
字符串截取和替换命令
printf格式化输出
printf '输出类型输出格式' 输出内容



由此可以,printf是一个格式类型加计算过程的顺序
输出类型
%ns (string)输出字符串,n是数字代表输出几个字符
%ni (int)输出整数。 n是数字代表输出几个数字
%n.mf (float)输出浮点数,n代表总位数,m代表小数位
输出格式
\a 响铃
\n 换行
\t 输出制表符,即tab键
\r 回车
\v 水平制表符
printf 命令输出文件内容
printf '%s' $(cat student.txt) (以字符串形式查看文件内容)
![]()
![]()
这样看起来很乱只能通过制表符隔开,格式化输出printf可以识别制表符分隔符

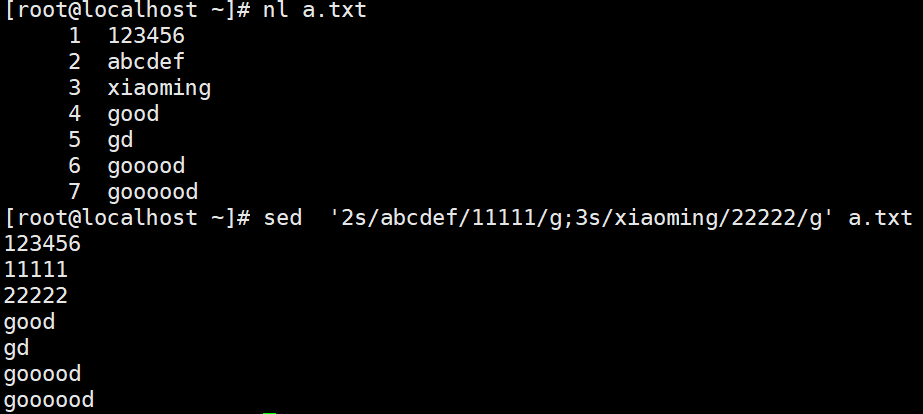
把成绩变为整型,平均成绩变为浮点型printf ' %s\t %s\t %s\t %s\t %s\t %s\t \n' $(cat student.txt) 但是发现,第一行文字不能识别成数字,然后自动变为0

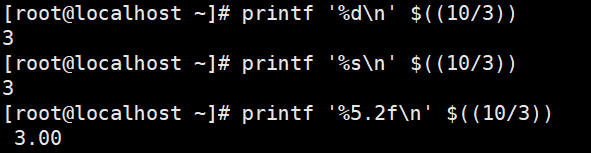
printf不识别管道符之后会联系awk命令,此时想要去除第一行字符,先print,grep 写在管道符之后,如下图

文本三剑客
回忆grep命令

局限性:只能提取行,不能提取列
选项
-o 只输出过滤内容
-i 不区分大小写
-w 以单词为单位进行过滤
-E 支持扩展正则
-n输出时带行号

-c 统计
-v取反
-A 过滤字符所在行以及其下几行(可以指定数字)
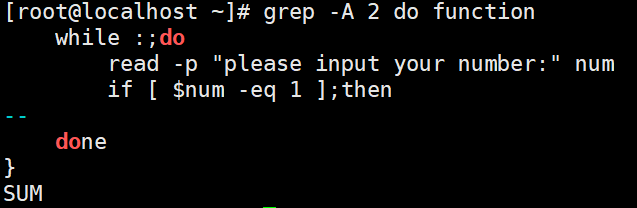
-B 过滤字符所在行以及其上几行
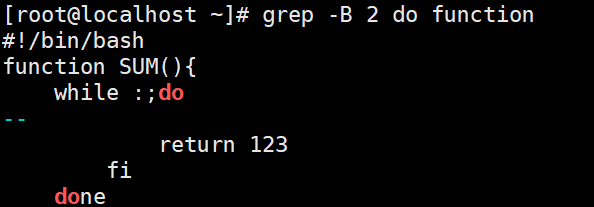
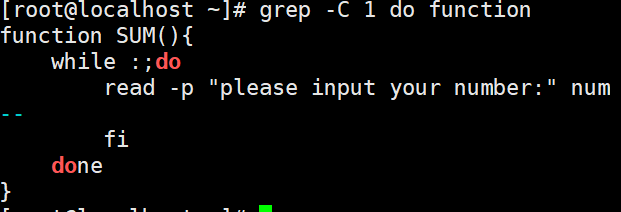
-C过滤字符所在行以及其上下几行
-q 安静模式
awk基本使用(行列都可以处理)
awk 选项(-F指定分隔符) 'BEGIN {操作} 匹配模式{动作1} 匹配模式{动作2}…… END {操作}' 文件名(匹配模式和动作用大括号区分,多个匹配模式中间用空格隔开)
printf和print
printf(需要输入”\n“自动换行符)

print(不需要输入换行符可以自动换行)

awk可以提取空格和制表符为分隔符的内容
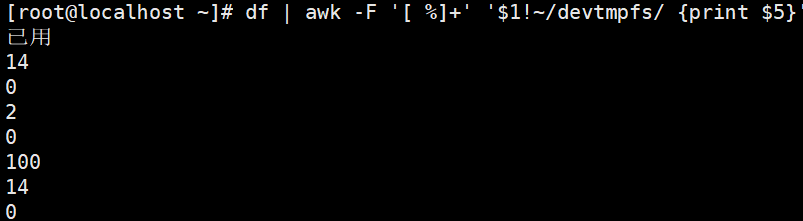
查看磁盘使用百分率,并将%去掉(以%为分隔符取第一列)
![]()
![]()
awk的选项-F 指定分隔符
若果想要打印2列用“,(默认以空格作为分隔符)”或者双引号指定分隔符


