
如何解决CKA题目问题:
推荐使用--help以及参考官网来解决问题:
官网地址:https://kubernetes.io/zh-cn/docs/reference/
参考内容范围:

1、权限控制RBAC
设置配置环境:
[candidate@node-1] $ kubectl config use-context k8s
Context
为部署流水线创建一个新的 ClusterRole 并将其绑定到范围为特定的 namespace 的特定 ServiceAccount。
Task
创建一个名为 deployment-clusterrole 且仅允许创建以下资源类型的新 ClusterRole:
Deployment
StatefulSet
DaemonSet
在现有的 namespace app-team1 中创建一个名为 cicd-token 的新 ServiceAccount。
限于 namespace app-team1 中,将新的 ClusterRole deployment-clusterrole 绑定到新的 ServiceAccount cicd-token。考试时务必执行,切换集群。练习环境中不需要执行(之后省略)。
# kubectl config use-context k8s
kubectl create clusterrole deployment-clusterrole--verb=create--resource=deployments,statefulsets,daemonsets
kubectl -n app-team1create serviceaccount cicd-token
检查kubectl -n app-team1 describe rolebinding cicd-token-rolebinding
2、查看pod的CPU
设置配置环境:
[candidate@node-1] $ kubectl config use-context k8s
Task
通过 pod label name=cpu-loader,找到运行时占用大量 CPU 的 pod,
并将占用 CPU 最高的 pod 名称写入文件 /opt/KUTR000401/KUTR00401.txt(已存在)。kubectl top pod -h
#-l name通过标签name查看pod 名称 -A 是所有 namespace
kubectl top pod -l name=cpu-loader --sort-by=cpu -A
# 将 cpu 占用最多的 pod 的 name 写入/opt/test1.txt 文件
echo "查出来的 Pod Name" > /opt/KUTR000401/KUTR00401.txt
检查cat /opt/KUTR000401/KUTR00401.txt
3、配置网络策略 NetworkPolicy
设置配置环境:
[candidate@node-1] $ kubectl config use-context hk8s
Task
在现有的 namespace my-app 中创建一个名为 allow-port-from-namespace 的新 NetworkPolicy。
确保新的 NetworkPolicy 允许 namespace echo 中的 Pods 连接到 namespace my-app 中的 Pods 的 9000 端口。
进一步确保新的 NetworkPolicy:
不允许对没有在监听 端口 9000 的 Pods 的访问
不允许非来自 namespace echo 中的 Pods 的访问文档搜索 Network Policies,找到下面这一段
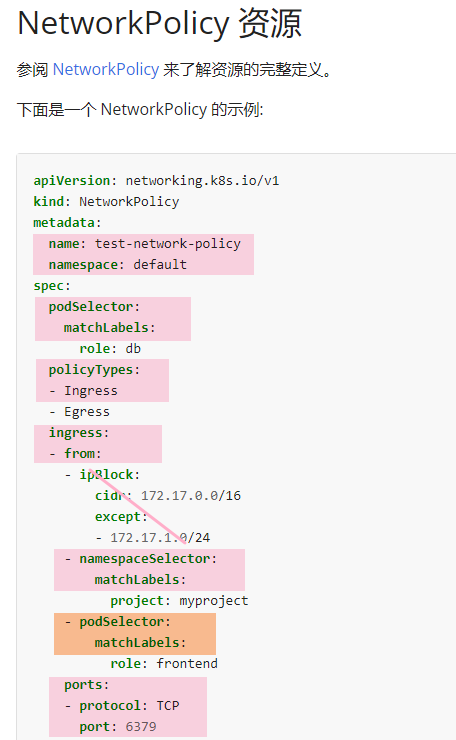
查看所有 ns 的标签 labe
kubectl get ns --show-labels
