
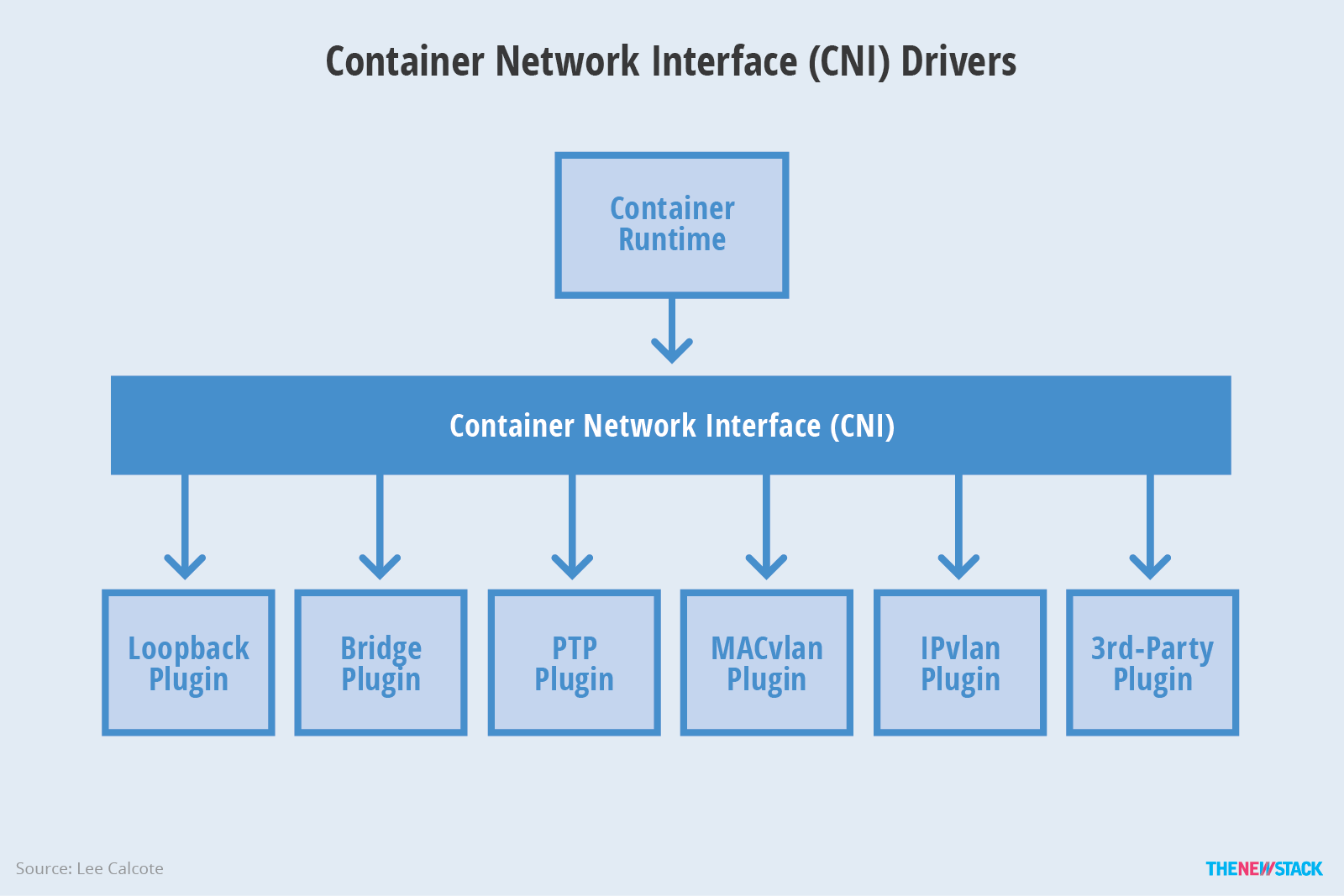
Container Network Interface (CNI)是一个云原生计算基金会项目,它包含了一些规范和库,用于编写在 Linux 容器中配置网络接口的一系列插件。CNI 只关注容器的网络连接,并在容器被删除时移除所分配的资源。Kubernetes 使用 CNI 作为网络提供商和 Kubernetes Pod 网络之间的接口。
CNI最早是由CoreOS发起的容器网络规范,是Kubernetes网络插件的基础。其基本思想为:Container Runtime在创建容器时,先创建好network namespace,然后调用CNI插件为这个netns配置网络,其后再启动容器内的进程。现已加入CNCF,成为CNCF主推的网络模型。有关更多信息,请访问 CNI GitHub 项目。
以Flannel网络组件为例,当部署Flanneld后,会在每台宿主机上生成它对应的CNI配置文件(它其实是一个ConfigMap),从而告诉Kubernetes要使用Flannel 作为容器网络方案。
CNI配置文件默认路径:/etc/cni/net.d
当kubelet 组件需要创建Pod 的时候,先调用dockershim它先创建一个Infra 容器。然后调用CNI 插件为Infra 容器配置网络。
这两个路径可在kubelet启动参数中定义:
--network-plugin=cni --cni-conf-dir=/etc/cni/net.d --cni-bin-dir=/opt/cni/bin
CNI插件包括两部分:
- CNI Plugin负责给容器配置网络,它包括两个基本的接口
- 配置网络: AddNetwork(net NetworkConfig, rt RuntimeConf) (types.Result, error)
- 清理网络: DelNetwork(net NetworkConfig, rt RuntimeConf) error
- IPAM Plugin负责给容器分配IP地址,主要实现包括host-local和dhcp。
Kubernetes Pod 中的其他容器都是Pod所属pause容器的网络,创建过程为:
- kubelet 先创建pause容器生成network namespace
- 调用网络CNI driver
- CNI driver 根据配置调用具体的cni 插件
- cni 插件给pause 容器配置网络
- pod 中其他的容器都使用 pause 容器的网络

这里补充一个知识点:
pause容器在k8s中,被当作pod中所有容器的父容器,它为Pod提供一个沙箱(sandbox)环境。pause容器有两个核心的功能:
- 第一,它提供整个pod的Linux命名空间的基础。
- 第二,启用PID命名空间,它在每个pod中都作为PID为1进程,并回收僵尸进程。
CNI 基础
所有CNI插件均支持通过环境变量和标准输入传入参数:
$ echo '{"cniVersion": "0.3.1","name": "mynet","type": "macvlan","bridge": "cni0","isGateway": true,"ipMasq": true,"ipam": {"type": "host-local","subnet": "10.244.1.0/24","routes": [{ "dst": "0.0.0.0/0" }]}}' | sudo CNI_COMMAND=ADD CNI_NETNS=/var/run/netns/a CNI_PATH=./bin CNI_IFNAME=eth0 CNI_CONTAINERID=a CNI_VERSION=0.3.1 ./bin/bridge