如果想要在分隔符中间再添加其他分隔符,双引号和单引号交替使用,可以再次调用变量为分隔符

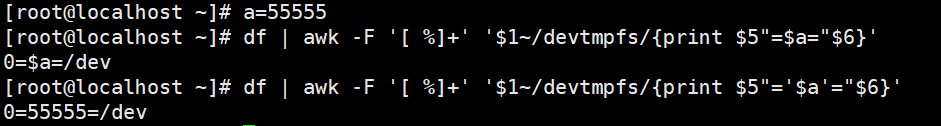
awk的条件
awk运行过程详解

一行一行处理,一个字段一个字段处理并输出:如果有BRGIN先执行BRGIN,之后讲第一行所有数据赋给$0,然后第一行第一列赋给$1第二列赋给$2······直到第一列全部赋值完成后,,如果需要输出,先把第一行满足条件的列输出。在将整个第二列赋值给$0,然后第二列的第一行赋值$1······最后执行END结束
如果有匹配模式,进行匹配,匹配成功执行操作,不成功,读取下一行
awk 保留字
BRGIN :在awk程序一开始时,尚未读取的任何数据之前执行,只在程序开始时执行一次(用于手工指定分隔符)

END :在awk程序处理完所有数据,即将结束执行。END后的动作只在程序结束时执行一次

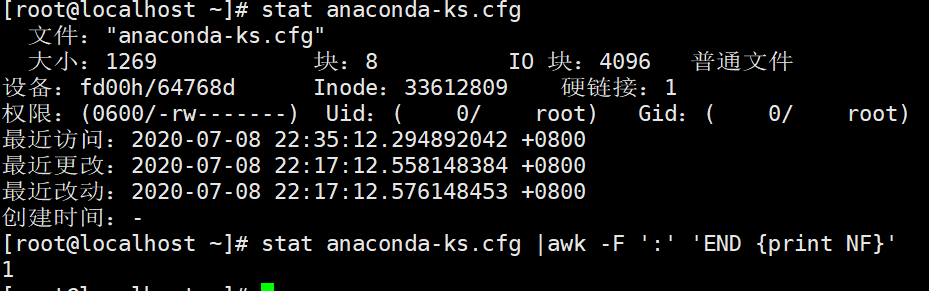
如果每一行列相同,可以交给‘END {print NF}’去处理,可以通过最后一行的列数统计处列数,但是如果不相同,则不能在END中统计
awk关系运算符
运算符
统计平均成绩大于等于86分的学生的名字(首先排除第一行,如果,第六行大于86,则输出第二行)

![]()
![]()


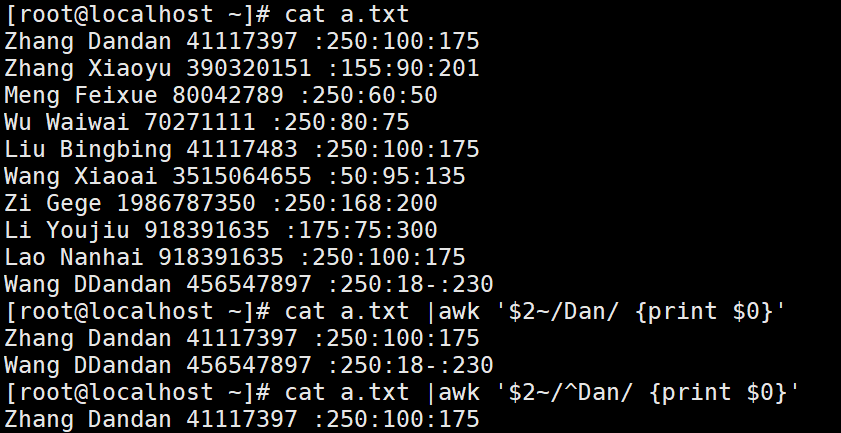
判断第二列中名字包含Sc的学生的平均成绩(第六段)指定具体的某一列是因为防止一行中多个列都出现“Sc”字段
![]()
![]()

正则表达式
/正则/
![]()
![]()
awk在匹配模式和指定分的隔符都可以使用正则表达式
awk内置变量
$0 代表awk所读入的整行数据(相当于不写)
$n 代表当前读入行第n列字段(第n列)
补充:cut默认只能以空格作为分隔符,而awk默认可以以制表符和空格作为分隔符
NR 显示行号和NF当前拥有字段(列)数
NR和NF都是写入到print中