如果访问者的 namespace 没有标签 label,则需要手动打一个。如果有一个独特的标签 label,则也可以直接使用。
kubectl label ns echo project=echo
vim networkpolicy.yaml
#注意 :set paste,防止 yaml 文件空格错序。
apiVersion: networking.k8s.io/v1
kind: NetworkPolicy
metadata:
name: allow-port-from-namespace
namespace: my-app #被访问者的命名空间
spec:
podSelector: #这两行必须要写,或者也可以写成一行为 podSelector: {}
matchLabels: {} # 注意 matchLabels:与{}之间有一个空格
policyTypes:
- Ingress #策略影响入栈流量
ingress:
- from: #允许流量的来源
- namespaceSelector:
matchLabels:
project: echo #访问者的命名空间的标签 label
#- podSelector: {} #注意,这个不写。如果 ingress 里也写了- podSelector: {},则会导致 my-app 中的 pod 可以访问 my-app 中 pod 的 9000 了,这样不满足题目要求不允许非来自 namespace echo 中的 Pods 的访问。
ports:
- protocol: TCP
port: 9000 #被访问者公开的端口kubectl apply -f networkpolicy.yaml
kubectl describe networkpolicy -n my-app
4、暴露服务 service
设置配置环境:
[candidate@node-1] $ kubectl config use-context k8s
Task
请重新配置现有的 deployment front-end 以及添加名为 http 的端口规范来公开现有容器 nginx 的端口 80/tcp。
创建一个名为 front-end-svc 的新 service,以公开容器端口 http。
配置此 service,以通过各个 Pod 所在的节点上的 NodePort 来公开他们。文档搜索containerPort
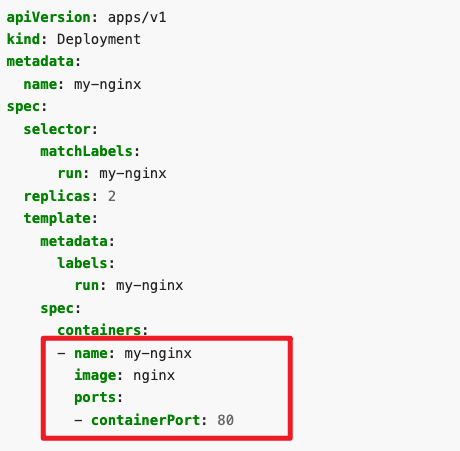
检查 deployment 信息,并记录 SELECTOR 的 Lable 标签,这里是 app=front-end
kubectl get deployment front-end -o wide
参考官方文档,按照需要 edit deployment,添加端口信息
kubectl edit deployment front-end
spec:
containers:
- image: vicuu/nginx:hello
imagePullPolicy: IfNotPresent
name: nginx #找到此位置。下文会简单说明一下 yaml 文件的格式,不懂 yaml 格式的,往下看。
ports: #添加这 4 行
- name: http
containerPort: 80
protocol: TCP暴露对应端口
kubectl expose deployment front-end --type=NodePort --port=80 --target-port=80 --name=front-end-svc
暴露服务后,检查一下 service 的 selector 标签是否正确,这个要与 deployment 的 selector 标签一致的。
kubectl get svc front-end-svc -o wide
kubectl get deployment front-end -o wide

