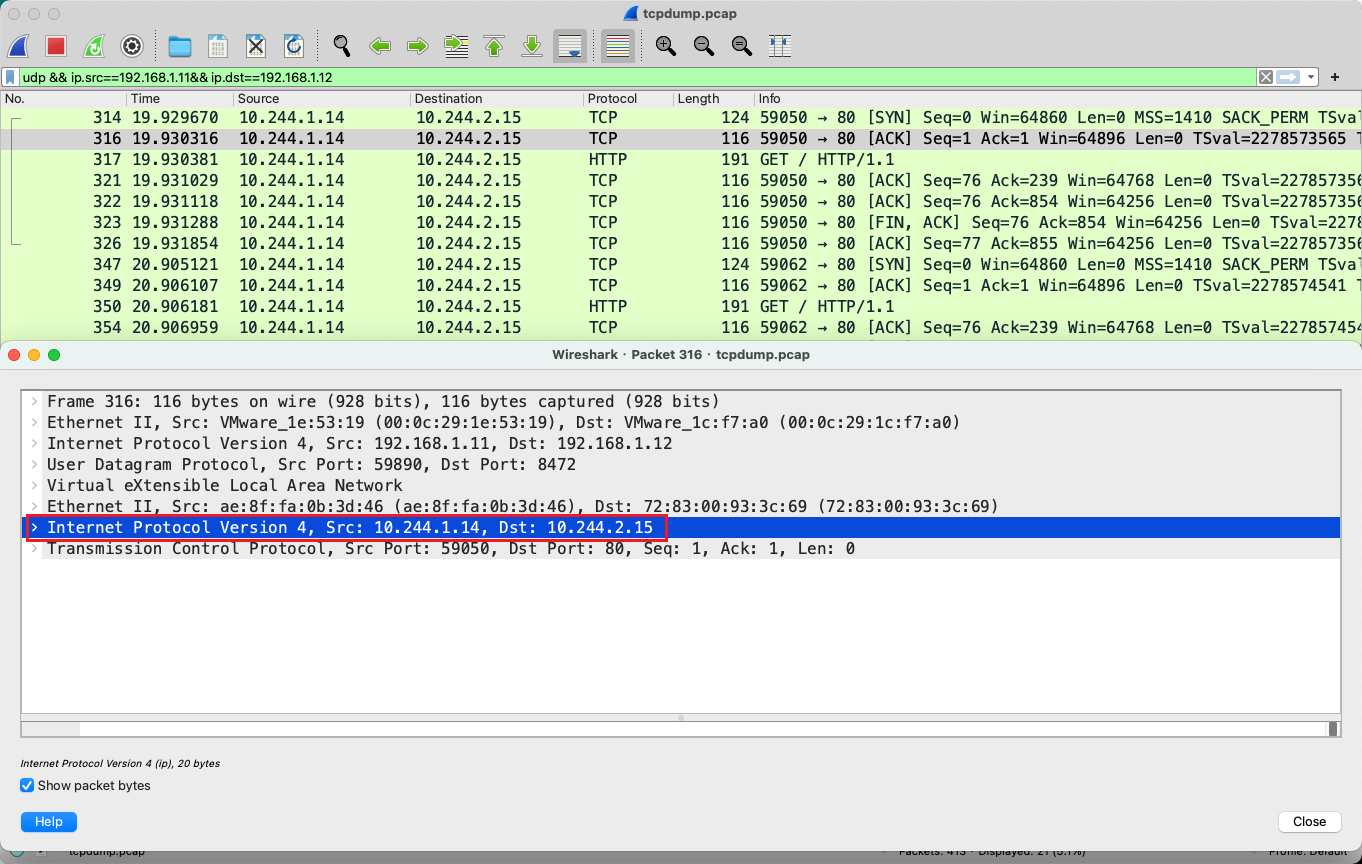
可以看到源 ip 为 pod1 ip、目的 ip 为 pod2 ip,并且该 IP 包被封装在 UDP 包中。
数据格式如下图:

5.封装到UDP包发出去:在封装成宿主机网络可传输的数据帧时,还缺少目标宿主机MAC地址,也就是说这个UDP包该发给哪台宿主机呢?
flanneld进程也维护着一个叫做FDB的转发数据库,可以通过bridge fdb show dev flannel.1命令查看。可以看到,上面用的对方flannel.1的MAC地址对应宿主机IP,也就是UDP要发往的目的地。所以使用这个目的IP与MAC地址进行封装。
6.数据包到达目的宿主机:接下来,就是宿主机与宿主机之间通信了,数据包从Node1的eth0网卡发出去,Node2接收到数据包,解封装发现是VXLAN数据包,把它交给flannel.1设备。flannel.1设备则会进一步拆包,取出原始IP包(源容器IP和目标容器IP),通过cni0网桥二层转发给容器。
host-gw 模式
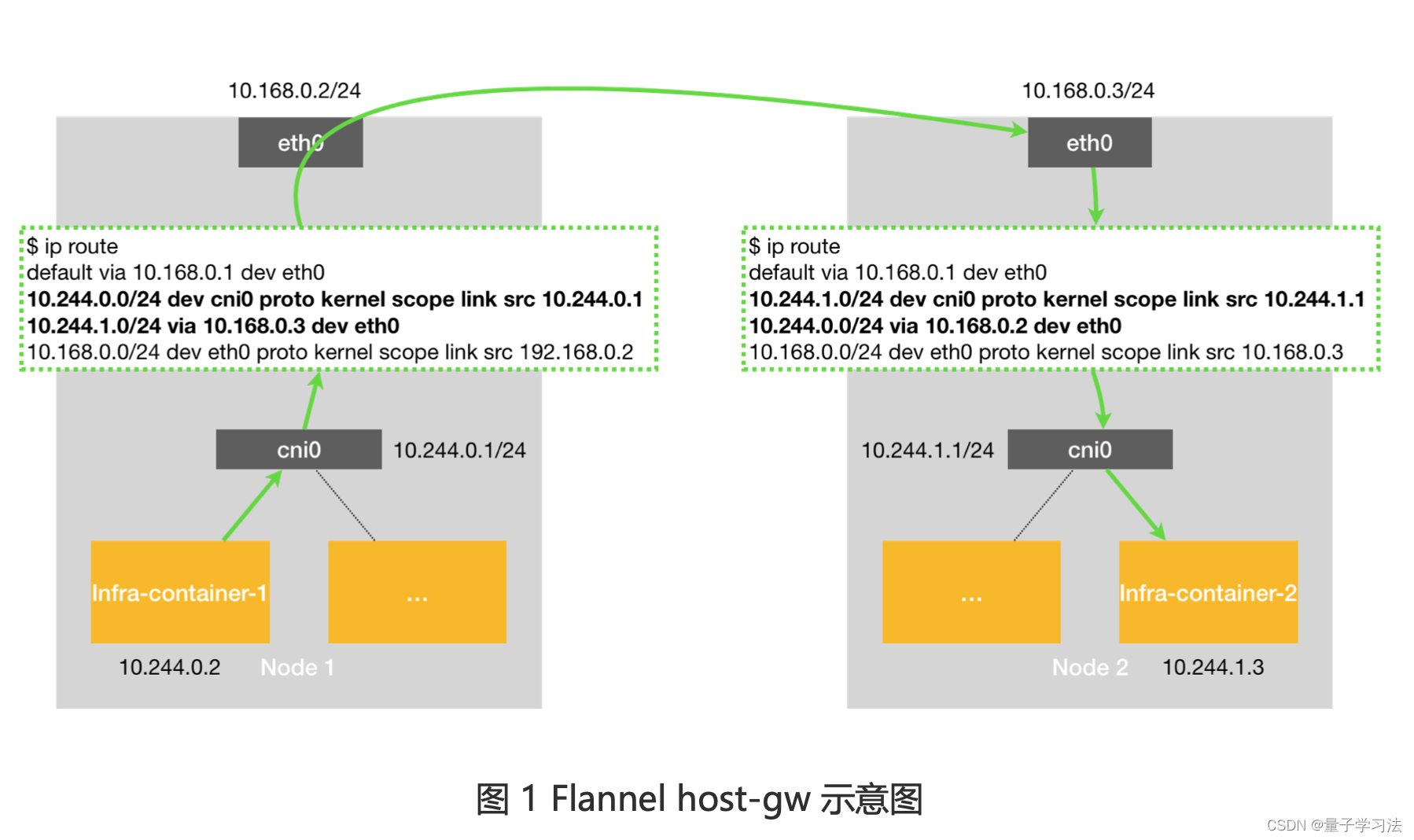
最后一种 host-gw 模式是一种纯三层网络方案。在上述的VXLAN的示例中,Node1和Node2其实是同一宿主机中的两台使用桥接模式的虚机,也就是说它们在一个二层网络中。在二层网络互通的情况下,直接配置节点的三层路由即可互通,不需要使用VXLAN隧道。其工作原理为将每个 Flannel 子网的“下一跳”设置成了该子网对应的宿主机的 IP 地址,这台主机会充当这条容器通信路径里的“网关”。这样 IP 包就能通过二层网络达到目的主机,而正是因为这一点,host-gw 模式要求集群宿主机之间的网络是二层连通的,因为跨节点通信就意味着将数据包发送给上层的路由器,要看数据包的源ip和目标ip进行转发,源ip和目标ip为pod容器的ip,上面的路由器肯定是不认识的,如下图所示。
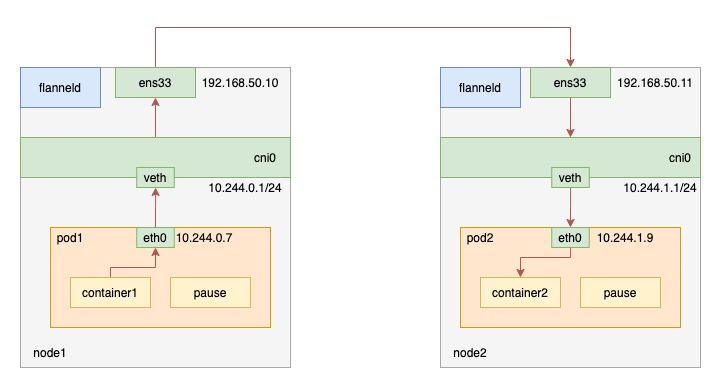
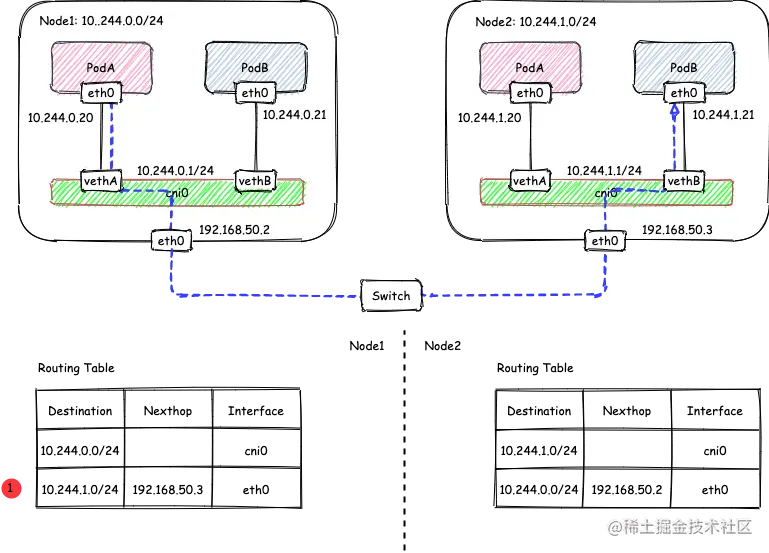
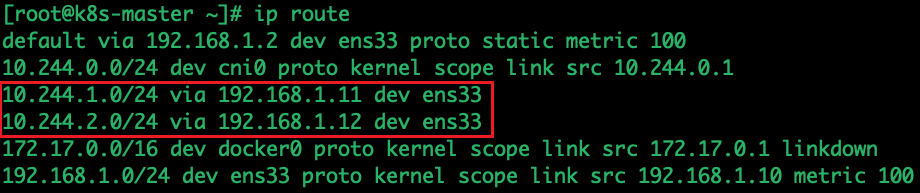
宿主机上的路由信息是 flanneld 设置的,因为 flannel 子网和主机的信息保存在 etcd 中,所以 flanneld 只需要 watch 这些数据的变化,实时更新路由表即可。在这种模式下,容器通信的过程就免除了额外的封包和解包带来的性能损耗。当你设置flannel使用host-gw模式,flanneld会在Node1添加如下规则:
node1 上的 pod1 请求 node2 上的 pod2 时,流量的走向如下:
- 发往10.244.2.0/24 子网下的包,下一跳地址为 192.168.1.11,需要从本机 ens33 网卡发出,即将Node2作为网关
- 当 IP 包从网络层进入链路层封装成帧的时候,node1 的ens33设备就会使用下一跳地址对应的 MAC 地址,作为该数据帧的目的 MAC 地址。显然,这个MAC 地址,正是 Node2 的 MAC 地址。
- 这样数据包就被发送到了Node2 的ens33上,Node2 的ens33收到数据包后,其内核网络栈从二层数据帧里拿到 IP 包后,会“看到”这个 IP 包的目的 IP 地址是10.244.1.15,即 container2的 IP 地址。根据Node2上的路由表(10.244.2.0/24 dev cni0 proto kernel scope link src 10.244.2.1 ),该数据包进入cni0 网桥,最后进入到 container2当中。
图解host-gw模式下包流转
要使用host-gw模式,需要修改 ConfigMap kube-flannel-cfg ,将 Backend.Type 从vxlan改为host-gw,然后重启所有kube-flannel Pod即可:
...
net-conf.json: |
{
"Network": "10.244.0.0/16",
"Backend": {
"Type": "host-gw" // <- 改成host-gw
}
}
...总结:
Flannel 主要提供了 Overlay 的网络方案,UDP 模式由于其封包拆包的过程涉及了多次上下文的切换,导致性能很差,逐渐被社区抛弃;VXLAN 模式的封包拆包过程均在内核态,性能要比 UDP 好很多,也是最经常使用的模式;host-gw 模式不涉及封包拆包,所以性能相对较高,但要求节点间二层互通。
Calico
Calico是一个用于容器、虚拟机和基于本机主机的工作负载的开源网络和网络安全解决方案。Calico是一个纯三层的数据中心网络方案。Calico支持广泛的平台,包括Kubernetes, OpenShift, Docker EE, OpenStack和裸机服务。
Calico 在每一个计算节点利用Linux Kernel 实现了一个高效的虚拟路由器(vRouter)来负责数据转发,而每个vRouter 通过BGP 协议负责把自己上运行的workload 的路由信息向整个Calico 网络内传播。
此外,Calico 项目还实现了Kubernetes 网络策略,提供ACL功能。
实际上,Calico项目提供的网络解决方案,与Flannel的host-gw模式几乎一样。也就是说,Calico也是基于路由表实现容器数据包转发,但不同于Flannel使用flanneld进程来维护路由信息的做法,而Calico项目使用BGP协议来自动维护整个集群的路由信息。
BGP英文全称是Border Gateway Protocol,即边界网关协议,它是一种自治系统间的动态路由发现协议,与其他BGP 系统交换网络可达信息。
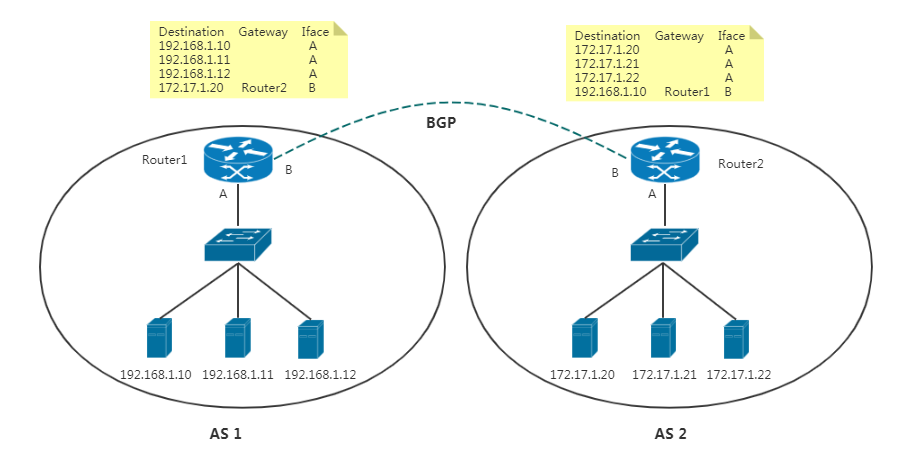
在这个图中,有两个自治系统(autonomous system,简称为AS):AS 1 和AS 2。
在互联网中,一个自治系统(AS)是一个有权自主地决定在本系统中应采用何种路由协议的小型单位。这个网络单位可以是一个简单的网络也可以是一个由一个或多个普通的网络管理员来控制的网络群体,它是一个单独的可管理的网络单元(例如一所大学,一个企业或者一个公司个体)。一个自治系统有时也被称为是一个路由选择域(routing domain)。一个自治系统将会分配一个全局的唯一的16位号码,有时我们把这个号码叫做自治系统号(ASN)。
在正常情况下,自治系统之间不会有任何来往。如果两个自治系统里的主机,要通过IP 地址直接进行通信,我们就必须使用路由器把这两个自治系统连接起来。BGP协议就是让他们互联的一种方式。
Calico的网络架构
Calico支持多种网络架构,其中IPIP和BGP两种网络架构较为常用。这里简单说明一下这两种模式。
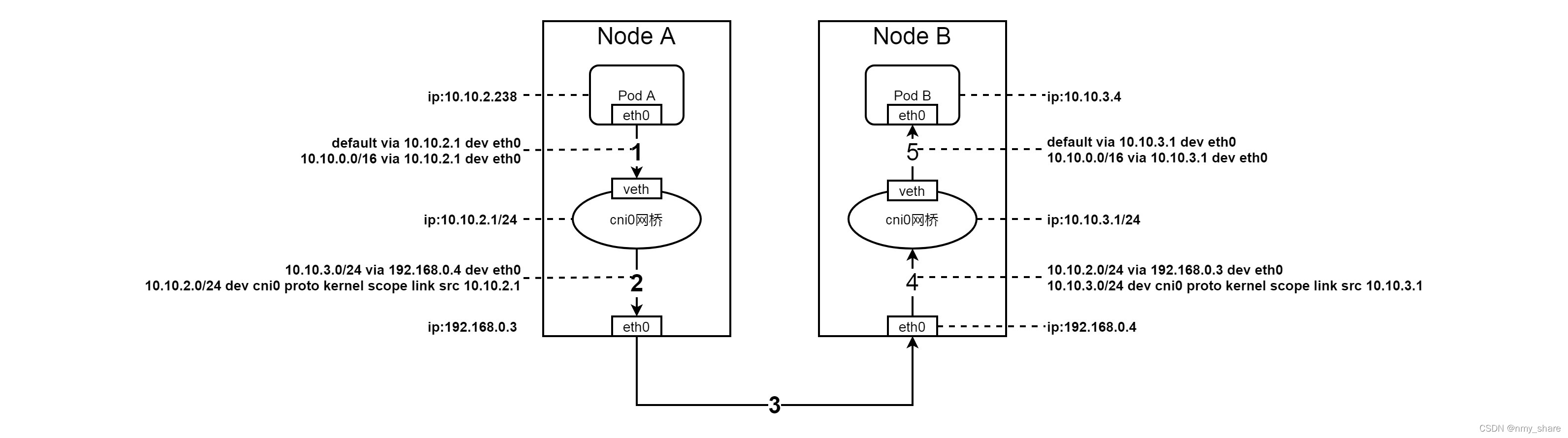
这两种模式下的calico所管理的容器内部联通主机外部网络的方法都是一样的,用linux支持的veth-pair,一端在容器内部一般名称是eth0@if66,这个66表示的是主机网络命名空间下的66号ip link.另一端是主机网络空间下的cali97e45806449,这个97e45806449是VethNameForWorkload函数利用容器属性计算的加密字符的前11个字符。每个Calico容器内部的路由如下所示:

再去看Calico所有的veth-pair在主机空间的calixxx的MAC地址,无一例外都是ee:ee:ee:ee:ee:ee, 这样的配置简化了操作,使得容器会把报文交给169.254.1.1来处理,但是这个地址是本地保留的地址也可以说是个无效地址,但是通过veth-pair会传递到对端calixxx上,注意,因为calixxx网卡开启了arpproxy,所以它会代答所有的ARP请求,让容器的报文都发到calixxx上,也就是发送到主机网络栈,再有主机网络栈的路由来送到下一站. 可以通过cat /proc/sys/net/ipv4/conf/calixxx/proxy_arp/来查看,输出都是1

这里注意,calico要响应arp请求还需要具备三个条件,否则容器内的ARP显示异常:
- 宿主机的arp代理得打开
- 宿主机需要有访问目的地址的明确路由,这里可理解为宿主机要有默认路由
- 发送arp request的接口与接收arp request的接口不能是相同,即容器中的默认网关不能是calico的虚拟网关
Calico 没有使用 CNI 的网桥模式,而是将节点当成边界路由器,组成了一个全连通的网络,通过 BGP 协议交换路由。所以,Calico 的 CNI 插件还需要在宿主机上为每个容器的 Veth Pair 设备配置一条路由规则,用于接收传入的 IP 包。

Calico 的组件:
Felix:calico的核心组件,以DaemonSet方式运行在每个节点上。主要负责维护宿主机上路由规则以及ACL规则。主要的功能有接口管理、路由规则、ACL规则和状态报告,Felix会监听ECTD中心的存储,从它获取事件,比如说用户在这台机器上加了一个IP,或者是创建了一个容器等。用户创建pod后,Felix负责将其网卡、IP、MAC都设置好,然后在内核的路由表里面写一条,注明这个IP应该到这张网卡。同样如果用户制定了隔离策略,Felix同样会将该策略创建到ACL中,以实现隔离。etcd:分布式键值存储,主要负责网络元数据一致性,确保Calico网络状态的准确性,可以与kubernetes共用;BGP Client(BIRD):Calico 为每一台 Host 部署一个 BGP Client,它的作用是将Felix的路由信息读入内核,并通过BGP协议在集群中分发。当Felix将路由插入到Linux内核FIB中时,BGP客户端将获取这些路由并将它们分发到部署中的其他节点。这可以确保在部署时有效地路由流量BGP Router Reflector:大型网络仅仅使用 BGP client 形成 mesh 全网互联的方案就会导致规模限制,所有节点需要 N^2 个连接,为了解决这个规模问题,可以采用 BGP 的 Router Reflector 的方法,使所有 BGP Client 仅与特定 RR 节点互联并做路由同步,从而大大减少连接数Calicoctl:calico 命令行管理工具
三个组件都是通过一个 DaemonSet 安装的。CNI 插件是通过 initContainer 安装的;而 Felix 和 BIRD 是同一个 pod 的两个 container。
架构特点
由于Calico是一种纯三层的实现,因此可以避免与二层方案相关的数据包封装的操作,中间没有任何的NAT,没有任何的overlay,所以它的转发效率可能是所有方案中最高的,因为它的包直接走原生TCP/IP的协议栈,它的隔离也因为这个栈而变得好做。因为TCP/IP的协议栈提供了一整套的防火墙的规则,所以它可以通过IPTABLES的规则达到比较复杂的隔离逻辑。
1、设计思路
Calico 是一种容器之间互通的网络方案。在虚拟化平台中,比如 OpenStack、Docker 等都需要实现 workloads 之间互连,但同时也需要对容器做隔离控制。而在多数的虚拟化平台实现中,通常都使用二层隔离技术来实现容器的网络,这些二层的技术有一些弊端,比如需要依赖 VLAN、bridge 和隧道等技术,其中 bridge 带来了复杂性,vlan 隔离和 tunnel 隧道则消耗更多的资源并对物理环境有要求,随着网络规模的增大,整体会变得越加复杂。我们尝试把 Host 当作 Internet 中的路由器,同样使用 BGP 同步路由,并使用 iptables 来做安全访问策略,最终设计出了 Calico 方案。Calico支持多种网络架构,其中IPIP和BGP两种网络架构较为常用。
2、优势
*优化资源利用:二层网络通讯需要依赖广播消息机制,广播消息的开销与 host 的数量呈指数级增长,Calico 使用的三层路由方法,则完全抑制了二层广播,减少了资源开销。
*可扩展性:Calico 使用与 Internet 类似的方案,Internet 的网络比任何数据中心都大,Calico 同样天然具有可扩展性。
*依赖少:Calico 仅依赖三层路由可达。
*可适配性:Calico 较少的依赖性使它能适配所有 VM、Container、白盒或者混合环境场景。Calico 工作原理
Calico把每个操作系统的协议栈认为是一个路由器,然后把所有的容器认为是连在这个路由器上的网络终端,在路由器之间跑标准的路由协议——BGP的协议,然后让它们自己去学习这个网络拓扑该如何转发。所以Calico方案其实是一个纯三层的方案,也就是说让每台机器的协议栈的三层去确保两个容器,跨主机容器之间的三层连通性。
对于控制平面,它每个节点上会运行两个主要的程序,一个是Felix,它会监听ECTD中心的存储,从它获取事件,比如说用户在这台机器上加了一个IP,或者是分配了一个容器等。接着会在这台机器上创建出一个容器,并将其网卡、IP、MAC都设置好,然后在内核的路由表里面写一条,注明这个IP应该到这张网卡。绿色部分是一个标准的路由程序,它会从内核里面获取哪一些IP的路由发生了变化,然后通过标准BGP的路由协议扩散到整个其他的宿主机上,让外界都知道这个IP在这里,你们路由的时候得到这里来。
由于Calico是一种纯三层的实现,因此可以避免与二层方案相关的数据包封装的操作,中间没有任何的NAT,没有任何的overlay,所以它的转发效率可能是所有方案中最高的,因为它的包直接走原生TCP/IP的协议栈,它的隔离也因为这个栈而变得好做。因为TCP/IP的协议栈提供了一整套的防火墙的规则,所以它可以通过IPTABLES的规则达到比较复杂的隔离逻辑。
Calico是纯三层的SDN 实现,它基于BPG 协议和Linux自身的路由转发机制,不依赖特殊硬件,容器通信也不依赖iptables NAT或Tunnel 等技术
Calico部署
Calico存储
Calico存储有两种方式:
- 数据存储在etcd:https://docs.projectcalico.org/v3.9/manifests/calico-etcd.yaml
- 数据存储在Kubernetes API Datastore服务中:https://docs.projectcalico.org/manifests/calico.yaml
数据存储在etcd中还需要修改yaml:
- 配置连接etcd地址,如果使用https,还需要配置证书。(ConfigMap和Secret位置)
- 根据实际网络规划修改Pod CIDR(CALICOIPV4POOLCIDR)
calicoctl
calicoctl工具用于管理calico,可通过命令行读取、创建、更新和删除Calico 的存储对象。
项目地址:https://github.com/projectcalico/calicoctl
calicoctl 在使用过程中,需要从配置文件中读取Calico 对象存储地址等信息。默认配置文件路径/etc/calico/calicoctl.cfg
Calico的两种网络模式
IPIP
从字面来理解,就是把一个IP数据包又套在一个IP包里,即把 IP 层封装到 IP 层的一个 tunnel。它的作用其实基本上就相当于一个基于IP层的网桥!一般来说,普通的网桥是基于mac层的,根本不需 IP,而这个 ipip 则是通过两端的路由做一个 tunnel,把两个本来不通的网络通过点对点连接起来。
BGP
边界网关协议(Border Gateway Protocol, BGP)是互联网上一个核心的去中心化自治路由协议。它通过维护IP路由表或‘前缀’表来实现自治系统(AS)之间的可达性,属于矢量路由协议。BGP不使用传统的内部网关协议(IGP)的指标,而使用基于路径、网络策略或规则集来决定路由。因此,它更适合被称为矢量性协议,而不是路由协议。BGP,通俗的讲就是讲接入到机房的多条线路(如电信、联通、移动等)融合为一体,实现多线单IP,BGP 机房的优点:服务器只需要设置一个IP地址,最佳访问路由是由网络上的骨干路由器根据路由跳数与其它技术指标来确定的,不会占用服务器的任何系统。
修改模式:
清理现有网络插件:
要将使用 kubeadm 部署的 Kubernetes 集群网络从 Flannel 更改为 Calico,可以按照以下步骤进行操作:
删除flannel:
# kubectl delete -f kube-flannel.yml
#删除node节点上残留网络
# 删除cni0
ifconfig cni0 down
ip link delete cni0
rm -rf /var/lib/cni/
# 删除flannel网络
ifconfig flannel.1 down
ip link delete flannel.1
rm -f /etc/cni/net.d/*
# 如果flannel路由存在,删掉其路由
ip route delete 10.244.1.0/24 via 192.168.1.11 dev ens33
ip route delete 10.244.2.0/24 via 192.168.1.12 dev ens33
ip route delete 172.17.0.0/16 dev docker0 proto kernel scope link src 172.17.0.1
# 重启kubelet
systemctl restart kubelet安装 Calico:
可以在 Calico GitHub 仓库中找到这些文件。以下是一个示例:
# kubectl apply -f https://docs.projectcalico.org/manifests/calico.yaml
wget https://docs.projectcalico.org/manifests/calico.yaml --no-check-certificate
vim calico.yaml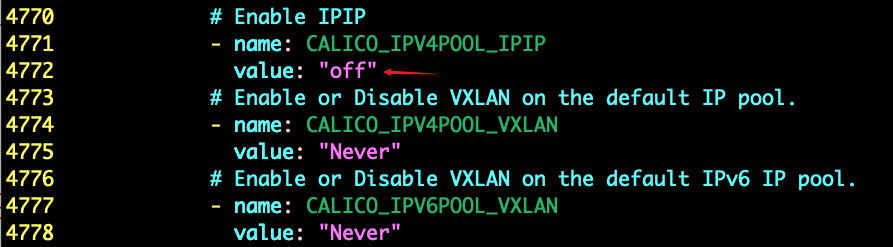