由上图可知,虽然都正确输出,但是不够清晰,中间如果要加入制表符和相关解释说明的中文,要放入到双引号中

NF详解

NR详解

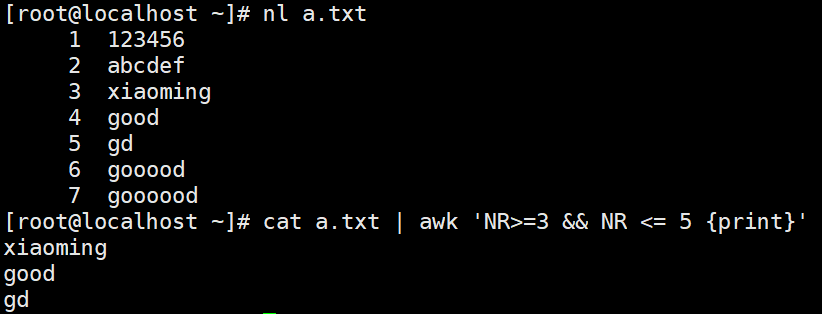

FNR awk同时处理两个文件可以用到
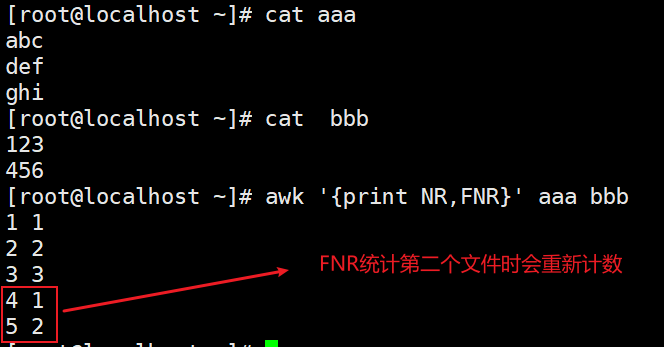
由此可知,当NR>FNR时就可以判断,已经开始处理第二个文件

RS和FS
FS 指定读取记录分隔符,默认是空格或者制表符(以废,同选项中的“F”)识别时起作用
ORS指定输出的记录分隔符,(即一个模块识别操作的分隔符,默认为换行符),输出时体现

如果不加BENGIN,会先把第一行读完,然后再指定分隔符已经晚了,第一行会被直接输出


看似cut更加简单,但是如果指定第三行uid必须为1000的用户,cut无法完成此条件截取,awk是这样截取的

RS指定读取记录分隔符,默认是换行符,识别时起作用
ENVIRON调用系统中的变量,不需要用$调用
ENVIRON["PATH"]

FILENAME 当前处理的文件名

参数个数和参数组
ARGC命令参数的个数相当于shell中的 $#
ARGV命令参数数组,相当于$@ $*
getline获取下一行(类似于sed中的N;)
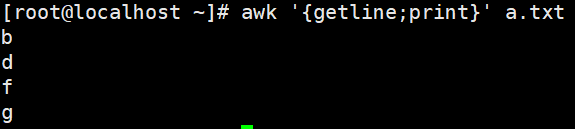
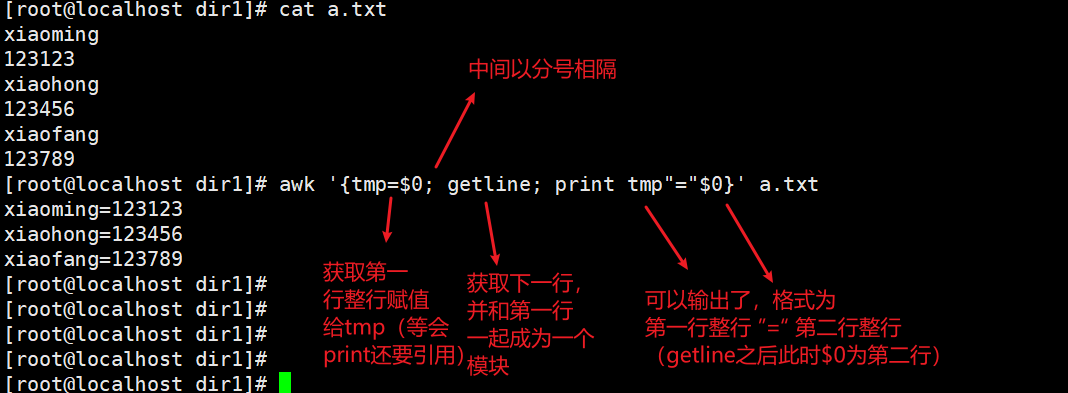
获取行并模块化,getline之后$0变成了第二行,所以第一行的值必须用tmp保存