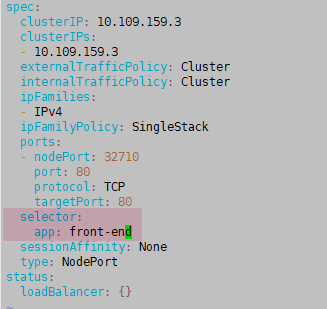
如果你 kubectl expose 暴露服务后,发现 service 的 selector 标签是空的,或者不是 deployment 的,如下图这样:

则需要编辑此service,手动添加标签。(模拟环境里暴露服务后,selector标签是正确的。但是考试时,有时service的selector标签是none)
kubectl edit svc front-end-svc
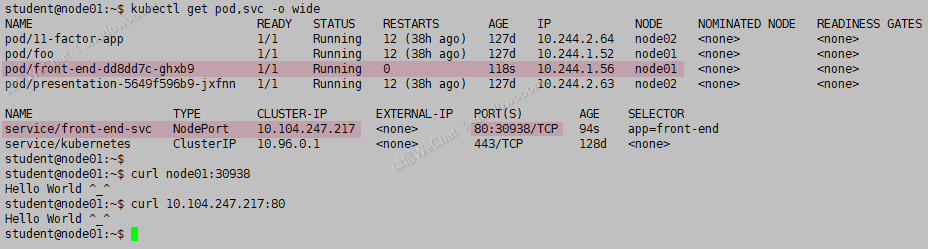
最后curl检查,curl 所在的node的ip或主机名:端口
kubectl get pod,svc -o wide
curl svc的ip地址:80
5、创建 Ingress
设置配置环境:
[candidate@node-1] $ kubectl config use-context k8s
Task
如下创建一个新的 nginx Ingress 资源:
名称: ping
Namespace: ing-internal
使用服务端口 5678 在路径 /hello 上公开服务 hello
可以使用以下命令检查服务 hello 的可用性,该命令应返回 hello:
curl -kL <INTERNAL_IP>/hello网页搜索ingress,参考以下配置:

vim ingress.yaml
apiVersion: networking.k8s.io/v1
kind: Ingress
metadata:
name: ping
namespace: ing-internal
annotations:
kubernetes.io/ingress.class: "nginx" #在 v1.23 的考试中,有人反馈不加这句,ingress 不出 IP;但是也有人反馈不加这句可以出 IP,反而加了这句
ingress 不出 IP 了。但反馈加了出 IP 的人多。所以我建议考试时,先加上这句,然后 apply,等 5 分钟,如果一直没有出 IP,则删除后,再不加这句,apply 一下,
如果 5 分钟还是没出。只有一种可能,你别的地方写错了。如果此时你又找不出错误,我建议你继续往下做题,不要纠结这两三分的得失。
nginx.ingress.kubernetes.io/rewrite-target: / #因为考试环境有多套,不清楚具体抽中的是哪套。在 1.24 的考试里,先写上这行,如果 apply 时报错需
要指定域名,则注释这行再 apply,就成功了。
spec:
# ingressClassName: nginx #在 1.24 的考试里,这行不要写。
rules:
- http:
paths:
- path: /hello
pathType: Prefix
backend:
service:
name: hello
port:
number: 5678kubectl apply -f ingress.yaml
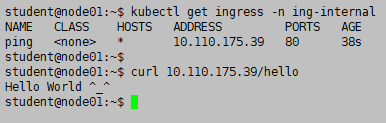
最后 curl 检查
kubectl get ingress -n ing-internal
curl ingress 的 ip 地址/hello
6、扩容 deployment 副本数量
设置配置环境:
[candidate@node-1] $ kubectl config use-context k8s
Task
将 deployment presentation 扩展至 4 个 pods没必要参考网址,使用-h 帮助更方便。
kubectl scale deployment -h
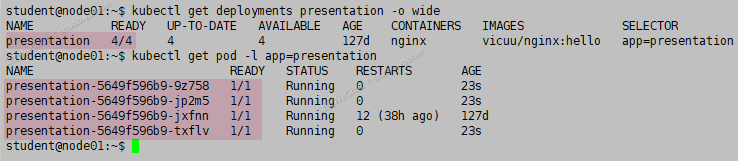
先检查一下现有的 pod 数量(可不检查)
kubectl get deployments presentation -o wide
kubectl get pod -l app=presentation

扩展成 4 个
kubectl scale deployment presentation --replicas=4
检查
kubectl get deployments presentation -o wide
kubectl get pod -l app=presentation
7、调度 pod 到指定节点
设置配置环境:
[candidate@node-1] $ kubectl config use-context k8s
Task
按如下要求调度一个 pod:
名称:nginx-kusc00401
Image:nginx
Node selector:disk=ssd考点:nodeSelect 属性的使用
网页搜索:nodeSelecter