kubectl apply -f calico.yaml等待 Calico 部署完成
等待一段时间,直到 Calico 的相关 Pod 全部运行并处于正常状态。您可以使用以下命令来监视 Calico Pod 的状态:
kubectl get pods -n kube-system -l k8s-app=calico-node通过运行以下命令来验证 Calico 是否已成功替代 Flannel,并且集群网络正常运行:
kubectl get pods -n kube-system
# 如果安装了coredns和metrics-server,可能需要删除重建pod
kubectl -n kube-system delete pod coredns-xxxx
kubectl -n kube-system delete pod metrics-server-xxx
验证 Calico 是否生效
calico默认模式是IPIP模式,这里我们先不开此模式,看下网络的基本设置
安装calicoctl
下载 Calicoctl 二进制文件:
访问 Calico GitHub Release 页面,选择适用于您的操作系统的最新版本的 calicoctl 二进制文件。https://github.com/projectcalico/calico/releases
例如,在 Linux 系统上,您可以使用以下命令下载(calicoctl命令版本要与集群calico一致,可以在calico.yaml中查看):
curl -L https://github.com/projectcalico/calico/releases/download/v3.26.1/calicoctl-linux-amd64 -o kubectl-calico将 Calicoctl 移动到可执行路径:
下载完成后,将 calicoctl 移动到一个在您的 PATH 环境变量中的目录,以便能够全局执行它。例如,您可以将其移动到 /usr/local/bin/:
mv kubectl-calico calicoctl && sudo mv calicoctl /usr/local/bin/添加执行权限(如果需要):
确保 calicoctl 具有执行权限。如果没有,请添加执行权限:
chmod +x /usr/local/bin/calicoctl验证安装:
运行以下命令验证 calicoctl 是否成功安装:
calicoctl version
可以使用 calicoctl 查看 node1 的节点连接情况:
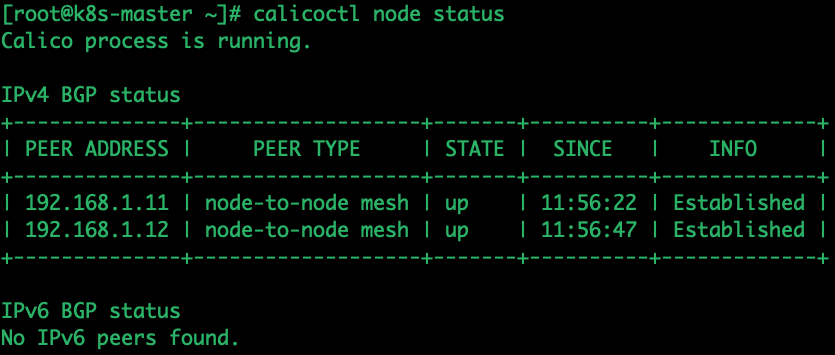
calicoctl get node && calicoctl node status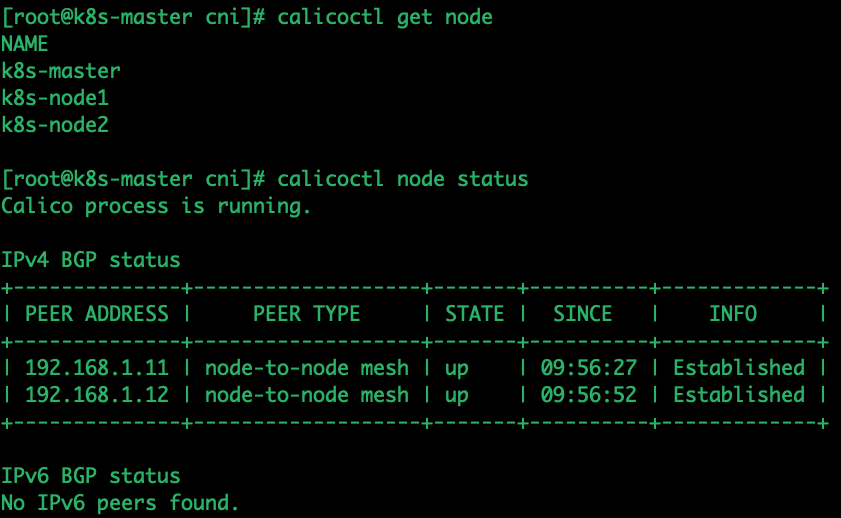
可以看到整个 calico 集群上有 3 个节点,node1 和另外两个节点处于连接状态,模式为 “Node-to-Node Mesh”。再看下 node1 上的路由信息如下:
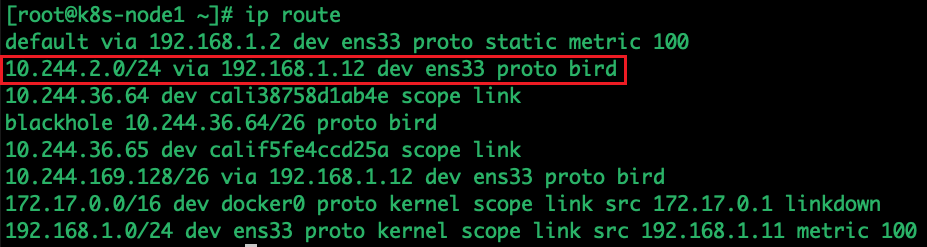
查看集群节点模式:
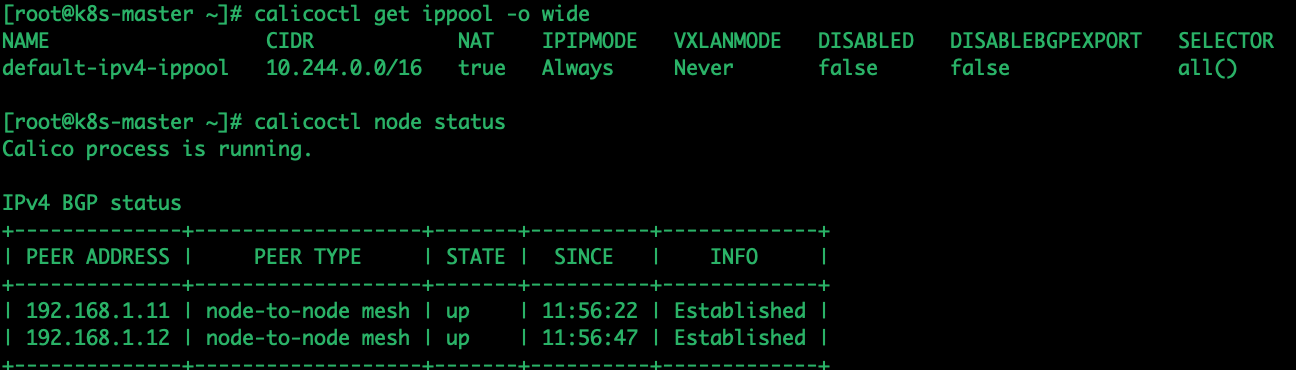
calicoctl get ippool -o wide
calicoctl get ippool -o yaml > ippool.yaml
vim ippool.yml
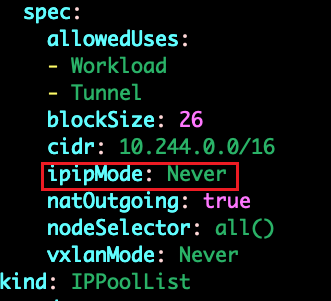
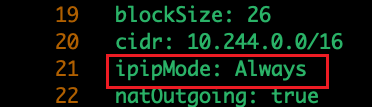
这里是启用了ipip模式,设置为Never就是关闭了ipip模式就会默认采用BGP模式,之后如果想要修改模式的话,直接修改这个配置文件参数(例如ipipMode: Always)或直接edit修改:kubectl edit ippool
BGP 工作原理
在安装calico网络时,默认安装是IPIP网络。calico.yaml文件中,将CALICO_IPV4POOL_IPIP的值修改成 "off",及刚才步骤,就能够替换成BGP网络。
Calico 采用的 BGP,就是在大规模网络中实现节点路由信息共享的一种协议。全称是 Border Gateway Protocol,即:边界网关协议。它是一个 Linux 内核原生就支持的、专门用在大规模数据中心里维护不同的 “自治系统” 之间路由信息的、无中心的路由协议。
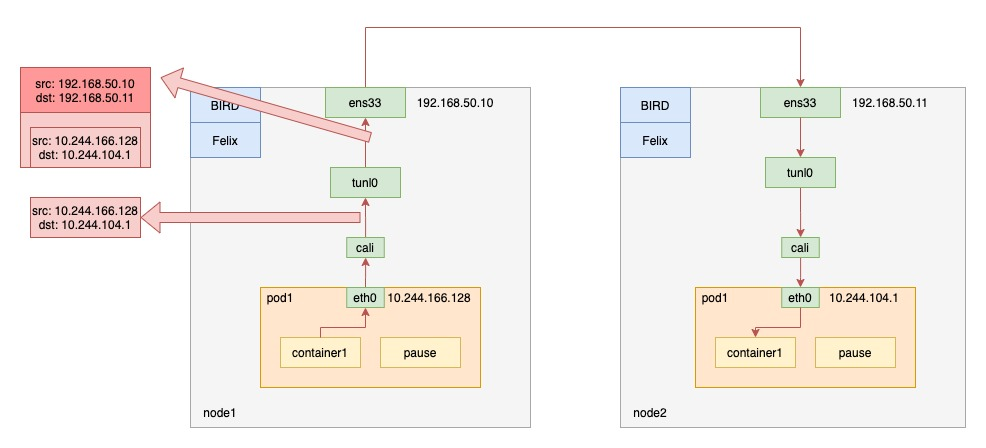
由于没有使用 CNI 的网桥,Calico 的 CNI 插件需要为每个容器设置一个 Veth Pair 设备,然后把其中的一端放置在宿主机上,还需要在宿主机上为每个容器的 Veth Pair 设备配置一条路由规则,用于接收传入的 IP 包。如下图所示:
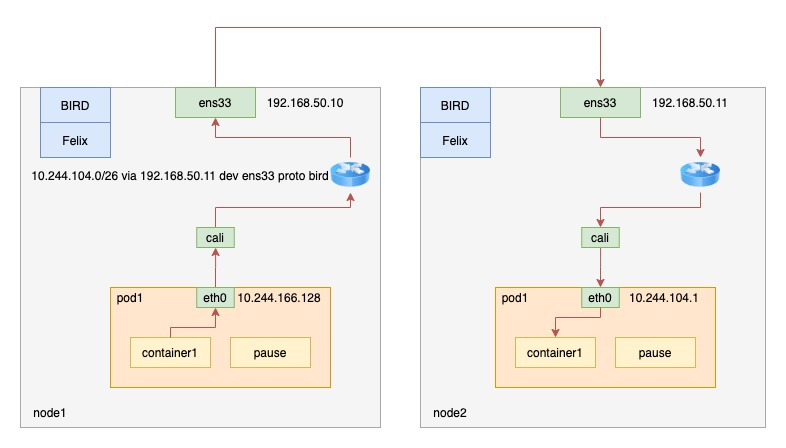
上述图解node1的路由规则:
~ ip route
default via 192.168.50.1 dev ens33 proto static metric 100
10.244.104.0/26 via 192.168.50.11 dev ens33 proto bird
10.244.135.0/26 via 192.168.50.12 dev ens33 proto bird
10.244.166.128 dev cali717821d73f3 scope link
blackhole 10.244.166.128/26 proto bird
172.17.0.0/16 dev docker0 proto kernel scope link src 172.17.0.1
192.168.50.0/24 dev ens33 proto kernel scope link src 192.168.50.10 metric 100其中,第 2 条的路由规则表明 10.244.104.0/26 网段的数据包通过 bird 协议由 ens33 设备发往网关 192.168.50.11。这也就定义了目的 ip 为 node2 上 pod 请求的走向。第 3 条路由规则与之类似。
实验+抓包验证
开启一个实验,在两台node分别部署两个pod,从 node1 上的 pod1 ping node2 上的 pod2的IP。

集群网络环境如下:
node1 网卡 ens33:192.168.1.11
pod1 ip:10.244.36.66
node2 网卡 ens33:192.168.1.12
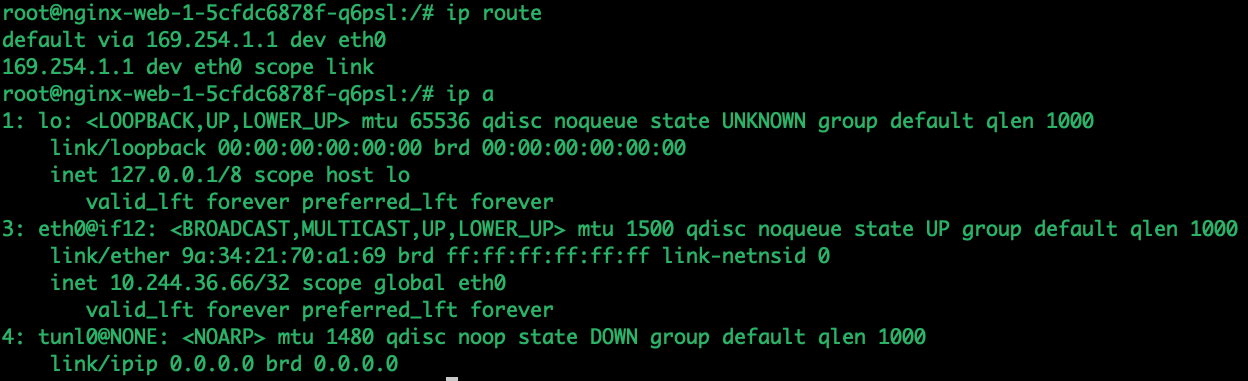
pod2 ip:10.244.169.129进入pod1地址,查看路由和IP
apt-get install netplan.io -y
ip route
ip addr