$ echo '{"cniVersion": "0.3.1","type":"IGNORED", "name": "a","ipam": {"type": "host-local", "subnet":"10.1.2.3/24"}}' | sudo CNI_COMMAND=ADD CNI_NETNS=/var/run/netns/a CNI_PATH=./bin CNI_IFNAME=a CNI_CONTAINERID=a CNI_VERSION=0.3.1 ./bin/host-local最简单的CNI网络插件Bridge
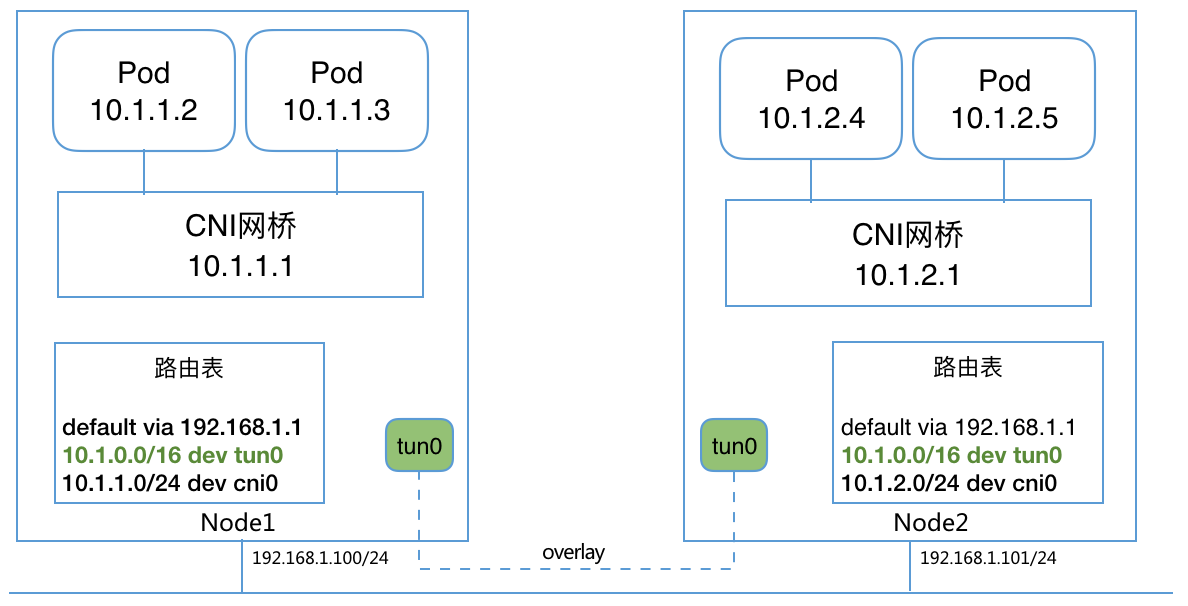
Bridge是最简单的CNI网络插件,它首先在Host创建一个网桥,然后再通过veth pair连接该网桥到container netns。

注意:Bridge模式下,多主机网络通信需要额外配置主机路由,或使用overlay网络。可以借助Flannel或者Quagga动态路由等来自动配置。比如overlay情况下的网络结构为
配置示例
{
"cniVersion": "0.3.0",
"name": "mynet",
"type": "bridge",
"bridge": "mynet0",
"isDefaultGateway": true,
"forceAddress": false,
"ipMasq": true,
"hairpinMode": true,
"ipam": {
"type": "host-local",
"subnet": "10.10.0.0/16"
}
}# export CNI_PATH=/opt/cni/bin
# ip netns add ns
# /opt/cni/bin/cnitool add mynet /var/run/netns/ns
{
"interfaces": [
{
"name": "mynet0",
"mac": "0a:58:0a:0a:00:01"
},
{
"name": "vethc763e31a",
"mac": "66:ad:63:b4:c6:de"
},
{
"name": "eth0",
"mac": "0a:58:0a:0a:00:04",
"sandbox": "/var/run/netns/ns"
}
],
"ips": [
{
"version": "4",
"interface": 2,
"address": "10.10.0.4/16",
"gateway": "10.10.0.1"
}
],
"routes": [
{
"dst": "0.0.0.0/0",
"gw": "10.10.0.1"
}
],
"dns": {}
}
# ip netns exec ns ip addr
1: lo: <LOOPBACK> mtu 65536 qdisc noop state DOWN group default qlen 1
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
9: eth0@if8: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc noqueue state UP group default
link/ether 0a:58:0a:0a:00:04 brd ff:ff:ff:ff:ff:ff link-netnsid 0
inet 10.10.0.4/16 scope global eth0
valid_lft forever preferred_lft forever
inet6 fe80::8c78:6dff:fe19:f6bf/64 scope link tentative dadfailed
valid_lft forever preferred_lft forever
# ip netns exec ns ip route
default via 10.10.0.1 dev eth0
10.10.0.0/16 dev eth0 proto kernel scope link src 10.10.0.4IPAM