sed实现方式

以N加分号配合换行符替代方式实现。为了方便记忆,在替换中所有-n和p一律省略
length("字符串") 求字符长度

输出变量配合echo使用
求行字符长度为2的行,不要慌,放在条件中而已

split() 切割字符串化为数组形式处理

格式:split("字符串",数组名称,"分隔符") 按指定分隔符将字符串且各位数组


大小写取代
toupper() 小写换大写
tolower() 大写换小写

字符串截取

字符串替换(sub和gsub)
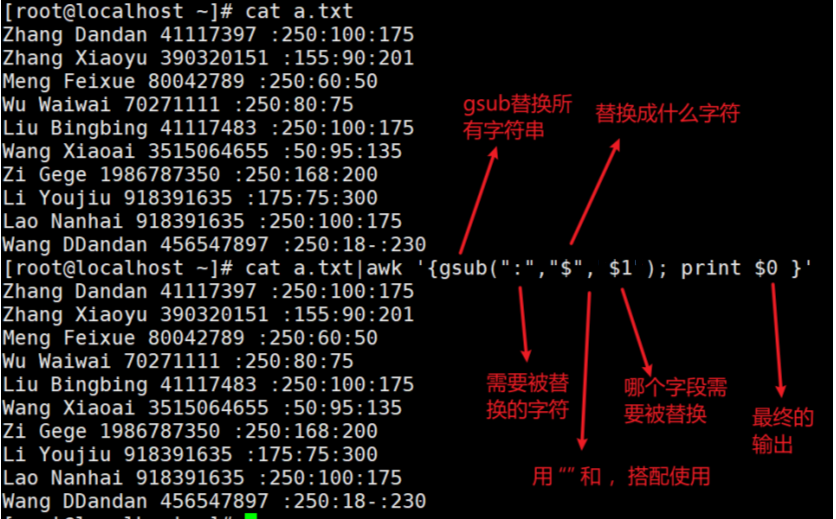
sub(gsub)(“需要被替换的字符”,“替换成的字符”,“要被替换的字段”)sub代表只替换一个字符,gsub代表本字段的所有字符都替换,指定输入哪个字段来表示,$0为整行全部替换
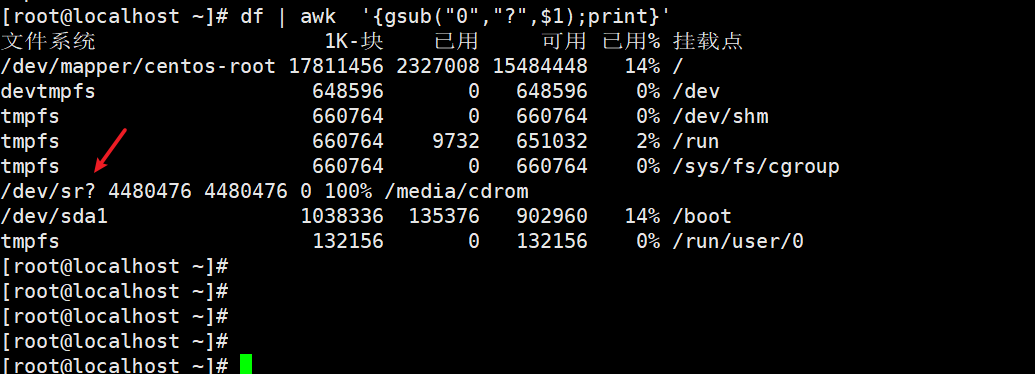
吧字符”0“替换成字符”?“,只替换第一行,然后输出整行
时间函数
strftime() 格式化输出,类似于date

输出当天访问httpd IP的个数,并统计排序

systime() 获取时间戳

system() 调用linux系统命令

支持判断循环 if ; else if ; else ; while 支持数组
awk计算
字符串格式化输出(输出格式和计算过程用逗号隔开)
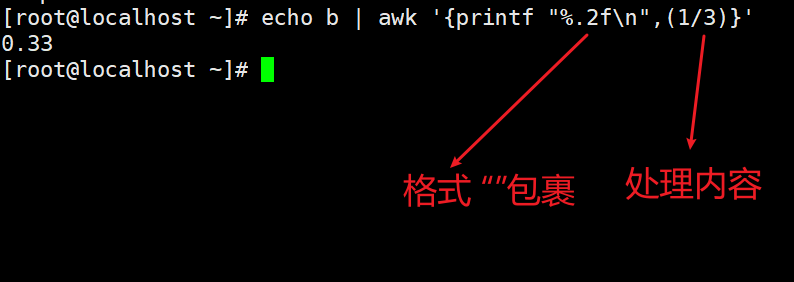
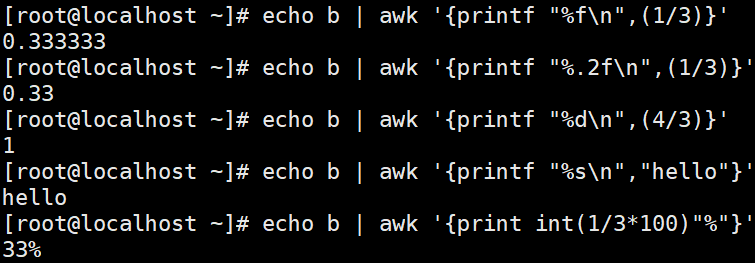
非格式化输出极简版