#确保node有这个labels,考试时,检查一下就行,应该已经提前设置好了labels
kubectl get nodes --show-labels|grep 'disk=ssd'

如果没有设置,则使用kubectl label nodes node01 disk=ssd命令来手动自己设置。
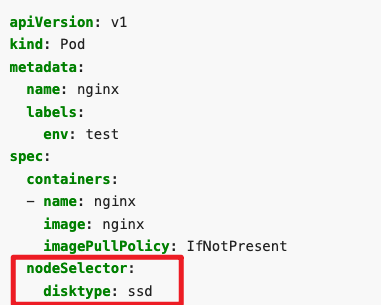
vimpod-disk-ssd.yaml
apiVersion: v1
kind: Pod
metadata:
name: nginx-kusc00401
spec:
containers:
- name: nginx
image: nginx
imagePullPolicy: IfNotPresent #这句的意思是,如果此 image 已经有了,则不重新下载。考试时写不写这个都是可以的。
nodeSelector:
disk: ssdkubectl apply -f pod-disk-ssd.yaml
检查
kubectl get pod nginx-kusc00401 -o wide

8、查看可用节点数量
设置配置环境:
[candidate@node-1] $ kubectl config use-context k8s
Task
检查有多少 nodes 已准备就绪(不包括被打上 Taint:NoSchedule 的节点),
并将数量写入 /opt/KUSC00402/kusc00402.txt考点:检查节点角色标签,状态属性,污点属性的使用
grep 的-i 是忽略大小写,grep -v 是排除在外,grep -c 是统计查出来的条数。
kubectl describe nodes | grep -i Taints | grep -vc NoSchedule
echo "查出来的数字" > /opt/KUSC00402/kusc00402.txt