DHCP
DHCP插件是最主要的IPAM插件之一,用来通过DHCP方式给容器分配IP地址,在macvlan插件中也会用到DHCP插件。
在使用DHCP插件之前,需要先启动dhcp daemon:
/opt/cni/bin/dhcp daemon &
然后配置网络使用dhcp作为IPAM插件
{
...
"ipam": {
"type": "dhcp",
}
}host-local
host-local是最常用的CNI IPAM插件,用来给container分配IP地址。
IPv4:
{
"ipam": {
"type": "host-local",
"subnet": "10.10.0.0/16",
"rangeStart": "10.10.1.20",
"rangeEnd": "10.10.3.50",
"gateway": "10.10.0.254",
"routes": [
{ "dst": "0.0.0.0/0" },
{ "dst": "192.168.0.0/16", "gw": "10.10.5.1" }
],
"dataDir": "/var/my-orchestrator/container-ipam-state"
}
}IPv6:
{
"ipam": {
"type": "host-local",
"subnet": "3ffe:ffff:0:01ff::/64",
"rangeStart": "3ffe:ffff:0:01ff::0010",
"rangeEnd": "3ffe:ffff:0:01ff::0020",
"routes": [
{ "dst": "3ffe:ffff:0:01ff::1/64" }
],
"resolvConf": "/etc/resolv.conf"
}
}IPVLAN
IPVLAN 和 MACVLAN 类似,都是从一个主机接口虚拟出多个虚拟网络接口。一个重要的区别就是所有的虚拟接口都有相同的 mac 地址,而拥有不同的 ip 地址。因为所有的虚拟接口要共享 mac 地址,所以有些需要注意的地方:
- DHCP 协议分配 ip 的时候一般会用 mac 地址作为机器的标识。这个情况下,客户端动态获取 ip 的时候需要配置唯一的 ClientID 字段,并且 DHCP server 也要正确配置使用该字段作为机器标识,而不是使用 mac 地址
IPVLAN支持两种模式:
- L2 模式:此时跟macvlan bridge 模式工作原理很相似,父接口作为交换机来转发子接口的数据。同一个网络的子接口可以通过父接口来转发数据,而如果想发送到其他网络,报文则会通过父接口的路由转发出去。
- L3 模式:此时ipvlan 有点像路由器的功能,它在各个虚拟网络和主机网络之间进行不同网络报文的路由转发工作。只要父接口相同,即使虚拟机/容器不在同一个网络,也可以互相 ping 通对方,因为 ipvlan 会在中间做报文的转发工作。注意 L3 模式下的虚拟接口 不会接收到多播或者广播的报文(这个模式下,所有的网络都会发送给父接口,所有的 ARP 过程或者其他多播报文都是在底层的父接口完成的)。另外外部网络默认情况下是不知道 ipvlan 虚拟出来的网络的,如果不在外部路由器上配置好对应的路由规则,ipvlan 的网络是不能被外部直接访问的。
创建ipvlan的简单方法为
ip link add link <master-dev> <slave-dev> type ipvlan mode { l2 | L3 }cni配置格式为
{
"name": "mynet",
"type": "ipvlan",
"master": "eth0",
"ipam": {
"type": "host-local",
"subnet": "10.1.2.0/24"
}
}需要注意的是
- ipvlan插件下,容器不能跟Host网络通信