awk例题
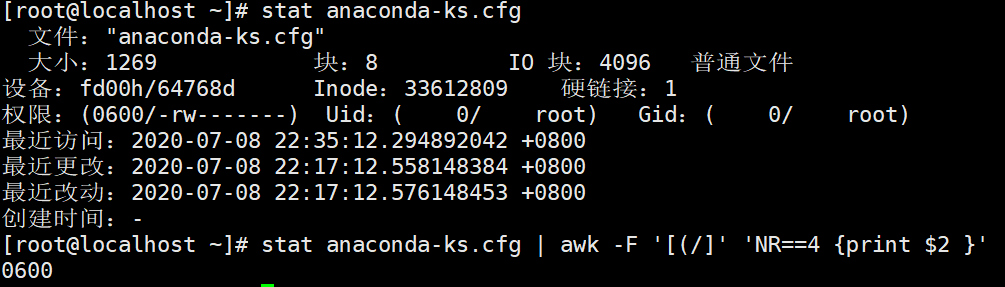
例题1,截取stat中的权限
方法1(管道符分开截取)
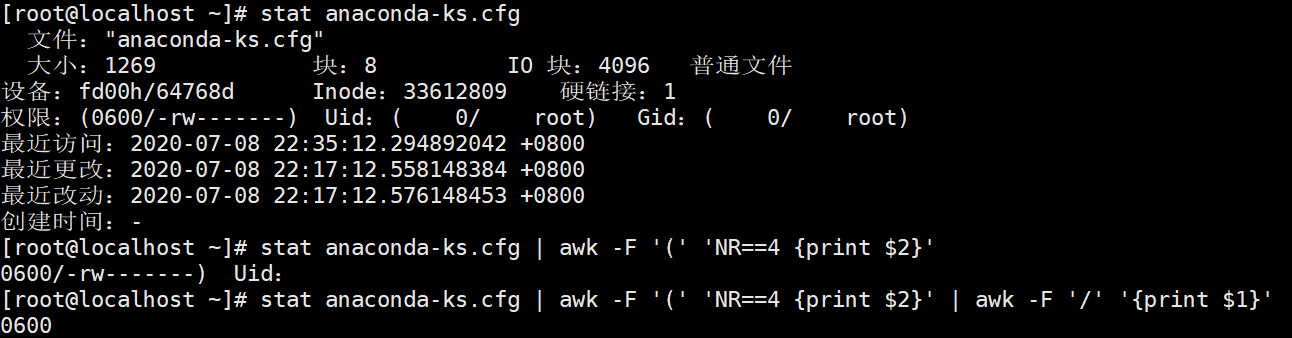
方法2(正则匹配一步到位)
例题2,截取网址
各种秀就对了

sed命令(选项都是英文,主要处理行)
sed(Stream Editor)流文件处理工具主要是用来将数据进行选取、替换、删除、新增,作用,替代vim的作用,不需要进行交互
格式:sed [选项] '地址 操作;地址 操作;······' 文件名(单引号中分号将多个部分隔开,地址和操作空格隔开)
sed工作流程
sed命令将一行读取到模式空间(由上到下一行一行打印)
进行匹配,如果匹配成功,就执行操作,如果不匹配就丢弃,读取下一行
直到读取到文件最后一行
选项:
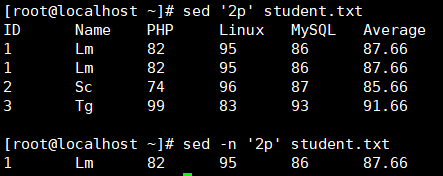
-n 只打印处理的行,多结合操作p一起(对比图:)
-i sed修改结果直接修改文件内容,而不是由屏幕输出
删除2-4行,并写入数据

-r 支持扩展正则
地址操作
;可以隔离多个操作
‘动作1; 动作2;动作3......‘
将第三行和第四行删除并写入
可以直接在地址中加入分号进行多行操作

查
p 打印输出指定行
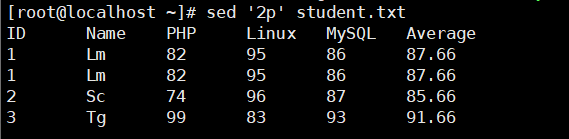
2p打印第二行 2,4p打印2到4行 2,$打印第二行到文件结尾(一般加-n)
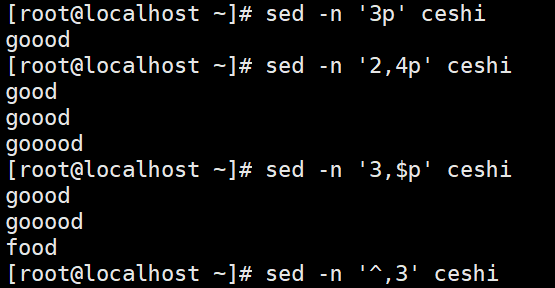
正则使用方法