检查
cat /opt/KUSC00402/kusc00402.txt
9、创建多容器的 pod
设置配置环境:
[candidate@node-1] $ kubectl config use-context k8s
Task
按如下要求调度一个 Pod:
名称:kucc8
app containers: 2
container 名称/images:
⚫ nginx
⚫ consul文档搜索pod
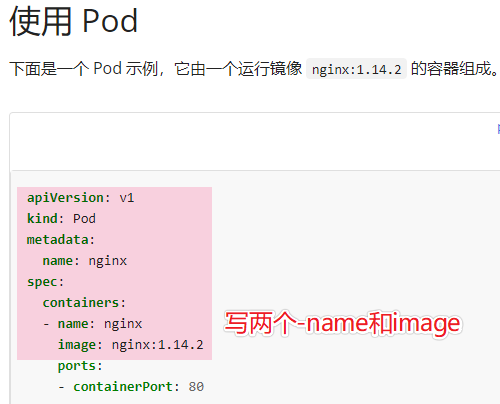
vim pod-kucc.yaml
apiVersion: v1
kind: Pod
metadata:
name: kucc8
spec:
containers:
- name: nginx
image: nginx
imagePullPolicy: IfNotPresent #这句的意思是,如果此 image 已经有了,则不重新下载。考试时写不写这个都是可以的。测试时推荐写,这样快些。
- name: consul
image: consul
imagePullPolicy: IfNotPresentkubectl apply -f pod-kucc.yaml
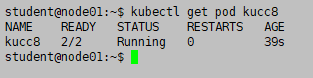
kubectl get pod kucc8
10、创建PV
设置配置环境:
[candidate@node-1] $ kubectl config use-context hk8s
Task
创建名为 app-config 的 persistent volume,容量为 1Gi,访问模式为 ReadWriteMany。
volume 类型为 hostPath,位于 /srv/app-config考点:hostPath 类型的 pv
文档搜索pv,pod
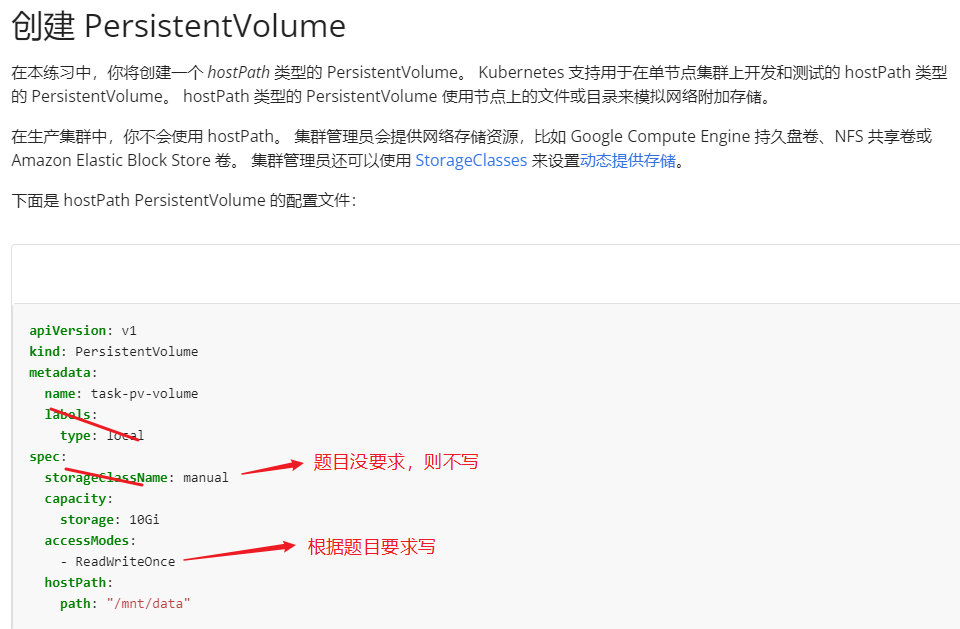
vim pv.yaml
apiVersion: v1
kind: PersistentVolume
metadata:
name: app-config
#labels: #不需要写
#type: local
spec:
capacity:
storage: 1Gi
accessModes:
- ReadWriteMany # 注意,考试时的访问模式可能有 ReadWriteMany 和 ReadOnlyMany 和 ReadWriteOnce,根据题目要求写。
hostPath:
path: "/srv/app-config"kubectl apply -f pv.yaml
kubectl get pv