- 主机接口(也就是master interface)不能同时作为ipvlan和macvlan的master接口
MACVLAN
MACVLAN可以从一个主机接口虚拟出多个macvtap,且每个macvtap设备都拥有不同的mac地址(对应不同的linux字符设备)。MACVLAN支持四种模式
- bridge模式:数据可以在同一master设备的子设备之间转发
- vepa模式:VEPA 模式是对 802.1Qbg 标准中的 VEPA 机制的软件实现,MACVTAP 设备简单的将数据转发到master设备中,完成数据汇聚功能,通常需要外部交换机支持 Hairpin 模式才能正常工作
- private模式:Private 模式和 VEPA 模式类似,区别是子 MACVTAP 之间相互隔离
- passthrough模式:内核的 MACVLAN 数据处理逻辑被跳过,硬件决定数据如何处理,从而释放了 Host CPU 资源
创建macvlan的简单方法为
ip link add link <master-dev> name macvtap0 type macvtapcni配置格式为
{
"name": "mynet",
"type": "macvlan",
"master": "eth0",
"ipam": {
"type": "dhcp"
}
}需要注意的是
- macvlan需要大量 mac 地址,每个虚拟接口都有自己的 mac 地址
- 无法和 802.11(wireless) 网络一起工作
- 主机接口(也就是master interface)不能同时作为ipvlan和macvlan的master接口
CNI 插件
常见的CNI网络插件

Kubernetes 它需要网络插件来提供集群内部和集群外部的网络通信。以下是一些常用的 k8s 网络插件:
- Flannel:Flannel 是最常用的 k8s 网络插件之一,它使用了虚拟网络技术来实现容器之间的通信,支持多种网络后端,如 VXLAN、UDP 和 Host-GW。
- Calico:Calico 是一种基于 BGP 的网络插件,它使用路由表来路由容器之间的流量,支持多种网络拓扑结构,并提供了安全性和网络策略功能。
- Canal:Canal 是一个组合了 Flannel 和 Calico 的网络插件,它使用 Flannel 来提供容器之间的通信,同时使用 Calico 来提供网络策略和安全性功能。
- Weave Net:Weave Net 是一种轻量级的网络插件,它使用虚拟网络技术来为容器提供 IP 地址,并支持多种网络后端,如 VXLAN、UDP 和 TCP/IP,同时还提供了网络策略和安全性功能。
- Cilium:Cilium 是一种基于 eBPF (Extended Berkeley Packet Filter) 技术的网络插件,它使用 Linux 内核的动态插件来提供网络功能,如路由、负载均衡、安全性和网络策略等。
- Contiv:Contiv 是一种基于 SDN 技术的网络插件,它提供了多种网络功能,如虚拟网络、网络隔离、负载均衡和安全策略等。
- Antrea:Antrea 是一种基于 OVS (Open vSwitch) 技术的网络插件,它提供了容器之间的通信、网络策略和安全性等功能,还支持多种网络拓扑结构。
下表总结了不同的 GitHub 指标,让你了解每个项目的受欢迎程度和活动。数据收集于 2022 年 1 月。
| 提供商 | 项目 | Stars | Forks | Contributors |
| Canal | https://github.com/projectcalico/canal | 679 | 100 | 21 |
| Flannel | https://github.com/flannel-io/flannel | 7k | 2.5k | 185 |
| Calico | https://github.com/projectcalico/calico | 3.1k | 741 | 224 |