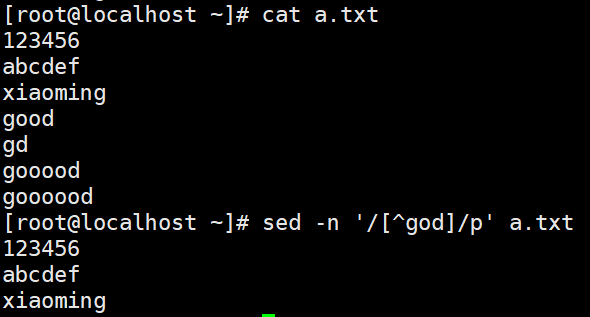
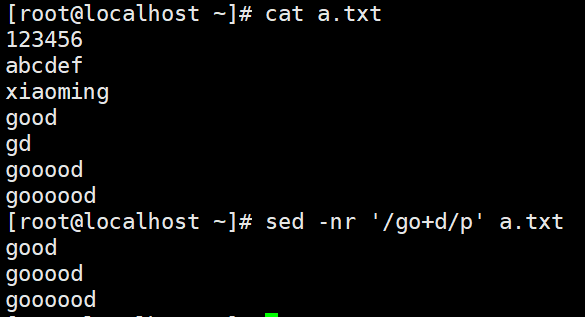
增
a 行追加,在当前行后添加一行或多行。添加多行时,除最后一行外,每行末尾要用 “\”代表数据未完结
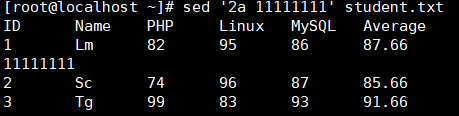
使用 “\”追加,怕自动换行导致单词失效 输出"\"回车自动换行输入
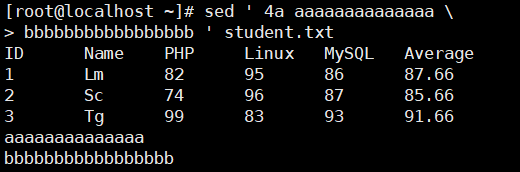
i 行插入,当前行前插入一行或多行。"\"作用同上
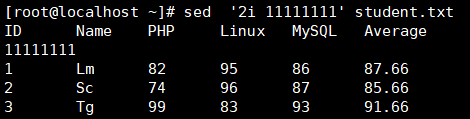
删
d 行删除,删除指定行

改
c \行替换,"\" 作用同上


格式:sed ' s/old/new/g ' student.txt
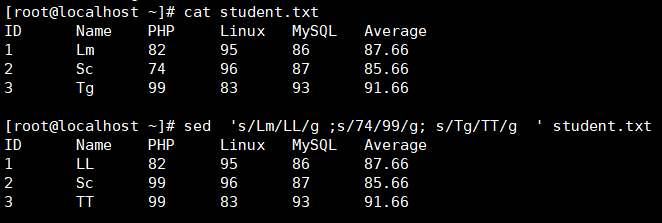
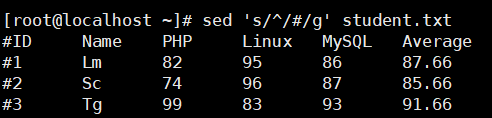
批量加注释:sed 's/^/#/g' studnet.txt
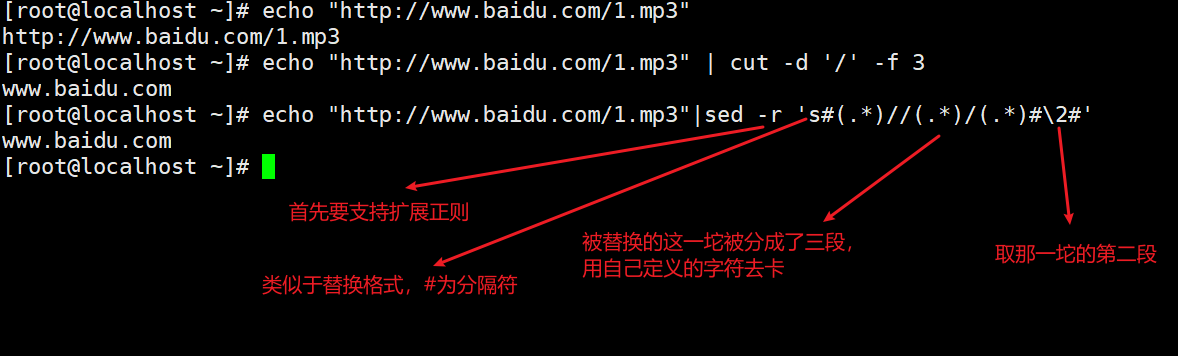
三个肉卡2符号放在第二坨(卡符号卡的是贪婪匹配,符号要卡准)