我们看到pod的eth0网卡的IP地址为10.244.36.66,veth pair的设备为if12,又因为该pod部署在node01,因此我们在node01主机通过匹配路由,找到的设备为cali52074d225a7,因此我们对cali4b1c9341321设备抓包
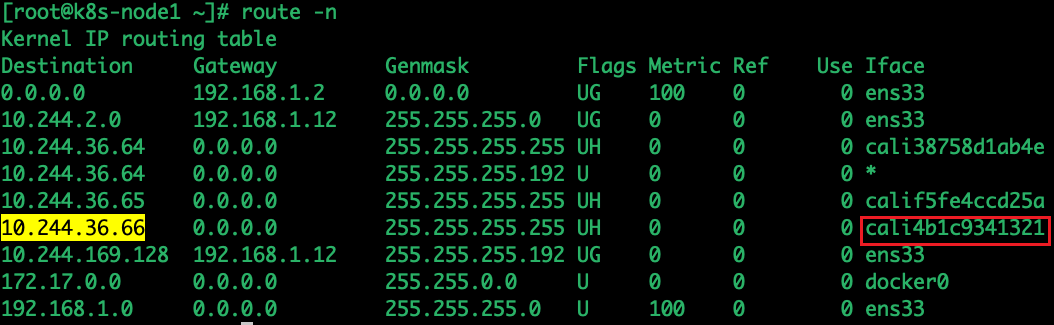
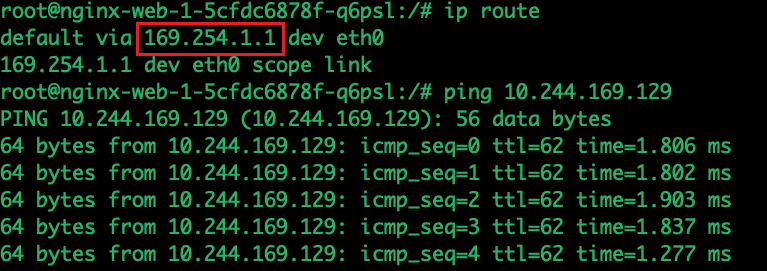
tcpdump -i cali4b1c9341321在node1所在的pod中ping node2的pod
sudo apt-get install iputils-ping
ping 10.244.169.129 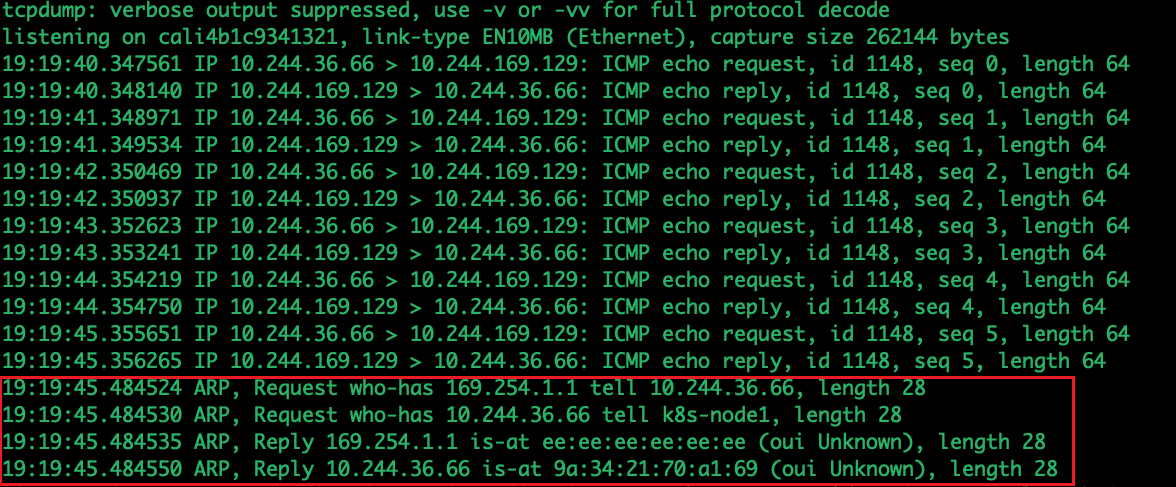
通过上面的抓包发现Ping的请求包源地址:10.244.36.66,目的地址为:10.244.169.129。 同时发送了两个ARP请求who-has 169.254.1.1 和who-has 10.244.36.66。
同时在node01的ens33(192.168.1.11)网卡上抓包
tcpdump -i ens33 -ne host 10.244.169.129
上面看到转包的源地址是192.168.1.11,源MAC是00:0c:29:1e:53:19,这个Mac地址就是 node01(192.168.1.11)主机的mac地址

上面看到转包的目的地址是192.168.1.11,目的MAC是00:0c:29:1c:f7:a0,这个Mac地址就是 node02(192.168.1.12)主机的mac地址

查看node1的路由
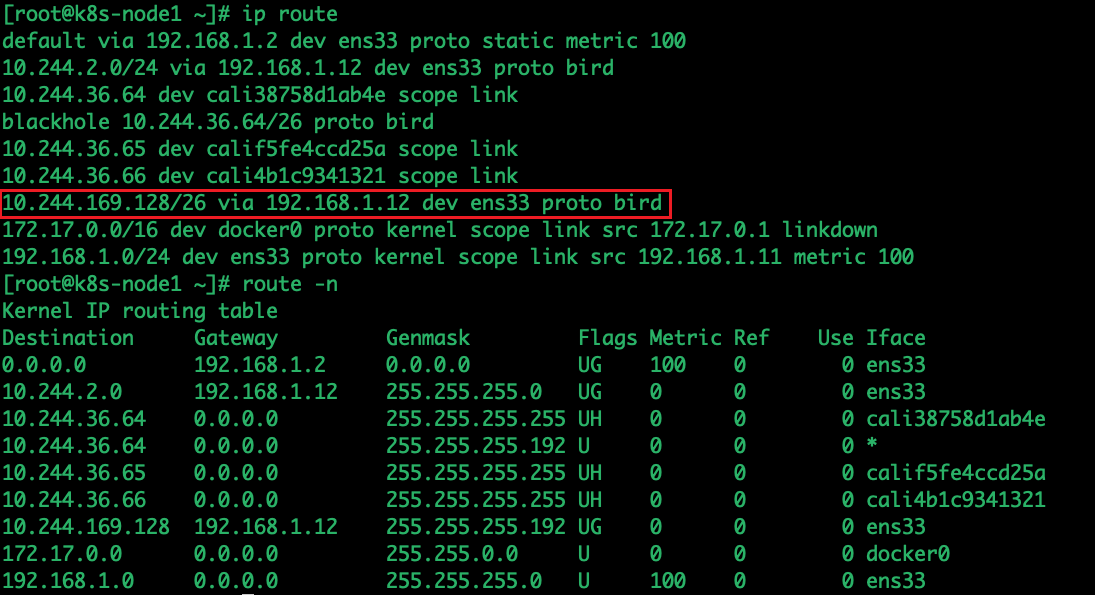
tips:10.244.169.128/26 是一个CIDR,CIDR表示法的末尾的 "/26" 表示网络中有26个连续的比特用于网络标识,剩下的6个比特用于主机标识,在10.244.169.128到10.244.169.191,10.244.169.129在这个范围内
服务器发现要发到10.244.169.129,而10.244.169.128/26 via 192.168.1.12 dev ens33 proto bird指定的网关是192.168.1.12,广播找到192.168.1.12的mac地址是00:0c:29:1c:f7:a0,因此将数据包的目的mac地址改成00:0c:29:1c:f7:a0
同时也在node02的ens33(192.168.1.12)网卡上抓包
tcpdump -i ens33 -ne host 10.244.169.129
calico BGP模式和flannel host-gw模式的选择:
选择 Calico 的 BGP 模式还是 Flannel 的 host-gw 模式通常取决于你的网络需求和部署环境。这两种方案有不同的优缺点,以下是它们的一些特性:
Calico BGP 模式:
1、路由的方式: Calico 使用 BGP 协议进行路由,这种方式在大规模部署和复杂网络环境中效果较好。BGP 能够提供强大的网络扩展性和灵活性。
2、性能和可扩展性: BGP 在大规模集群中的性能和可扩展性相对较好,适用于需要支持数千个节点的复杂网络拓扑。
3、网络策略: Calico 提供了丰富的网络策略功能,使得你可以定义详细的网络规则。
4、支持云和本地环境: Calico 在云环境和本地环境中都有良好的支持。
Flannel host-gw 模式:
1、简单直接: Flannel 的 host-gw 模式比较简单,直接将容器的流量映射到主机的网络命名空间中,这使得它在小规模或者简单的部署环境中更容易使用。
2、性能: 尽管相对于 BGP 有一些性能的损失,但在小规模部署中,这可能并不明显。
3、不需要外部路由器: Flannel 的 host-gw 模式不需要外部路由器的支持,这使得它在一些特殊环境中更容易部署。
如何选择:
1、规模和复杂性: 如果你的集群规模较大,拓扑比较复杂,或者需要高度的灵活性,Calico 的 BGP 模式可能更适合。
2、简单性和直观性: 如果你的部署比较小,网络拓扑相对简单,而且你更倾向于简单直观的配置,Flannel 的 host-gw 模式可能是个不错的选择。IPIP 模式
IPIP模式是calico的默认网络架构,其实这也是一种overlay的网络架构,但是比overlay更常用的vxlan模式相比更加轻量化。IPinIP就是把一个IP数据包又套在一个IP包里,即把 IP 层封装到 IP 层的一个 tunnel它的作用其实基本上就相当于一个基于IP层的网桥!一般来说,普通的网桥是基于mac层的,根本不需 IP,而这个 ipip 则是通过两端的路由做一个 tunnel,把两个本来不通的网络通过点对点连接起来.
IPIP通信原理
IPIP的calico-node启动后会拉起一个linux系统的tunnel虚拟网卡tunl0, 并由二进制文件allocateip给它分配一个calico IPPool中的地址,log记录在本机的/var/log/calico/cni目录下。tunl0是linux支持的隧道设备接口,当有这个接口时,出这个主机的IP包就会本封装成IPIP报文。同样的,当有数据进来时也会通过该接口解封IPIP报文。然后IPIP模式的网络通信模型如下图所示。
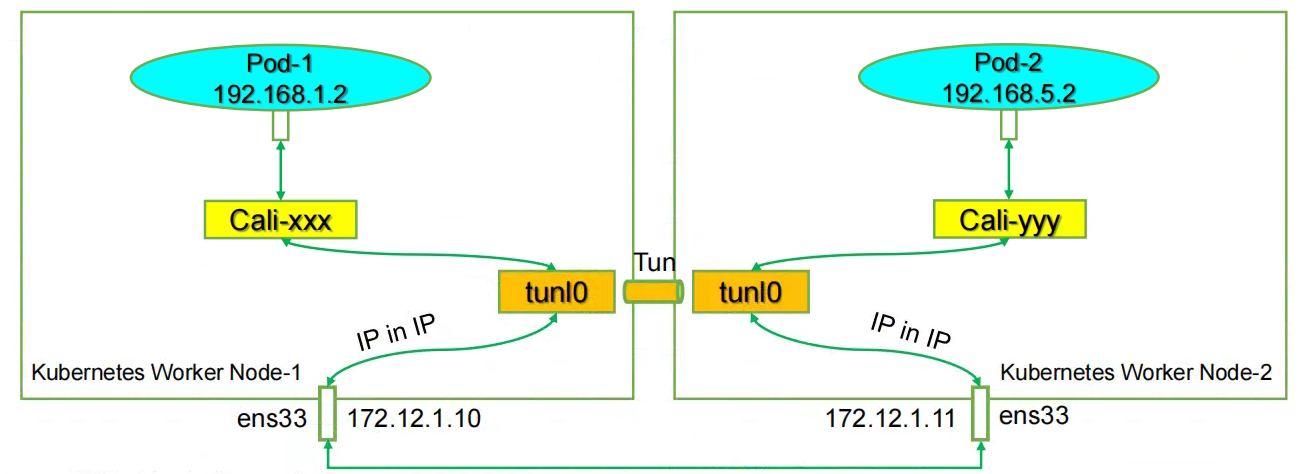
上图所示的通信如下:
- Pod-1 -> calixxx -> tunl0 -> eth0 <----> eth0 -> calixxx -> tunl0 -> Pod-2 1.c1访问c2时,ip包会出现在calixxx
- 根据c1宿主机中的路由规则中的下一跳,使用tunl0设备将ip包发送到c2的宿主机
- tunl0是一种ip隧道设备,当ip包进入该设备后,会被Linux中的ipip驱动将该ip包直接封装在宿主机网络的ip包中,然后发送到c2的宿主机
- 进入c2的宿主机后,该ip包会由ipip驱动解封装,获取原始的ip包,然后根据c2宿主机中路由规则发送到calixxx。
其中calicoctl get ippool -o wide还可以用calicoctl get ippool -o yaml来查看更加详细的信息。
tunl0 最后把IP包通过哪个网卡传送出本主机,需要看本机(假设本机主机名是A)的calico是通过哪个网卡和外部建立BGP连接的。可以通过查看上面的calicoctl node status来查看A的对端(假设是B),然后再到对端B上可以看到它和A的那个网卡建立了BGP连接。这个可以通过配置calico-node daemonset的IP autodetect相关属性来指定那块网卡来建立BGP连接
IPIP通信实例
修改为IPIP 模式:
kubectl edit ippool
IPIP 模式的 calico 使用了 tunl0 设备,这是一个 IP 隧道设备。IP 包进入 tunl0 后,内核会将原始 IP 包直接封装在宿主机的 IP 包中;封装后的 IP 包的目的地址为下一跳地址,即 node2 的 IP 地址。由于宿主机之间已经使用路由器配置了三层转发,所以这个 IP 包在离开 node 1 之后,就可以经过路由器,最终发送到 node 2 上。如下图所示。
由于 IPIP 模式的 Calico 额外多出了封包和拆包的过程,集群的网络性能受到了影响,所以在集群的二层网络通的情况下,建议不要使用 IPIP 模式。
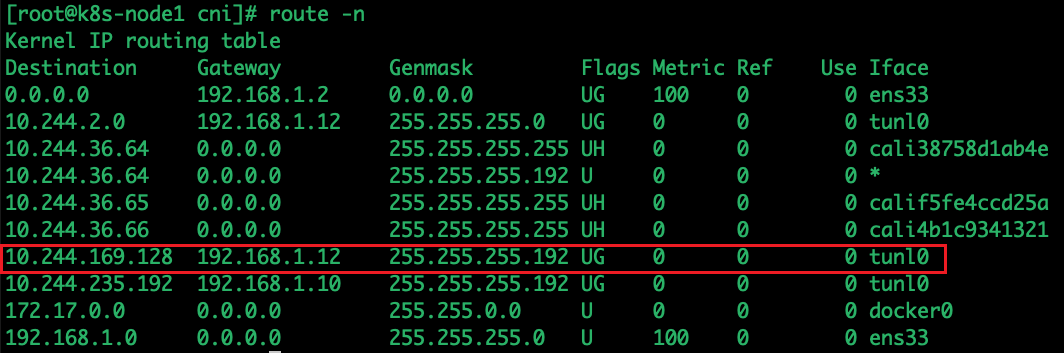
上述图解中 node1 上的路由信息:
~ ip route
default via 192.168.50.1 dev ens33 proto static metric 100
10.244.104.0/26 via 192.168.50.11 dev tunl0 proto bird onlink
10.244.135.0/26 via 192.168.50.12 dev tunl0 proto bird onlink
blackhole 10.244.166.128/26 proto bird
10.244.166.129 dev calif3c799362a5 scope link
172.17.0.0/16 dev docker0 proto kernel scope link src 172.17.0.1
192.168.50.0/24 dev ens33 proto kernel scope link src 192.168.50.10 metric 100路由实验+抓包验证:
从 node1 上的 pod1 访问到 node2 上的 pod2