| Weave | https://github.com/weaveworks/weave/ | 6.2k | 635 | 84 |
| Cilium | https://github.com/cilium/cilium | 10.6k | 1.3k | 352 |
CNI 使用了哪些网络模型
CNI 网络插件使用封装网络模型(例如 Virtual Extensible Lan,缩写是 VXLAN)或非封装网络模型(例如 Border Gateway Protocol,缩写是 BGP)来实现网络结构
各个网络插件的 CNI 功能
下表总结了 Rancher 中每个 CNI 网络插件支持的不同功能:
| 提供商 | 网络模型 | 路线分发 | 网络策略 | 网格 | 外部数据存储 | 加密 | Ingress/Egress 策略 |
| Canal | 封装 (VXLAN) | 否 | 是 | 否 | K8s API | 是 | 是 |
| Flannel | 封装 (VXLAN) | 否 | 否 | 否 | K8s API | 是 | 否 |
| Calico | 封装(VXLAN,IPIP)或未封装 | 是 | 是 | 是 | Etcd 和 K8s API | 是 | 是 |
| Weave | 封装 | 是 | 是 | 是 | 否 | 是 | 是 |
| Cilium | 封装 (VXLAN) | 是 | 是 | 是 | Etcd 和 K8s API | 是 | 是 |
- 网络模型:封装或未封装。如需更多信息,请参阅 CNI 中使用的网络模型。
- 路由分发:一种外部网关协议,用于在互联网上交换路由和可达性信息。BGP 可以帮助进行跨集群 pod 之间的网络。此功能对于未封装的 CNI 网络插件是必须的,并且通常由 BGP 完成。如果你想构建跨网段拆分的集群,路由分发是一个很好的功能。
- 网络策略:Kubernetes 提供了强制执行规则的功能,这些规则决定了哪些 service 可以使用网络策略进行相互通信。这是从 Kubernetes 1.7 起稳定的功能,可以与某些网络插件一起使用。
- 网格:允许在不同的 Kubernetes 集群间进行 service 之间的网络通信。
- 外部数据存储:具有此功能的 CNI 网络插件需要一个外部数据存储来存储数据。
- 加密:允许加密和安全的网络控制和数据平面。
- Ingress/Egress 策略:允许你管理 Kubernetes 和非 Kubernetes 通信的路由控制。
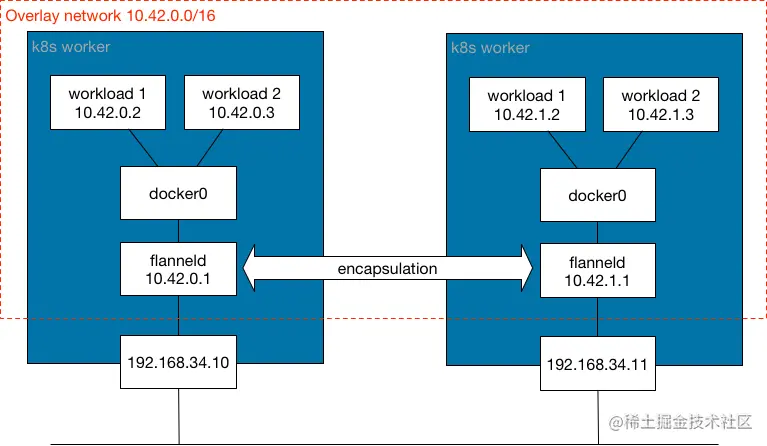
什么是封装网络?
此网络模型提供了一个逻辑二层(L2)网络,该网络封装在跨 Kubernetes 集群节点的现有三层(L3)网络拓扑上。使用此模型,你可以为容器提供一个隔离的 L2 网络,而无需分发路由。封装网络带来了少量的处理开销以及由于覆盖封装生成 IP header 造成的 IP 包大小增加。封装信息由 Kubernetes worker 之间的 UDP 端口分发,交换如何访问 MAC 地址的网络控制平面信息。此类网络模型中常用的封装是 VXLAN、Internet 协议安全性 (IPSec) 和 IP-in-IP。
简单来说,这种网络模型在 Kubernetes worker 之间生成了一种扩展网桥,其中连接了 pod。
如果你偏向使用扩展 L2 网桥,则可以选择此网络模型。此网络模型对 Kubernetes worker 的 L3 网络延迟很敏感。如果数据中心位于不同的地理位置,请确保它们之间的延迟较低,以避免最终的网络分段。
使用这种网络模型的 CNI 网络插件包括 Flannel、Canal、Weave 和 Cilium。默认情况下,Calico 不会使用此模型,但你可以对其进行配置。
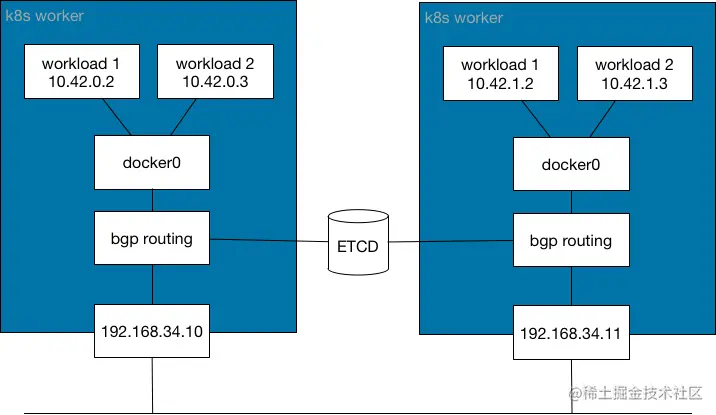
什么是非封装网络?