11、创建 PVC
设置配置环境:
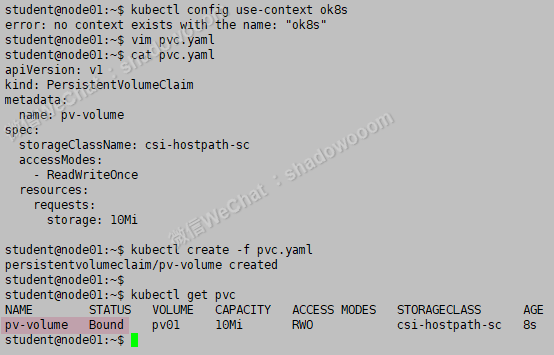
[candidate@node-1] $ kubectl config use-context ok8s
Task
创建一个新的 PersistentVolumeClaim:
名称: pv-volume
Class: csi-hostpath-sc
容量: 10Mi
创建一个新的 Pod,来将 PersistentVolumeClaim 作为 volume 进行挂载:
名称:web-server
Image:nginx:1.16
挂载路径:/usr/share/nginx/html
配置新的 Pod,以对 volume 具有 ReadWriteOnce 权限。
最后,使用 kubectl edit 或 kubectl patch 将 PersistentVolumeClaim 的容量扩展为 70Mi,并记录此更改。文档还是搜索pv,pod
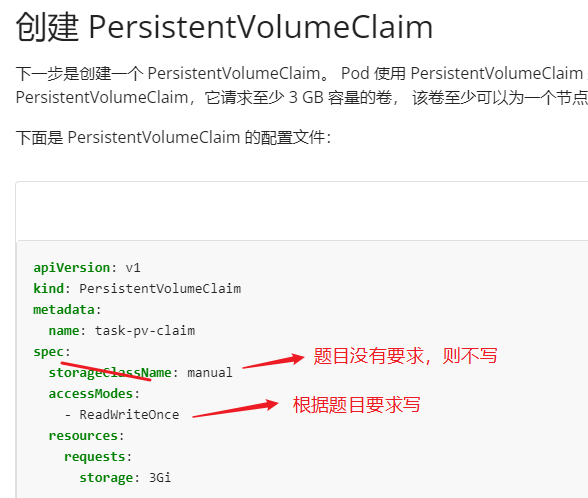
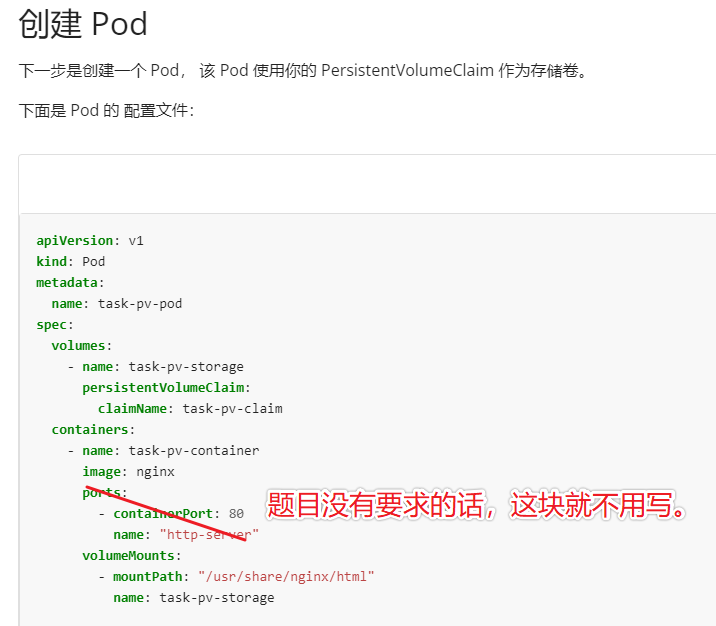
vim pvc.yaml
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: pv-volume #pvc 名字
spec:
storageClassName: csi-hostpath-sc
accessModes:
- ReadWriteOnce # 注意,考试时的访问模式可能有 ReadWriteMany 和 ReadOnlyMany 和 ReadWriteOnce,根据题目要求写。
resources:
requests:
storage: 10Mikubectl apply -f pvc.yaml
检查
kubectl get pvc
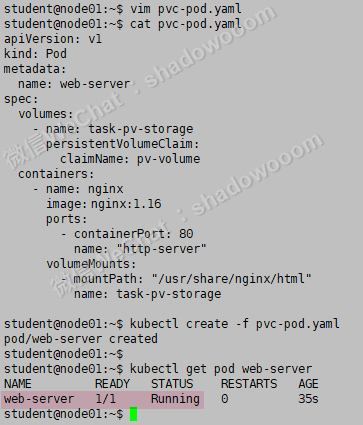
vim pvc-pod.yaml
apiVersion: v1
kind: Pod
metadata:
name: web-server
spec:
volumes:
- name: task-pv-storage #绿色的两个 name 要一样。
persistentVolumeClaim:
claimName: pv-volume #这个要使用上面创建的 pvc 名字
containers:
- name: nginx
image: nginx:1.16
volumeMounts:
- mountPath: "/usr/share/nginx/html"
name: task-pv-storage #绿色的两个 name 要一样。kubectl apply -f pvc-pod.yaml
检查
kubectl get pod web-server