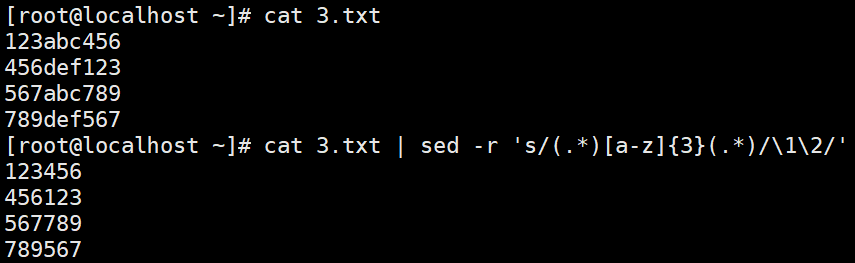


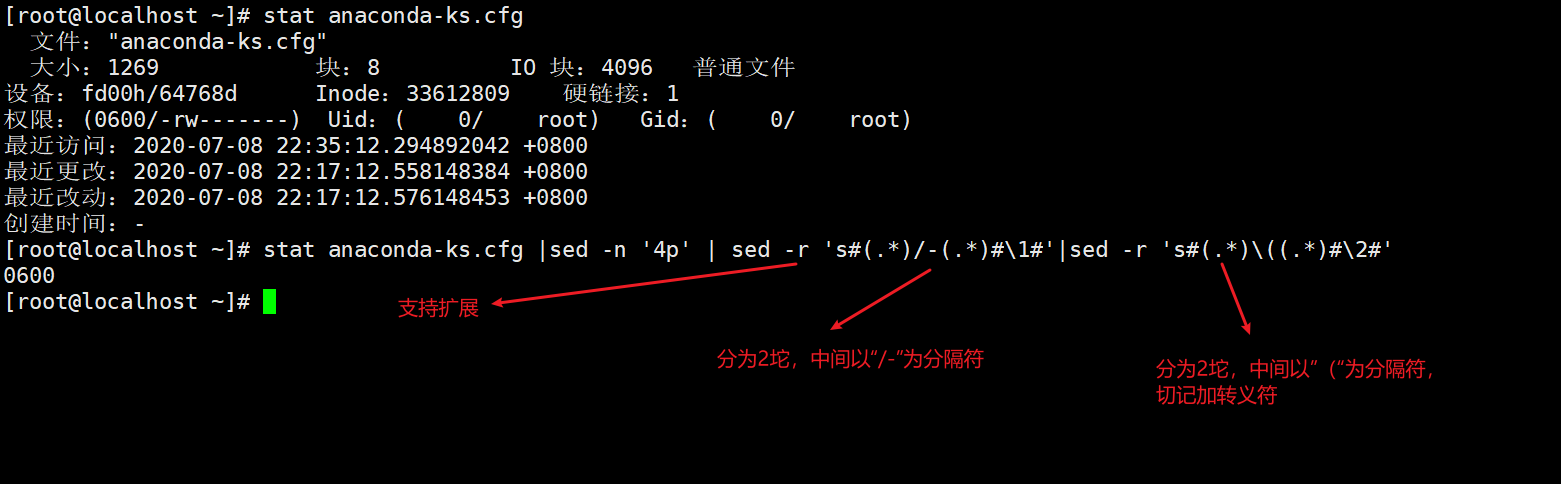
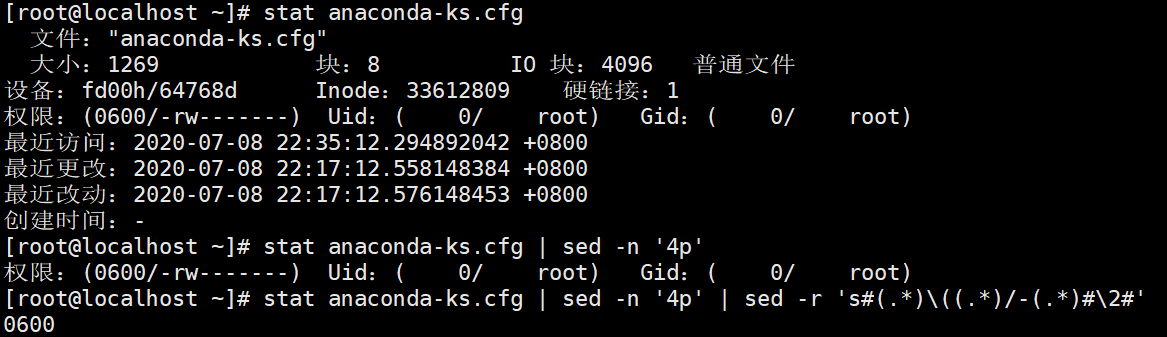