该网络模型提供了一个 L3 网络,用于在容器之间路由数据包。此模型不会生成隔离的 L2 网络,也不会产生开销。这些好处的代价是,Kubernetes worker 必须管理所需的所有路由分发。该网络模型不使用 IP header 进行封装,而是使用 Kubernetes Worker 之间的网络协议来分发路由信息以实现 Pod 连接,例如 BGP。
简而言之,这种网络模型在 Kubernetes worker 之间生成了一种扩展网络路由器,提供了如何连接 Pod 的信息。
如果你偏向使用 L3 网络,则可以选择此网络模型。此模型在操作系统级别为 Kubernetes Worker 动态更新路由。对延迟较不敏感。
使用这种网络模型的 CNI 网络插件包括 Calico 和 Cilium。Cilium 可以使用此模型进行配置,即使这不是默认模式。
k8s 支持哪些 CNI 插件
RKE Kubernetes 集群
Rancher 开箱即用地为 RKE Kubernetes 集群提供了几个 CNI 网络插件,分别是 Canal、Flannel、Calico 和 Weave。
如果你使用 Rancher 创建新的 Kubernetes 集群,你可以选择你的 CNI 网络插件。
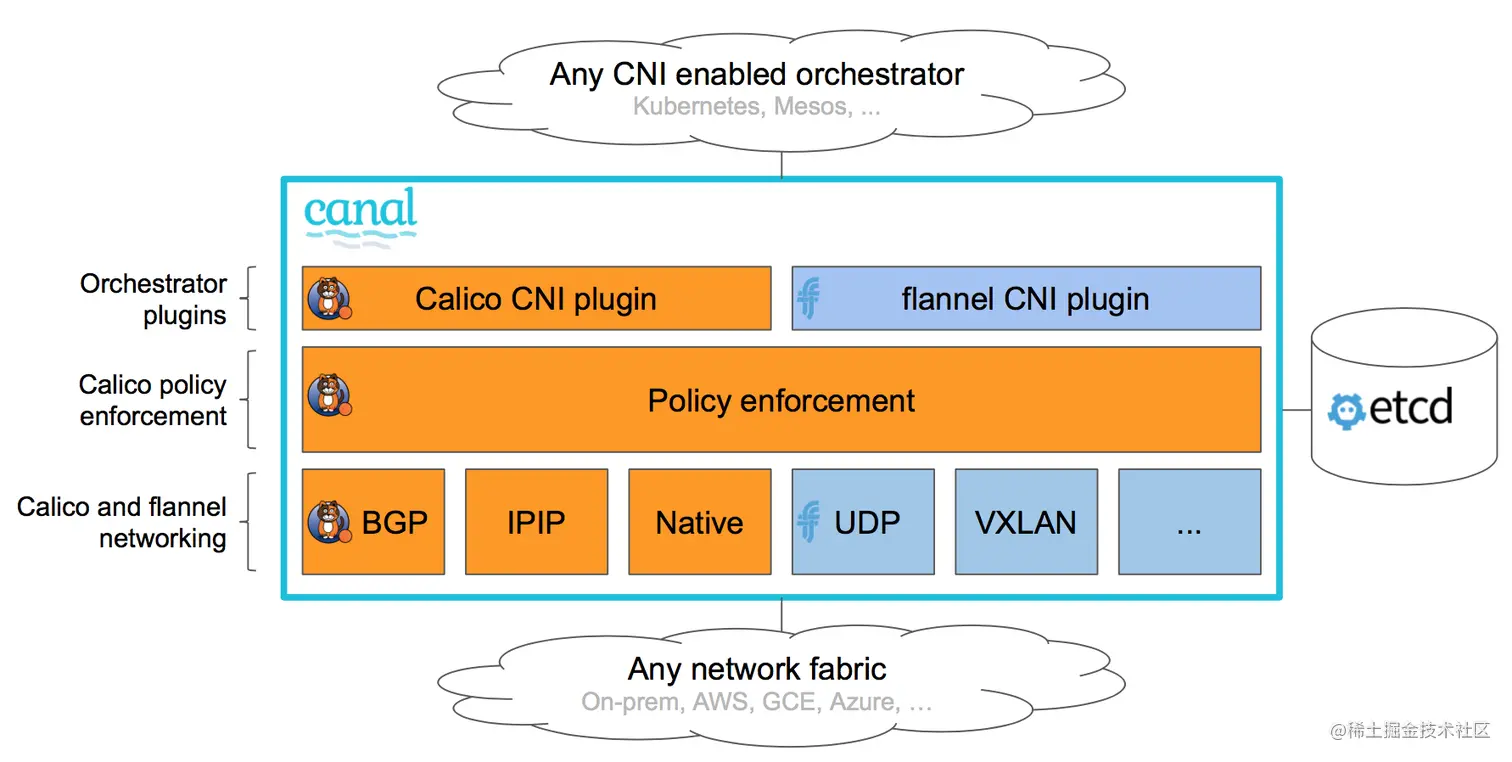
Canal
Canal 是一个 CNI 网络插件,它很好地结合了 Flannel 和 Calico 的优点。它让你轻松地将 Calico 和 Flannel 网络部署为统一的网络解决方案,将 Calico 的网络策略执行与 Calico(未封装)和 Flannel(封装)丰富的网络连接选项结合起来。
Canal 是 Rancher 默认的 CNI 网络插件,并采用了 Flannel 和 VXLAN 封装。
Kubernetes Worker 需要打开 UDP 端口 8472 (VXLAN) 和 TCP 端口 9099(健康检查)。如果使用 Wireguard,则需要打开 UDP 端口 51820 和 51821。
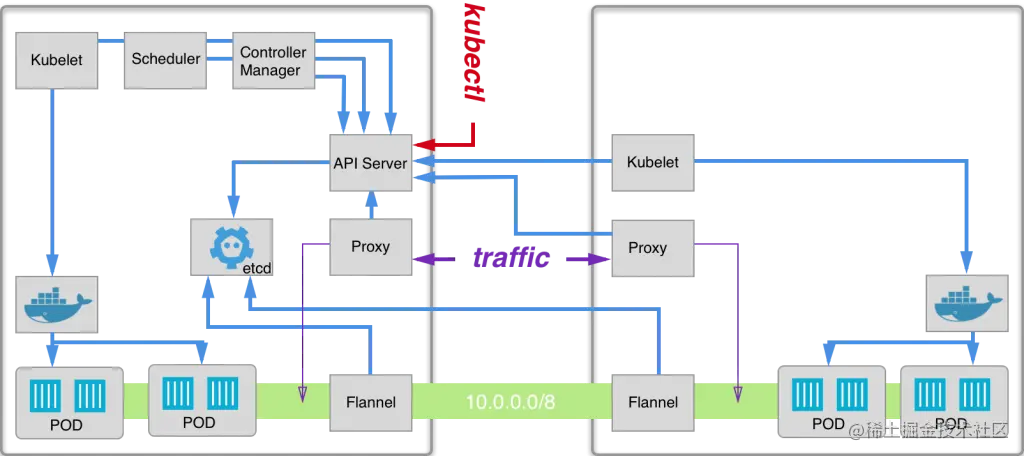
Flannel