集群网络环境如下:
node1 网卡 ens33:192.168.1.11
node1 tunl0:10.244.36.67/32
pod1 ip:10.244.36.66
node2 网卡 ens33:192.168.1.12
node2 tunl0:10.244.169.130/32
pod2 ip:10.244.169.129IPIP的calico-node启动后会拉起一个linux系统的tunnel虚拟网卡tunl0, 并由二进制文件allocateip给它分配一个calico IPPool中的地址,如下:

log记录在本机的/var/log/calico/cni目录下。tunl0是linux支持的隧道设备接口,当有这个接口时,出这个主机的IP包就会本封装成IPIP报文。同样的,当有数据进来时也会通过该接口解封IPIP报文。
查看node1宿主机中的路由规则中的下一跳,使用tunl0设备将ip包发送到node2的宿主机
当ip包进入该设备后,会被Linux中的ipip驱动将该ip包直接封装在宿主机网络的ip包中,然后发送到node2的宿主机
进入node2的宿主机后,该ip包会由ipip驱动解封装,获取原始的ip包,然后根据node2宿主机中路由规则发送到calixxx
查看node1 pod中的路由和网卡信息
具体分析:
calico所管理的容器内部联通主机外部网络的方法都是一样的,用linux支持的veth-pair。
1:首先在pod内部看到的eth0@if12为容器的网卡,这个12表示的是主机网络命名空间下的12号ip link.另一端是主机网络空间下的cali4b1c9341321,这个cali4b1c9341321是VethNameForWorkload函数利用容器属性计算的加密字符的前11个字符,可以通过IP-路由联系或ip -d addr show在主机上看到,如下:


可以看到,不光是当前pod的calixxx的MAC地址,其他的pod的calixxx的MAC地址也都是ee:ee:ee:ee:ee:ee,这样的配置简化了操作,使得容器会把报文交给169.254.1.1来处理,但是这个地址是本地保留的地址也可以说是个无效地址,但是通过veth-pair会传递到对端calixxx上,因为calixxx网卡开启了arpproxy,所以它会代答所有的ARP请求,让容器的报文都发到calixxx上,也就是发送到主机网络栈,再由主机网络栈的路由来送到下一站. 可以通过cat /proc/sys/net/ipv4/conf/calixxx/proxy_arp/来查看arpproxy开启状态,输出都是1。

这里注意,calico要响应arp请求还需要具备三个条件,否则容器内的ARP显示异常:
1:宿主机的arp代理得打开
2:宿主机需要有访问目的地址的明确路由,这里我理解为宿主机要有默认路由
3:发送arp request的接口与接收arp request的接口不能相同,即容器中的默认网关不能是calico的虚拟网关从pod1 ping pod2
可以看到默认路由是169.254.1.1,所有的包都从eth0出去
在node1的cali4b1c9341321网卡抓包,输出如下:
pod中的eth0与cali4b1c9341321是一对veth pair,因此,cali4b1c9341321接收到的ip流向一定与pod中的eth0相同,为 10.244.36.66 -> 10.244.169.129
tcpdump -eni cali4b1c9341321 -nnvv | grep 10.244.36.66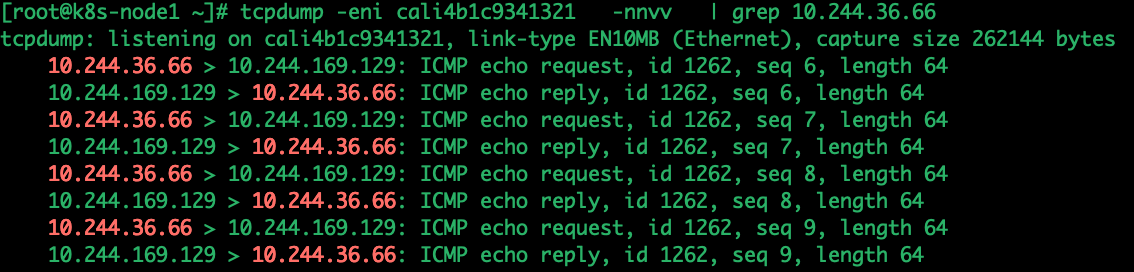
在node1的tunl0网卡抓包
查看主机路由:
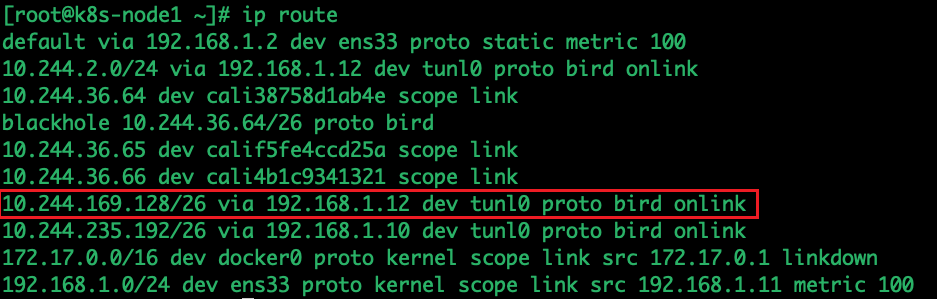
如上可以看到往10.244.169.128/26的数据包,下一跳地址是192.168.1.12,为node2的物理地址,并且所有的数据包都从tunl0出去
查看tunl0 IP:

tcpdump -eni tunl0 -nnvv | grep 10.244.36.67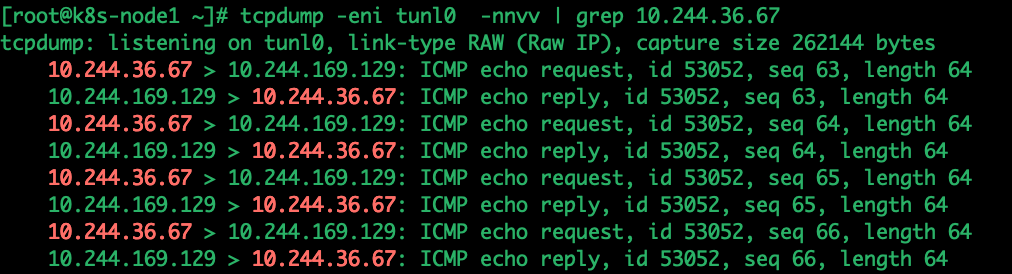
在node1的eth0网卡抓包
tcpdump -eni ens33 -nnvv | grep -i icmp可以看到在抓的包中,经过tunl0的ip报会被再封上一层ip,通过node1 的route规则,会发往ens33,因此在ens33处的抓包结果为 内部封装地址走向显示:10.244.36.67 > 10.244.169.129 外部地址流量走向:192.168.1.11 > 192.168.1.12
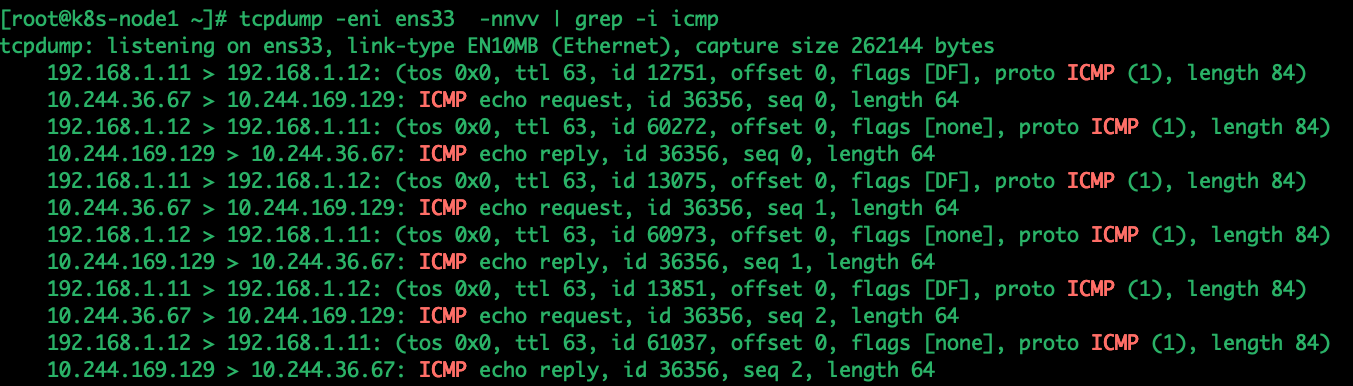
我们也可以将抓的包通过wireshark分析,过滤条件为:
ip.src==10.244.36.67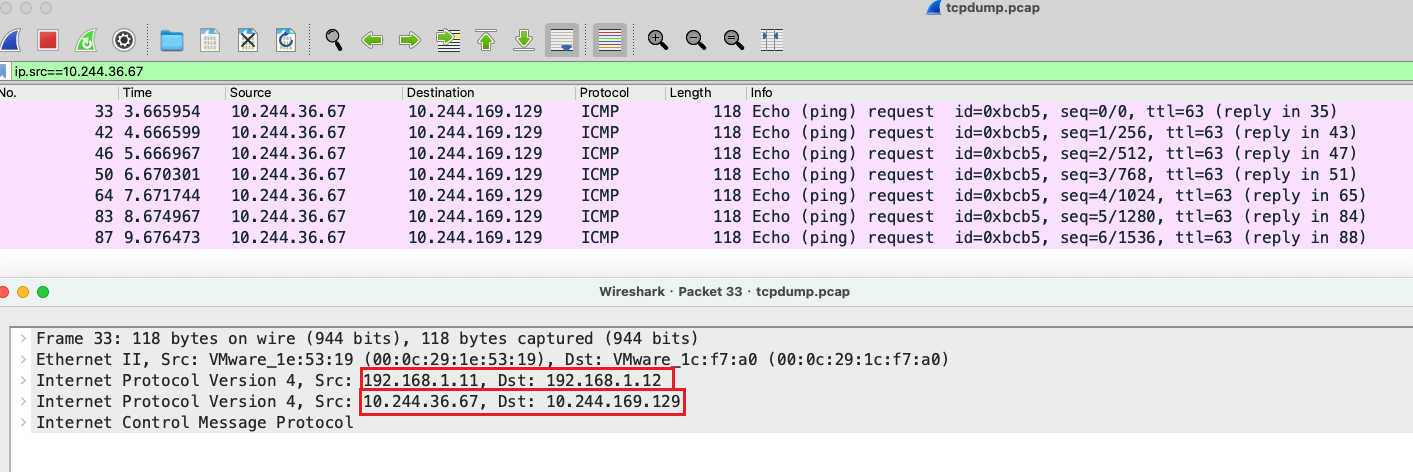
可以看到,IP 包在 tunl0 设备中被封装进了另一个 IP 包,其目的 IP 为 node2 的 IP,源 IP 为 node1 的 IP。
总结
Calico 主要采用了 BGP 协议交换路由,没有采用 cni0 网桥,当二层网络不通的时候,可以采用 IPIP 模式,但由于涉及到封包拆包的过程,性能相对较弱,与 Flannel 的 VXLAN 模式相当。
BGP 模式 / Route Reflector 模式(RR)
本文档配置一个Calico RR组,如果要配置多个组,参考链接:https://kubesphere.io/zh/blogs/calico-guide/
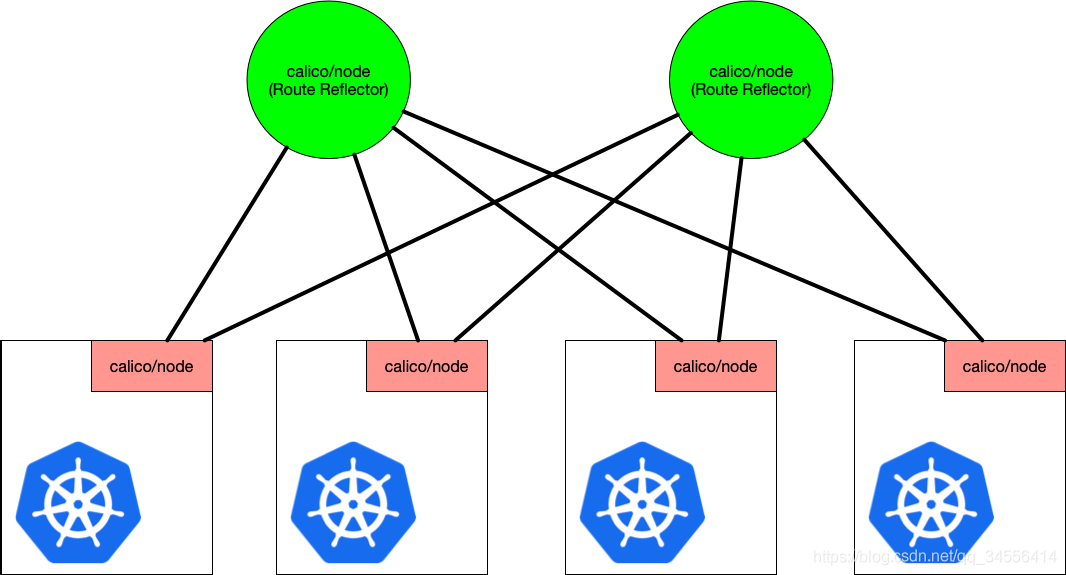
Calico 维护的网络在默认是(Node-to-Node Mesh)全互联模式,Calico集群中的节点之间都会相互建立连接,用于路由交换。但是随着集群规模的扩大,mesh模式将形成一个巨大服务网格,连接数成倍增加,就会产生性能问题。这时就需要使用 Route Reflector(路由器反射)模式解决这个问题。
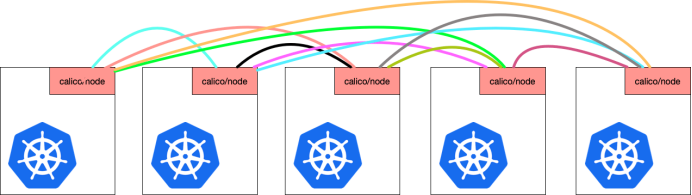
三个节点之间都建立了互连的关系,也就是一个节点要和其他节点建立TCP连接,这个就是BGP之间互联通信,要是节点好多的话连接就会好多
这个就是BGP client里面有个进程叫bird,这个bird就是负责BGP协议的通信完成路由表学习,随着连接的增多,下面这两个也会增多,使用的端口是179。