更改大小,并记录过程。
kubectl edit pvc pv-volume --record
12、查看 pod 日志
设置配置环境:
[candidate@node-1] $ kubectl config use-context k8s
Task
监控 pod foo 的日志并:
提取与错误 RLIMIT_NOFILE 相对应的日志行
将这些日志行写入 /opt/KUTR00101/foo考点:kubectl logs 命令
kubectl logs foo | grep "RLIMIT_NOFILE" > /opt/KUTR00101/foo
检查
cat /opt/KUTR00101/foo

13、使用 sidecar 代理容器日志
设置配置环境:
[candidate@node-1] $ kubectl config use-context k8s
Context
将一个现有的 Pod 集成到 Kubernetes 的内置日志记录体系结构中(例如 kubectl logs)。
添加 streaming sidecar 容器是实现此要求的一种好方法。
Task
使用 busybox Image 来将名为 sidecar 的 sidecar 容器添加到现有的 Pod 11-factor-app 中。
新的 sidecar 容器必须运行以下命令:
/bin/sh -c tail -n+1 -f /var/log/11-factor-app.log
使用挂载在/var/log 的 Volume,使日志文件 11-factor-app.log 可用于 sidecar 容器。
除了添加所需要的 volume mount 以外,请勿更改现有容器的规格。考点:pod 两个容器共享存储卷
搜索Logging Architecture
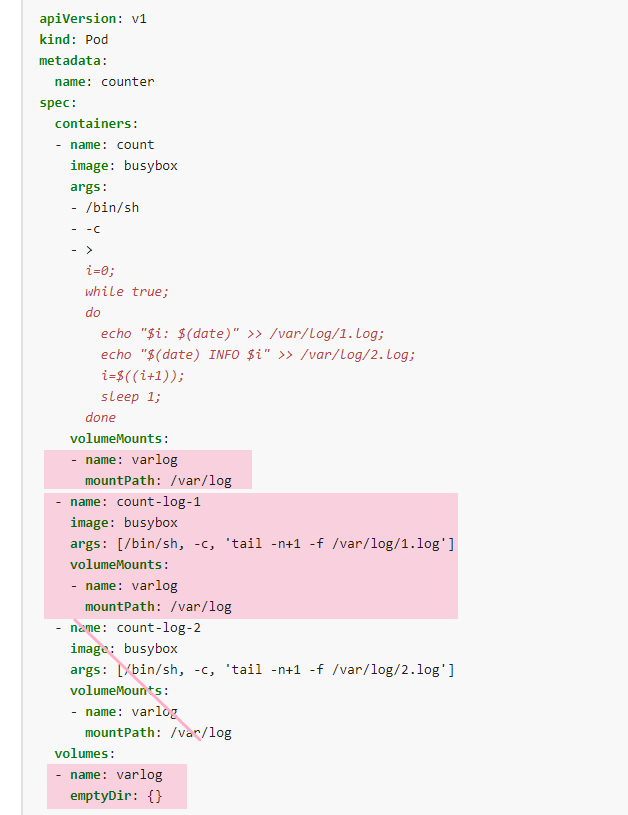
导出这个 pod 的 yaml 文件
kubectl get pod 11-factor-app -o yaml > varlog.yaml
备份 yaml 文件,防止改错了,回退。
cp varlog.yaml varlog-bak.yaml
修改 varlog.yaml 文件
vim varlog.yaml