Flannel 是为 Kubernetes 配置 L3 网络结构的简单方法。Flannel 在每台主机上运行一个名为 flanneld 的二进制 Agent,该 Agent 负责从更大的预配置地址空间中为每台主机分配子网租约。Flannel 通过 Kubernetes API 或直接使用 etcd 来存储网络配置、分配的子网、以及其他辅助数据(例如主机的公共 IP)。数据包使用某种后端机制来转发,默认封装为 VXLAN。
默认情况下,封装的流量是不加密的。Flannel 提供了两种加密方案:
- IPSec:使用 strongSwan 在 Kubernetes worker 之间建立加密的 IPSec 隧道。它是加密的实验性后端。
- WireGuard:比 strongSwan 更快的替代方案。
Kubernetes Worker 需要打开 UDP 端口 8472 (VXLAN)。
Weave
Weave 在云上的 Kubernetes 集群中启用网络和网络策略。此外,它还支持加密对等节点之间的流量。
Kubernetes worker 需要打开 TCP 端口 6783(控制端口)、UDP 端口 6783 和 UDP 端口 6784(数据端口)。有关详细信息,请参阅下游集群的端口要求。
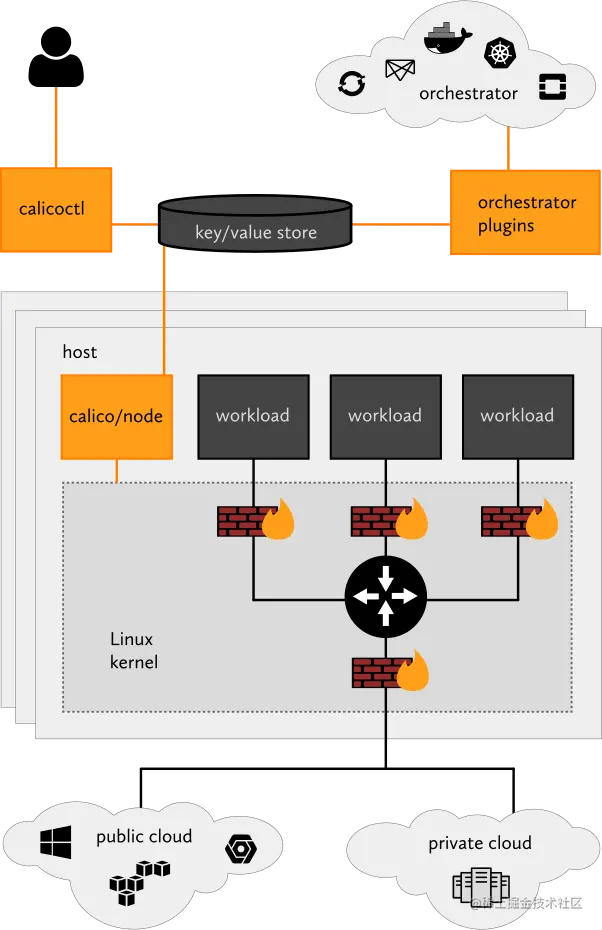
Calico
Calico 是一个基于BGP的纯三层的数据中心网络方案(不需要Overlay),并且与OpenStack、Kubernetes、AWS、GCE等IaaS和容器平台都有良好的集成。
Calico在每一个计算节点利用Linux Kernel实现了一个高效的vRouter来负责数据转发,而每个vRouter通过BGP协议负责把自己上运行的workload的路由信息像整个Calico网络内传播——小规模部署可以直接互联,大规模下可通过指定的BGP route reflector来完成。 这样保证最终所有的workload之间的数据流量都是通过IP路由的方式完成互联的。Calico节点组网可以直接利用数据中心的网络结构(无论是L2或者L3),不需要额外的NAT,隧道或者Overlay Network。
此外,Calico基于iptables还提供了丰富而灵活的网络Policy,保证通过各个节点上的ACLs来提供Workload的多租户隔离、安全组以及其他可达性限制等功能