在每个节点启动的BGP pod 这里面就包含了bgp client和flex

为了解决上面问题,使用路由反射,从集群当中找出两个节点,这两个节点是自己选择的,将这两个节点当作路由反射器,让其他的BGP client通过这两个节点获取路由表的信息,这两个路由反射器相对于代理的角色,其他人都是从这获取路由表的学习,那么压力就集中在这两台,做路由的集中下发,BGP client就是从这里面获取所有的路由表。所以每个节点只要和路由反射器建立关系就行,有两个路由反射器就建立两个连接。
1、关闭 Full-Mesh 模式
Calico 默认是 Full-mesh 全互联模式,Calico 集群中的的节点之间都会建立连接,进行路由交换。但是随着集群规模的扩大,mesh 模式将形成一个巨大服务网格,连接数成倍增加。这时就需要使用 Route Reflector(路由器反射)模式解决这个问题。确定一个或多个 Calico 节点充当路由反射器,让其他节点从这个 RR 节点获取路由信息。
关闭 node-to-node BGP 网络,具体操作步骤如下:
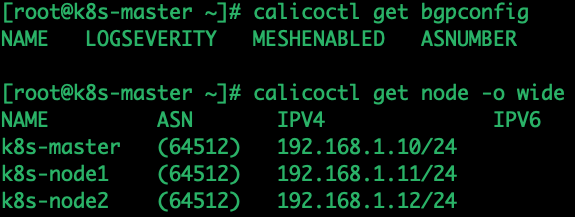
创建 bgpconf.yaml 文件,添加 default BGP 配置,调整 nodeToNodeMeshEnabled 和 asNumber:
vim bgpconfig.yaml
apiVersion: projectcalico.org/v3
kind: BGPConfiguration
metadata:
name: default
spec:
logSeverityScreen: Info
nodeToNodeMeshEnabled: false
asNumber: 64512直接应用一下,应用之后会马上禁用 Full-Mesh:
calicoctl apply -f bgpconfig.yaml

查看 BGP 网络配置情况,false 为关闭 calicoctl get bgpconfig

跨节点访问不了Pod了


2、修改工作节点的 Calico 配置
通过 calicoctl get nodes --output=wide 可以获取各节点的 **ASN**号:
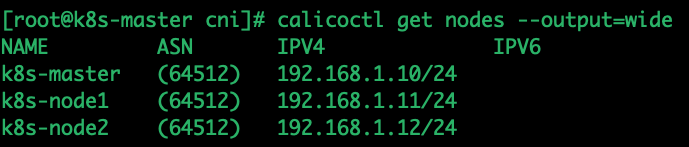
可以看到获取的 ASN 号都是 64512,这是因为如果不给每个节点指定 ASN 号,默认都是 64512。我们可以按照拓扑图配置各个节点的 ASN 号,不同 leaf 交换机下的节点,ASN 号不一样,每个 leaf 交换机下的工作节点和 leaf 交换机组成一个独立自治系统。
通过如下命令,获取工作节点的 Calico 配置信息:
calicoctl get node k8s-node1 -o yaml > k8s-node1.yamlapiVersion: projectcalico.org/v3
kind: Node
metadata:
annotations:
projectcalico.org/kube-labels: '{"beta.kubernetes.io/arch":"amd64","beta.kubernetes.io/os":"linux","kubernetes.io/arch":"amd64","kubernetes.io/hostname":"k8s-node1","kubernetes.io/os":"linux"}'
labels:
beta.kubernetes.io/arch: amd64
beta.kubernetes.io/os: linux
kubernetes.io/arch: amd64
kubernetes.io/hostname: k8s-node1
kubernetes.io/os: linux
name: k8s-node1
spec:
addresses:
- address: 192.168.1.11/24
type: CalicoNodeIP
- address: 192.168.1.11
type: InternalIP
bgp:
asNumber: 64512 ## asNumber 根据自己需要进行修改,这些改为跟上联leaf交换机一样的as号
ipv4Address: 192.168.1.11/24
routeReflectorClusterID: 192.168.1.11 ## routeReflectorClusterID一般改成自己节点的IP地址
ipv4IPIPTunnelAddr: 10.244.36.67
orchRefs:
- nodeName: k8s-node1
orchestrator: k8s
status:
podCIDRs:
- 10.244.1.0/24执行如下命令使配置生效(以上配置格式去除了相应的状态参数,我们需要删除掉相应的状态参数修改成上面的格式才能执行成功:resourceVersion: ""字段一定要删除掉,否则会报错 Failed to apply 'Node' resource: [update conflict: Node(k8s-node1)]):
calicoctl apply -f k8s-node1.yaml
其他节点修改方式同上

将所有节点的 Calico 配置信息全部修改之后,通过 calicoctl get nodes -o wide 命令获取到的节点信息如下:
上面可以看到所有的 ASN 号都已变为手动指定的,不再是全局默认的
3、为 node 节点进行分组(添加label)
为方便让 BGPPeer 轻松选择节点,在 Kubernetes 集群中,我们需要将所有节点通过打 label 的方式进行分组,这里,我们将 label 标签分为下面几种:
rr-group 这里定义为节点所属的 Calico RR 组,有 rr1 ,如果有其他的节点可以定义rr2,rr3.... 为不同 leaf 交换机下的 Calico RR
rr-id 这里定义为所属 Calico RR 的 ID,节点添加了该标签说明该节点作为了路由反射器
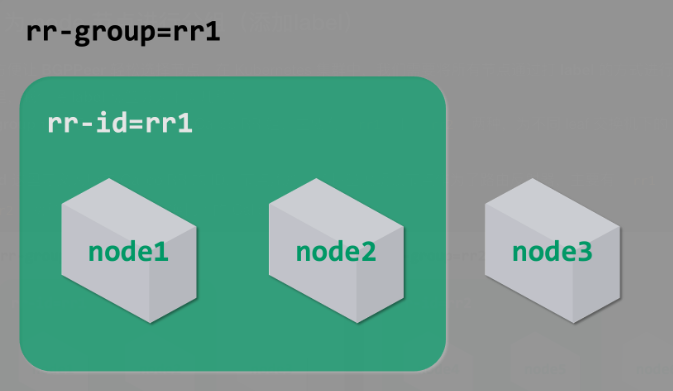
按照上图通过以下命令为每个节点添加 label :
kubectl label nodes k8s-master rr-group=rr1
kubectl label nodes k8s-node1 rr-group=rr1
kubectl label nodes k8s-node2 rr-group=rr1
kubectl label nodes k8s-node1 rr-id=rr1
kubectl label nodes k8s-node2 rr-id=rr1kubectl get nodes --show-labelsNAME STATUS ROLES AGE VERSION LABELS
k8s-master Ready control-plane,master 7d6h v1.23.0 beta.kubernetes.io/arch=amd64,beta.kubernetes.io/os=linux,kubernetes.io/arch=amd64,kubernetes.io/hostname=k8s-master,kubernetes.io/os=linux,node-role.kubernetes.io/control-plane=,node-role.kubernetes.io/master=,node.kubernetes.io/exclude-from-external-load-balancers=,rr-group=rr1
k8s-node1 Ready <none> 7d6h v1.23.0 beta.kubernetes.io/arch=amd64,beta.kubernetes.io/os=linux,kubernetes.io/arch=amd64,kubernetes.io/hostname=k8s-node1,kubernetes.io/os=linux,rr-group=rr1,rr-id=rr1
k8s-node2 Ready <none> 7d6h v1.23.0 beta.kubernetes.io/arch=amd64,beta.kubernetes.io/os=linux,kubernetes.io/arch=amd64,kubernetes.io/hostname=k8s-node2,kubernetes.io/os=linux,rr-group=rr1,rr-id=rr14、配置BGPPeer
在配置 BGPPeer 之前,我们可以先查看一下各个 node BGP 的节点状态,因为已经禁用了 Full-mesh,并且现在还没有配置 BGPPeer,所以所有节点里的信息都是空的。
根据环境拓扑,k8s-node1 和 k8s-node2 作为 Calico RR,需要和 server leaf1 交换机建立iBGP 连接;k8s-master1、k8s-node1 和 k8s-node2 需要和 RR1 建立 iBGP 连接
RR1 和 server leaf1 建立 iBGP 连接
vim rr1-to-leaf1-peer.yaml
apiVersion: projectcalico.org/v3
kind: BGPPeer
metadata:
name: rr1-to-leaf1-peer ## 给 BGPPeer 取一个名称,方便识别
spec:
nodeSelector: rr-id == 'rr1' ## 通过节点选择器添加有 rr-id == 'rr1' 标签的节点
# peerIP: 10.254.254.3 ## server leaf1 交换机的 loopback 地址,这里没有交换机的话可以不配置
asNumber: 64512 ## server leaf1 交换机的 AS 号calicoctl apply -f rr1-to-leaf1-peer.yaml
RR1 和自己所属的节点建立 iBGP 连接
RR1 所属的节点主要有 k8s-master1、k8s-node1 和 k8s-node2,也就是打了 rr-group=rr1 标签的节点,配置文件编写如下:
vim rr1-to-node-peer.yaml
apiVersion: projectcalico.org/v3
kind: BGPPeer
metadata:
name: rr1-to-node-peer ## 给 BGPPeer 取一个名称,方便识别
spec:
nodeSelector: rr-group == 'rr1' ## 通过节点选择器添加有 rr-group == ‘rr1’标签的节点
peerSelector: rr-id == 'rr1' ## 通过 peer 选择器添加有rr-id == ‘rr1’标签的路由反射器calicoctl apply -f rr1-to-node-peer.yaml
5、配置 server leaf1 交换机
有交换机才可以配置,略
现在网络就可以通了
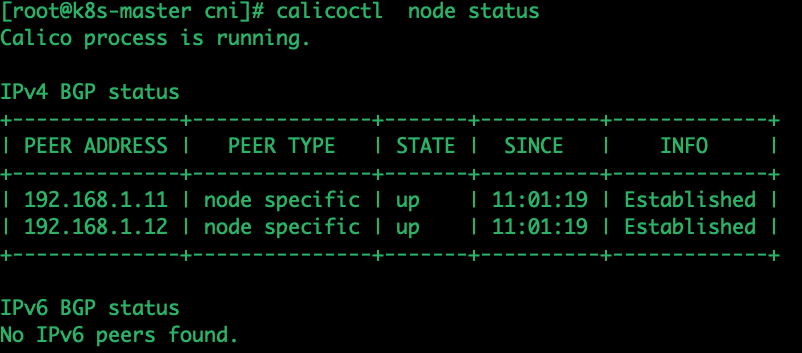
node1、node2上测试跨节点网络联通性
ss -antp | grep ESTAB | grep 179 | grep bird

最好两个及以上路由反射节点,冗余来保证多可用性 ,其他节点依然可以获取到路由表。
calico网络策略:
详见:https://www.ljh.cool/33941.html 网络访问控制部分
cilium
Cilium 是一款开源软件,为在 Linux 容器管理平台(如 Kubernetes)上部署的应用服务透明地提供网络和 API 连接,并保障这些网络和连接的安全。
Cilium 的底层技术利用 Linux 内核的新技术 eBPF,可以在 Linux 系统中动态实现安全性、可见性和网络控制逻辑。 Cilium 基于 eBPF 提供了多集群路由、替代 kube-proxy 实现负载均衡、透明加密以及网络和服务安全等诸多功能。 除了提供传统的网络安全之外,eBPF 的灵活性还支持应用协议和 DNS 请求/响应安全。 同时,Cilium 与 Envoy 紧密集成,提供了基于 Go 的扩展框架。 因为 eBPF 运行在 Linux 内核中,所以无需对应用程序代码或容器配置进行任何更改就可以应用所有 Cilium 功能。
基于微服务的应用程序分为小型独立服务,这些服务使用 HTTP、gRPC、Kafka 等轻量级协议通过 API 相互通信。 但是,现有的 Linux 网络安全机制(例如 iptables)仅在网络和传输层(即 IP 地址和端口)上运行,并且缺乏对微服务层的可见性。
Cilium 为 Linux 容器框架(如 Docker 和 Kubernetes)带来了 API 感知网络安全过滤。 通过 eBPF 技术,Cilium 提供了一种基于容器 / 容器标识来定义和实施网络层和应用层安全策略的方法。
eBPF
说到eBPF我们就必须要了解它的前身 BPF(Berkeley Packet Filter ),中文翻译为伯克利包过滤器,是类 Unix 系统上数据链路层的一种原始接口,提供原始链路层封包的收发。1992 年,Steven McCanne 和 Van Jacobson 写了一篇名为《BSD数据包过滤:一种新的用户级包捕获架构》的论文。在文中,作者描述了他们如何在 Unix 内核实现网络数据包过滤,这种新的技术比当时最先进的数据包过滤技术快 20 倍。BPF 在数据包过滤上引入了两大革新:
- 一个新的虚拟机 (VM) 设计,可以有效地工作在基于寄存器结构的 CPU 之上;
- 应用程序使用缓存只复制与过滤数据包相关的数据,不会复制数据包的所有信息。这样可以最大程度地减少BPF 处理的数据;
由于这些巨大的改进,所有的 Unix 系统都选择采用 BPF 作为网络数据包过滤技术,直到今天,许多 Unix 内核的派生系统中(包括 Linux 内核)仍使用该实现。
BPF 的架构图如下:

2014 年初,Alexei Starovoitov 实现了 eBPF(extended Berkeley Packet Filter)。经过重新设计,eBPF 演进为一个通用执行引擎,可基于此开发性能分析工具、软件定义网络等诸多场景。eBPF 最早出现在 3.18 内核中,此后原来的 BPF 就被称为经典 BPF,缩写 cBPF(classic BPF),cBPF 现在已经基本废弃。现在,Linux 内核只运行 eBPF,内核会将加载的 cBPF 字节码透明地转换成 eBPF 再执行。
eBPF 新的设计针对现代硬件进行了优化,所以 eBPF 生成的指令集比旧的 BPF 解释器生成的机器码执行得更快。扩展版本也增加了虚拟机中的寄存器数量,将原有的 2 个 32 位寄存器增加到 10 个 64 位寄存器。由于寄存器数量和宽度的增加,开发人员可以使用函数参数自由交换更多的信息,编写更复杂的程序。总之,这些改进使 eBPF 版本的速度比原来的 BPF 提高了 4 倍。eBPF 实现的最初目标是优化处理网络过滤器的内部 BPF 指令集。当时,BPF 程序仍然限于内核空间使用,只有少数用户空间程序可以编写内核处理的 BPF 过滤器,例如:tcpdump和 seccomp。时至今日,这些程序仍基于旧的 BPF 解释器生成字节码,但内核中会将这些指令转换为高性能的表示。
2014 年 6 月,eBPF 扩展到用户空间,这也成为了 BPF 技术的转折点。正如 Alexei 在提交补丁的注释中写到:“这个补丁展示了 eBPF 的潜力”。当前,eBPF 不再局限于网络栈,已经成为内核顶级的子系统。eBPF 程序架构强调安全性和稳定性,看上去更像内核模块,但与内核模块不同,eBPF 程序不需要重新编译内核,并且可以确保 eBPF 程序运行完成,而不会造成系统的崩溃。
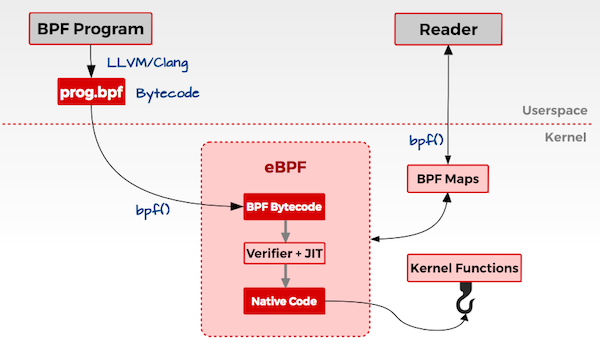
上图便是eBPF的架构图了。之后基于 eBPF 的项目如雨后春笋一样开始蓬勃发展,于是就有了Cilium 1.6,引入了 eBPF 到容器网络中。
Cilium 是如何用 eBPF 实现容器网络方案的呢?
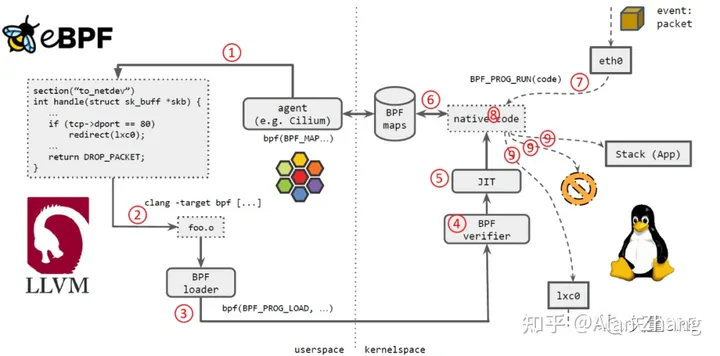
如上图所示,几个步骤:
- Cilium agent 生成 eBPF 程序。
- 用 LLVM 编译 eBPF 程序,生成 eBPF 对象文件(object file,*.o)。
- 用 eBPF loader 将对象文件加载到 Linux 内核。
- 校验器(verifier)对 eBPF 指令会进行合法性验证,以确保程序是安全的,例如 ,无非法内存访问、不会 crash 内核、不会有无限循环等。
- 对象文件被即时编译(JIT)为能直接在底层平台(例如 x86)运行的 native code。
- 如果要在内核和用户态之间共享状态,BPF 程序可以使用 BPF map,这种一种共享存储 ,BPF 侧和用户侧都可以访问。
- BPF 程序就绪,等待事件触发其执行。对于这个例子,就是有数据包到达网络设备时,触发 BPF 程序的执行。
- BPF 程序对收到的包进行处理,例如 mangle。最后返回一个裁决(verdict)结果。
- 根据裁决结果,如果是 DROP,这个包将被丢弃;如果是 PASS,包会被送到更网络栈的 更上层继续处理;如果是重定向,就发送给其他设备。
在使用基于 eBPF 的程序时,它还有以下几个优点:
- 不会引起 Kernel 崩溃。
- 执行速度和 Kernel 模块一样快。
- 提供稳定的 API。
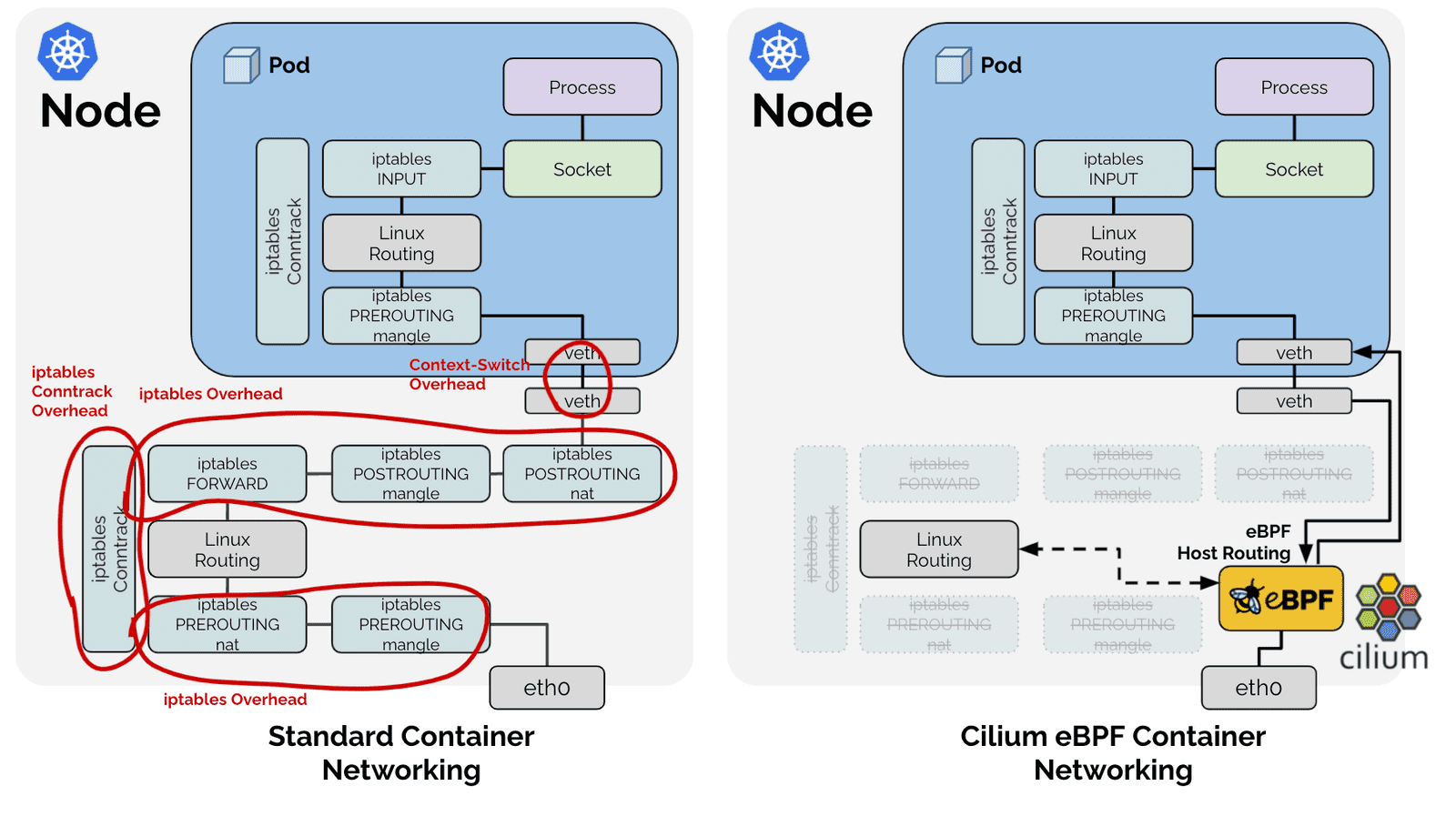
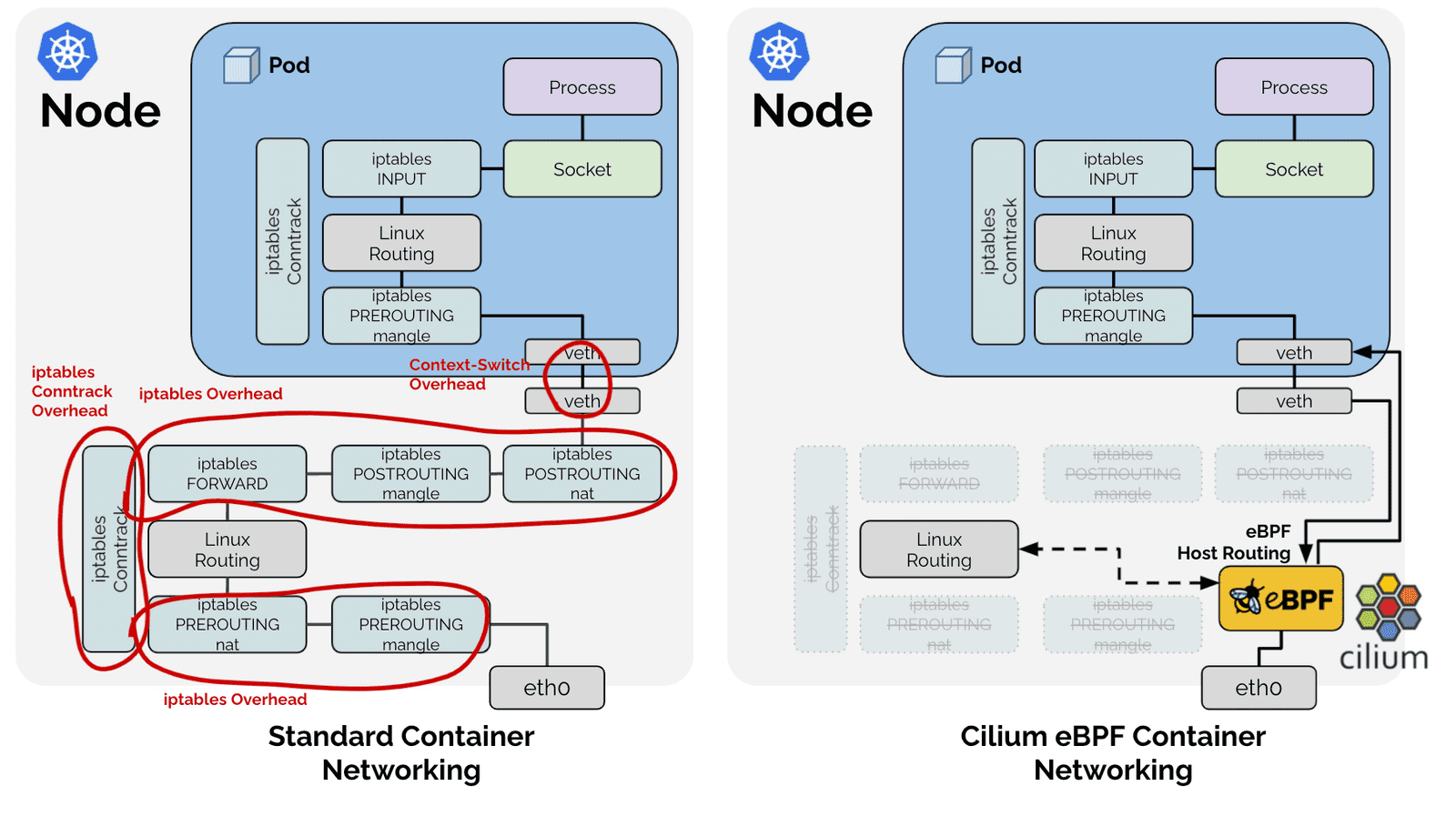
那么他是如何大幅度提高Service 的性能的呢?首先我们再复习一下 kuber-proxy 的转发路径是怎么样子的,通过下面的一张图来看一下。
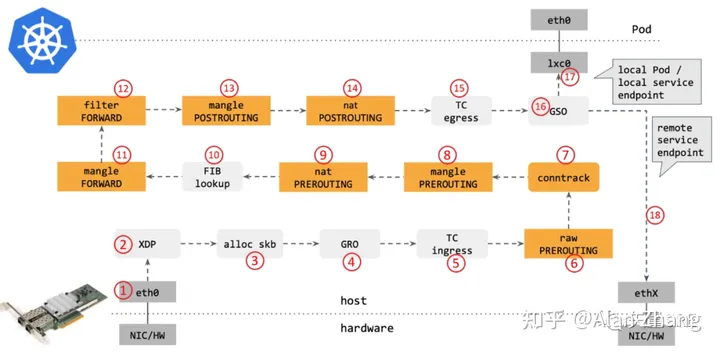
可见他的路径非常的长,所以性能怎么能好呢?那么如果使用Cilium 1.6呢?
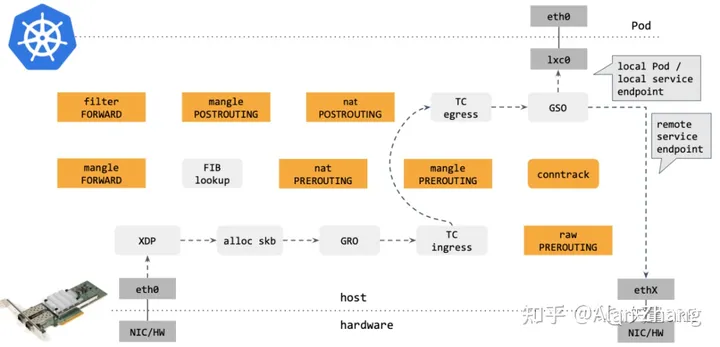