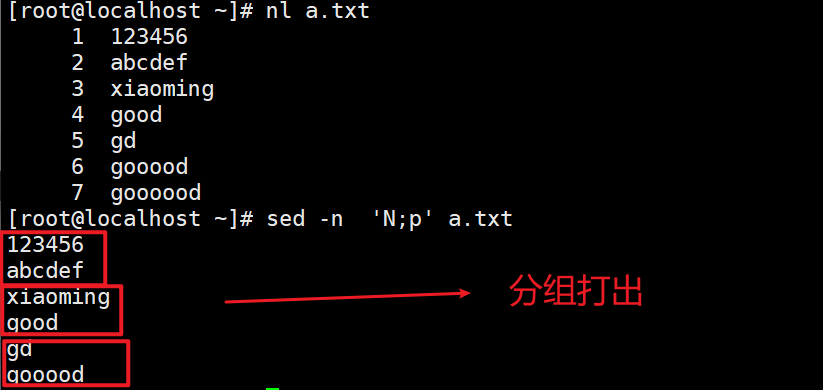
分组打印
-n 读入下一行,上一行位于模式空间中的内容会被顶替掉(可以指定奇数行和偶数行)
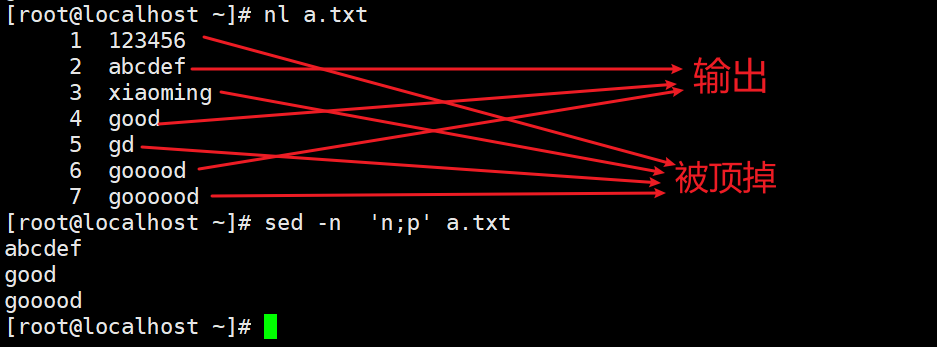
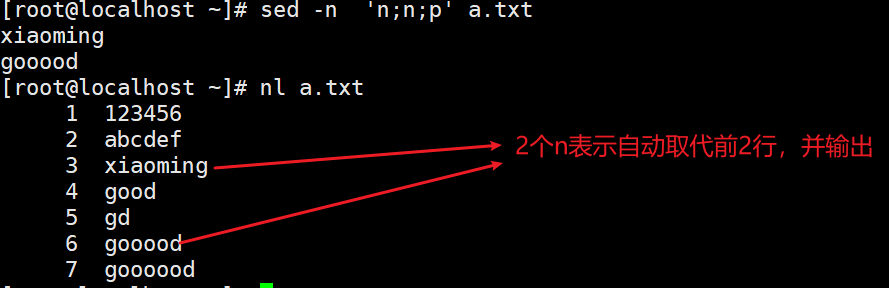
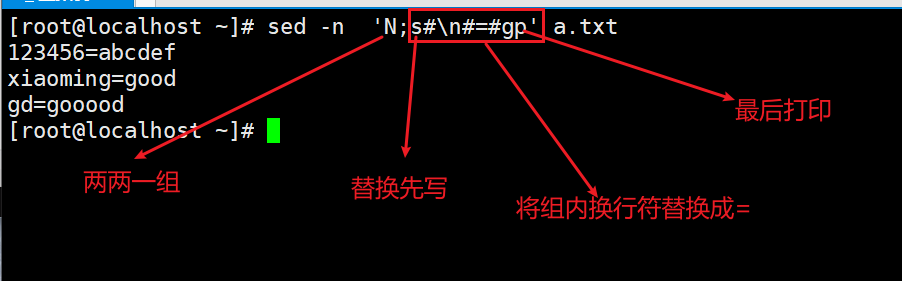
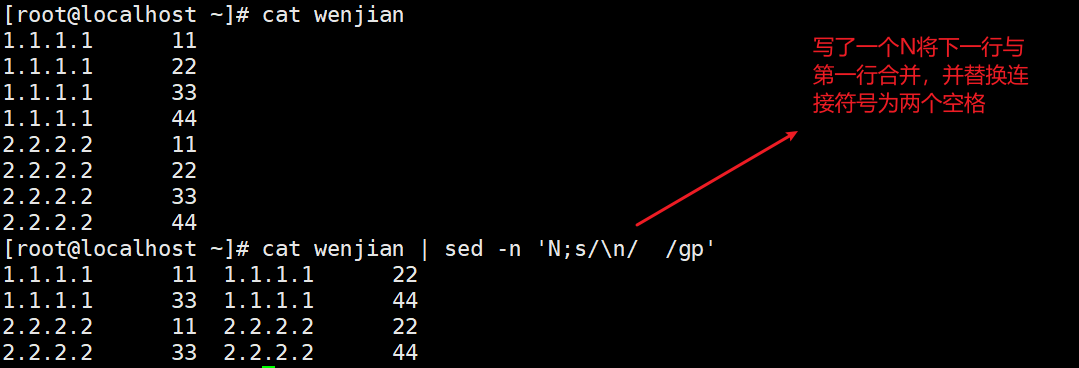
N与上一行同时保持在模式空间(两行两行读取,和paste相似,每多写一个n就会多一行并入)配合替换使用



w 保存
所有文本处理大总结
wc -L head tail grep -w
${字符串 操作}
操作部分(: : #(#) 字符*字符 %(%)字符 *字符 /(/)字符/字符)
cut -d ‘ ’ -f 2,4,6,8······
tr 常用tr -s 去除多余空格 tr -d ' ' 去除空格 tr [a-z] [A-Z]替换
sort -n 排序 -t -k 2(2,2;3.1) -r反向排序
sort 配合uniq -c统计重复行
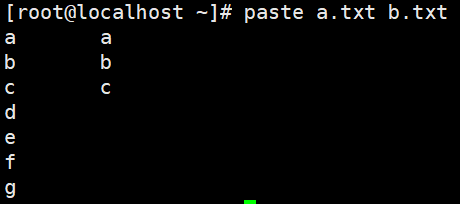
paste 用于合并以及分行
-s 一行输出
-d 指定连接符,两行合并可以-d "符号/n"
超过两行合并使用-d " " - - - <文件名
xargs -n 数字 以字段合行
join 若第一列相同则合并,其他列按照第一列的规则(行数)输出在后,否则不输出
sed -nr 'N;N;(分行必备) s/\n//g;(N必配) s/(.*)(.*)(.*)(.*)/\1\3\5/ p'
发布者:LJH,转发请注明出处:https://www.ljh.cool/35435.html