Calico 在云上的 Kubernetes 集群中启用网络和网络策略。默认情况下,Calico 使用纯净、未封装的 IP 网络结构和策略引擎为 Kubernetes 工作负载提供网络。工作负载能够使用 BGP 在云上和本地进行通信。
Calico 还提供了一种无状态的 IP-in-IP 或 VXLAN 封装模式。如果需要,你可以使用它。Calico 还支持策略隔离,让你使用高级 ingress 和 egress 策略保护和管理 Kubernetes 工作负载。
如果使用 BGP,Kubernetes Worker 需要打开 TCP 端口 179,如果使用 VXLAN 封装,则需要打开 UDP 端口 4789。另外,使用 Typha 时需要 TCP 端口 5473。有关详细信息,请参阅下游集群的端口要求。
有关详细信息,请参阅以下页面:
Cilium
Cilium 在 Kubernetes 中启用网络和网络策略(L3、L4 和 L7)。默认情况下,Cilium 使用 eBPF 技术在节点内部路由数据包,并使用 VXLAN 将数据包发送到其他节点。你也可以配置非封装的技术。
Cilium 推荐大于 5.2 的内核版本,从而充分利用 eBPF 的能力。Kubernetes worker 需要打开 TCP 端口 8472(VXLAN)和 TCP 端口 4240(健康检查)。此外,还必须为健康检查启用 ICMP 8/0。有关详细信息,请查看 Cilium 系统要求。
Cilium 中跨节点的 Ingress 路由
默认情况下,Cilium 不允许 Pod 与其他节点上的 Pod 通信。要解决此问题,请启用 Ingress Controller 以使用 “CiliumNetworkPolicy” 进行跨节点路由请求。
选择 Cilium CNI 并为新集群启用项目网络隔离后,配置如下:
apiVersion: cilium.io/v2
kind: CiliumNetworkPolicy
metadata:
name: hn-nodes
namespace: default
spec:
endpointSelector: {}
ingress:
- fromEntities:
- remote-node发布者:LJH,转发请注明出处:https://www.ljh.cool/39620.html