对比可以看出,Cilium eBPF datapath 做了短路处理:从 tc ingress 直接 shortcut 到 tc egress,节省了 9 个中间步骤(总共 17 个)。更重要的是:这个 datapath 绕过了 整个 Netfilter 框架(橘黄色的框),Netfilter 在大流量情况下性能是很差的。
图中网卡的 XDP 技术是 eXpress DataPath 的缩写,支持在网卡驱动中运行 eBPF 代码,为Linux内核提供了高性能、可编程的网络数据路径。由于网络包在还未进入网络协议栈之前就处理,避免了用户态,内核态来回切换的开销,因此它给 Linux 网络带来了巨大的性能提升(性能比DPDK还要高)。
所以 Cilium 通过引入 eBPF 大幅提升了 Service 的网络性能。
由于不需要修改内核就可以完成原本要在内核才能做到的事情,因此功能强大,eBPF也逐渐在观测、跟踪、性能调优、安全和网络等领域发挥重要的角色
cilium
一个多么痛的领悟: 当kubernetes发展到一定规模后,维护的成本也跟随升高, 特别是在某些链路很长,网络很复杂的场景下,对在网络的deubg, 链路可观测方面提出更高要求, 但这恰恰是eBPF的强项,Google更是宣布使用Cilium 作为 GKE 的下一代数据面, 作为第一个通过ebpf实现了kube-proxy所有功能的网络插件,那cilium到底有什么魔力呢?
摘一段官网的介绍:
Cilium is open source software for transparently securing the network connectivity between application services deployed using Linux container management platforms like Docker and Kubernetes
因此: 当在kubernetes中需要开箱即用解决以下问题时:
- 服务依赖关系和通信图
- 哪些服务正在相互通信?有多频繁?服务依赖关系图是什么样子的?
- 正在进行哪些HTTP调用?服务从哪些Kafka主题消费或生产到哪些Kafka主题?
- 网络监控和警报
- 是否有网络通信故障?为什么通信失败?是DNS吗?是应用程序问题还是网络问题?第4层(TCP)或第7层(HTTP)上的通信是否中断?
- 哪些服务在过去5分钟内遇到了DNS解析问题?哪些服务最近遇到了TCP连接中断或连接超时?未应答TCP SYN请求的速率是多少?
- 应用程序监控
- 特定服务或所有群集中5xx或4xx HTTP响应代码的比率是多少?
- 在集群中,HTTP请求和响应之间的第95和第99百分位延迟是多少?哪些服务性能最差?两个服务之间的延迟是多少?
- 安全可观察性
- 哪些服务的连接因网络策略而被阻止?从群集外部访问了哪些服务?哪些服务解析了特定的DNS名称?
借助cilium,都可以得到答案。
上一张神图来说明cilium的优越性:
{kind=link}
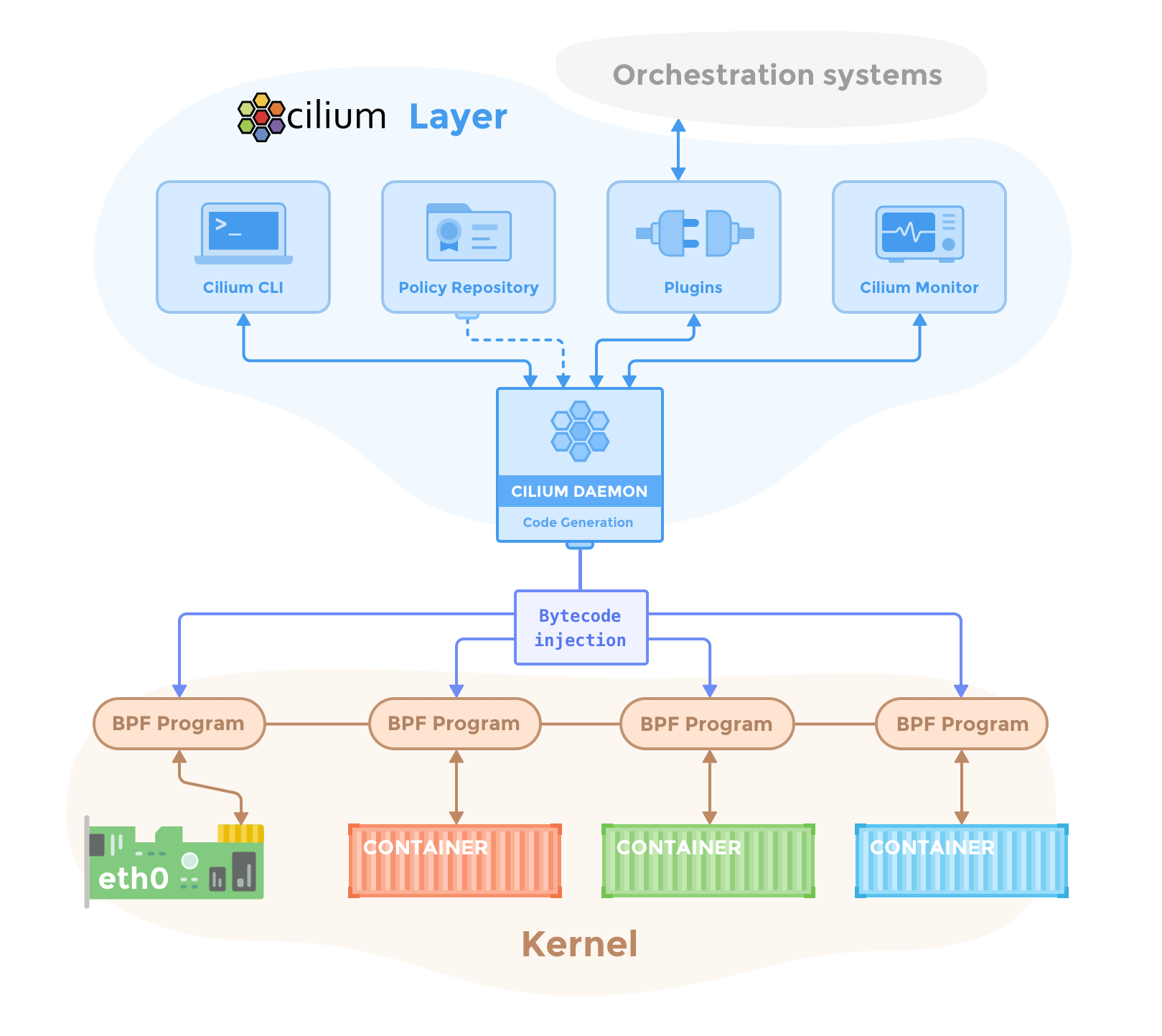
cilium由好几部分构成:
- cilium-agent: cilium-agent在集群中的每个节点上运行(通常以daemonset方式运行)agent通过Kubernetes或API接受配置,这些配置描述了网络,服务负载平衡,网络策略以及可见性和监控要求。
Cilium agent监听来自编排系统(如Kubernetes)的事件,以了解容器或工作负载何时启动和停止。它管理Linux内核用来控制进出这些容器的所有网络访问的eBPF程序。
- cilium-client: Cilium client是随Cilium-agent一起安装的命令行工具(即部署在cilium-agent的容器中)。它与运行在同一节点上的Cilium agent的REST API交互。同时允许检查本地代理的状态。它还提供了直接访问eBPF映射以验证其状态的工具。
- cilium-cli: 官方还出了一个命令行工具, 就叫cilium, 可以直接运行在集群之外(类似kubectl这类的客户端, 通过token或者kubeconfig方式访问apiserver), 它与cilium-client的命令有些区别
注: cilium-client是 get from client-agent,而clium-cli是整个cilium cluster的命令行工具
- cilium-operator: Cilium Operator负责管理集群(逻辑上是为整个集群处理一次,而不是为集群中的每个节点处理一次),Cilium operator不在任何转发或网络策略决策的关键路径中。如果operator暂时不可用,群集通常会继续运行。但是,根据配置的不同,operator的可用性故障可能导致:
- IP地址管理(IPAM)延迟,因此,如果要求operator分配新的IP地址,则会延迟新工作负载的调度
- 更新kvstore心跳密钥失败,这将导致代理程序声明kvstore不健康并重新启动。
要注意,cilium operator与Kubernetes中的operator概念不同, cilium operator不生成子对象,它负责全局的一些配置等 - cni plugin: cilium自身可做为kubernetes cni插件存在,且可完全替代kube-proxy的功能(这个功能是后续介绍的重点)
以上算是cilium自身的components,还有hubble, hubble是存储、展示从cilium获取的相关数据:
- hubble-server: 在每个节点上运行,并从Cilium检索基于eBPF的可见性。它被嵌入到Cilium agent中,以实现高性能和低开销。它提供了一个gRPC服务来检索流和Prometheus指标。
- hubble-relay: hubble-relay是一个独立的组件,它可以感知所有正在运行的Hubble服务器,并通过连接到它们各自的gRPC API并提供表示集群中所有服务器的API来提供集群范围的可见性。
- hubble-cli: 是一个命令行工具,能够连接到hubble-relay的gRPC API或本地服务器以检索流事件。
- hubble-ui: 图形用户界面,可以在该界面上查看网络调用关系。
虽然有些hubble功能被内嵌到cilium中,但hubble对于cilium来说不是必需的
另外, cilium也有数据库(data-store),用来在代理之间传播状态。它支持以下数据存储:
- Kubernetes crds(默认)
存储任何数据和传播状态的默认选择是使用Kubernetes自定义资源定义(CRD)。Kubernetes为集群组件提供CRD,以通过Kubernetes资源表示配置和状态。
- key-value存储
状态存储和传播的所有要求都可以通过Cilium默认配置中配置的Kubernetes CRD来满足。键值存储库可以可选地用作优化以提高集群的可扩展性,因为直接使用键值存储库会使更改通知和存储需求更有效。
可使用etcd做为key-value数据库,当然可以直接使用Kubernetes的etcd集群,也可以维护一个专用的etcd集群
Weave
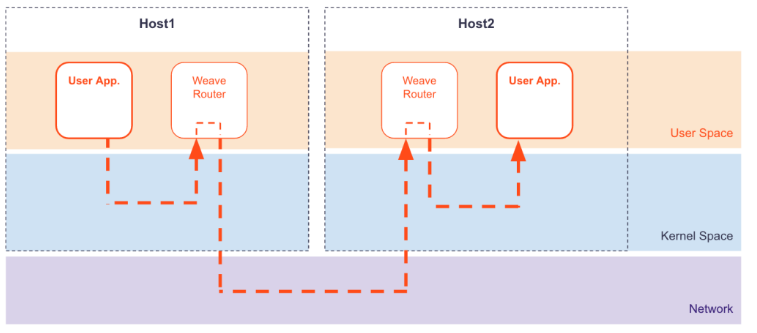
Weave Net是一个多主机容器网络方案,支持去中心化的控制平面,各个host上的wRouter间通过建立Full Mesh的TCP链接,并通过Gossip来同步控制信息。这种方式省去了集中式的K/V Store,能够在一定程度上减低部署的复杂性,Weave将其称为“data centric”,而非RAFT或者Paxos的“algorithm centric”。
数据平面上,Weave通过UDP封装实现L2 Overlay,封装支持两种模式:
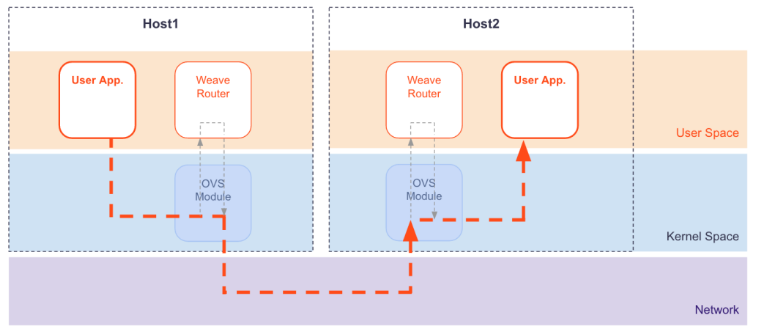
- 运行在user space的sleeve mode:通过pcap设备在Linux bridge上截获数据包并由wRouter完成UDP封装,支持对L2 traffic进行加密,还支持Partial Connection,但是性能损失明显。
- 运行在kernal space的 fastpath mode:即通过OVS的odp封装VxLAN并完成转发,wRouter不直接参与转发,而是通过下发odp 流表的方式控制转发,这种方式可以明显地提升吞吐量,但是不支持加密等高级功能。
Sleeve Mode:
Fastpath Mode:
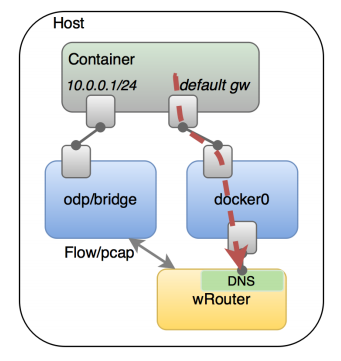
关于Service的发布,weave做的也比较完整。首先,wRouter集成了DNS功能,能够动态地进行服务发现和负载均衡,另外,与libnetwork 的overlay driver类似,weave要求每个POD有两个网卡,一个就连在lb/ovs上处理L2 流量,另一个则连在docker0上处理Service流量,docker0后面仍然是iptables作NAT。
Weave已经集成了主流的容器系统
- Docker: https://www.weave.works/docs/net/latest/plugin/
- Kubernetes: https://www.weave.works/docs/net/latest/kube-addon/
kubectl apply -f https://git.io/weave-kube
- CNI: https://www.weave.works/docs/net/latest/cni-plugin/
- Prometheus: https://www.weave.works/docs/net/latest/metrics/
Weave Kubernetes
kubectl apply -n kube-system -f "https://cloud.weave.works/k8s/net?k8s-version=$(kubectl version | base64 | tr -d '\n')"这会在所有Node上启动Weave插件以及Network policy controller:
$ ps -ef | grep weave | grep -v grep
root 25147 25131 0 16:22 ? 00:00:00 /bin/sh /home/weave/launch.sh
root 25204 25147 0 16:22 ? 00:00:00 /home/weave/weaver --port=6783 --datapath=datapath --host-root=/host --http-addr=127.0.0.1:6784 --status-addr=0.0.0.0:6782 --docker-api= --no-dns --db-prefix=/weavedb/weave-net --ipalloc-range=10.32.0.0/12 --nickname=ubuntu-0 --ipalloc-init consensus=2 --conn-limit=30 --expect-npc 10.146.0.2 10.146.0.3
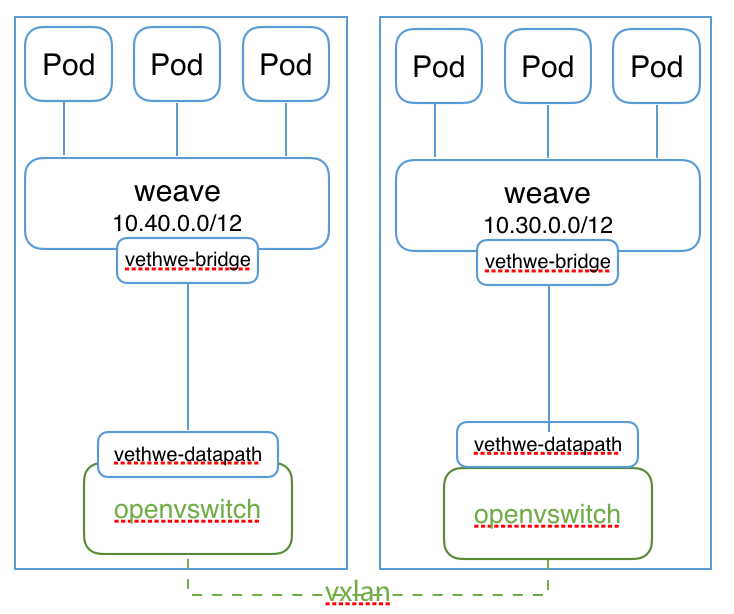
root 25669 25654 0 16:22 ? 00:00:00 /usr/bin/weave-npc这样,容器网络为
- 所有容器都连接到weave网桥
- weave网桥通过veth pair连到内核的openvswitch模块
- 跨主机容器通过openvswitch vxlan通信
- policy controller通过配置iptables规则为容器设置网络策略
Weave Scope
Weave Scope是一个容器监控和故障排查工具,可以方便的生成整个集群的拓扑并智能分组(Automatic Topologies and Intelligent Grouping)。
Weave Scope主要由scope-probe和scope-app组成
+--Docker host----------+
| +--Container------+ | .---------------.
| | | | | Browser |
| | +-----------+ | | |---------------|
| | | scope-app |<---------| |
| | +-----------+ | | | |
| | ^ | | | |
| | | | | '---------------'
| | +-------------+ | |
| | | scope-probe | | |
| | +-------------+ | |
| | | |
| +-----------------+ |
+-----------------------+- 去中心化
- 故障自动恢复
- 加密通信
- Multicast networking
- UDP模式性能损失较大
发布者:LJH,转发请注明出处:https://www.ljh.cool/39649.html