删除原先的 pod
kubectl delete pod 11-factor-app
kubectl get pod 11-factor-app
新建这个 pod
kubectl apply -f varlog.yaml
检查
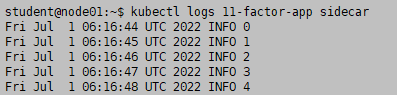
kubectl logs 11-factor-app sidecar
kubectl exec 11-factor-app -c sidecar -- tail -f /var/log/11-factor-app.log
kubectl exec 11-factor-app -c count -- tail -f /var/log/11-factor-app.log
14、升级集群
设置配置环境:
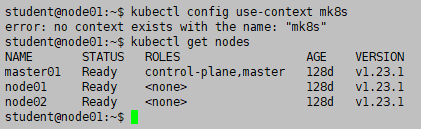
[candidate@node-1] $ kubectl config use-context mk8s
Task
现有的 Kubernetes 集群正在运行版本 1.24.2。仅将 master 节点上的所有 Kubernetes 控制平面和节点组件升级到版本 1.24.3。
确保在升级之前 drain master 节点,并在升级后 uncordon master 节点。
可以使用以下命令,通过 ssh 连接到 master 节点:
ssh master01
可以使用以下命令,在该 master 节点上获取更高权限:
sudo -i
另外,在主节点上升级 kubelet 和 kubectl。
请不要升级工作节点,etcd,container 管理器,CNI 插件, DNS 服务或任何其他插件。搜索 kubeadm upgrade



kubectl get nodes
# cordon 停止调度,将node调为SchedulingDisabled。新pod不会被调度到该node,但在该node的旧pod不受影响。
# drain驱逐节点。首先,驱逐该node上的pod,并在其他节点重新创建。接着,将节点调为SchedulingDisabled。
kubectl cordon master01
kubectl drain master01 --ignore-daemonsets
#ssh到master节点,并切换到root下
ssh master01
sudo -i
apt-get update
apt-cache show kubeadm|grep 1.24.3
apt-get install kubeadm=1.24.3-00

检查kubeadm升级后的版本
kubeadm version
#验证升级计划
kubeadm upgrade plan
#排除etcd,升级其他的,提示时,输入y。
kubeadm upgrade apply v1.24.3--etcd-upgrade=false
升级kubelet
apt-get install kubelet=1.24.3-00
kubelet --version
升级kubectl
apt-get install kubectl=1.24.3-00
kubectl version

#退出root,退回到candidate@master01
exit
#退出master01,退回到candidate@node01
exit
恢复master01调度
kubectl uncordon master01
检查master01是否为Ready
kubectl get node
15、备份还原etcd
设置配置环境
此项目无需更改配置环境。但是,在执行此项目之前,请确保您已返回初始节点。
[candidate@master01] $ exit #注意,这个之前是在 master01 上,所以要 exit 退到 node01,如果已经是 node01 了,就不要再 exit 了。
Task
首先,为运行在 https://11.0.1.111:2379 上的现有 etcd 实例创建快照并将快照保存到 /var/lib/backup/etcd-snapshot.db
(注意,真实考试中,这里写的是 https://127.0.0.1:2379)
为给定实例创建快照预计能在几秒钟内完成。 如果该操作似乎挂起,则命令可能有问题。用 CTRL + C 来取消操作,然后重试。
然后还原位于/data/backup/etcd-snapshot-previous.db 的现有先前快照。
提供了以下 TLS 证书和密钥,以通过 etcdctl 连接到服务器。
CA 证书: /opt/KUIN00601/ca.crt
客户端证书: /opt/KUIN00601/etcd-client.crt
客户端密钥: /opt/KUIN00601/etcd-client.key考点:etcd 的备份和还原命令
如果不使用 export ETCDCTL_API=3,而使用 ETCDCTL_API=3,则下面每条 etcdctl 命令前都要加 ETCDCTL_API=3。
如果执行时,提示 permission denied,则是权限不够,命令最前面加 sudo 即可。
export ETCDCTL_API=3
etcdctl --endpoints=https://11.0.1.111:2379 --cacert="/opt/KUIN00601/ca.crt" --cert="/opt/KUIN00601/etcd-client.crt" --key="/opt/KUIN00601/etcd-client.key"
snapshot save /var/lib/backup/etcd-snapshot.db
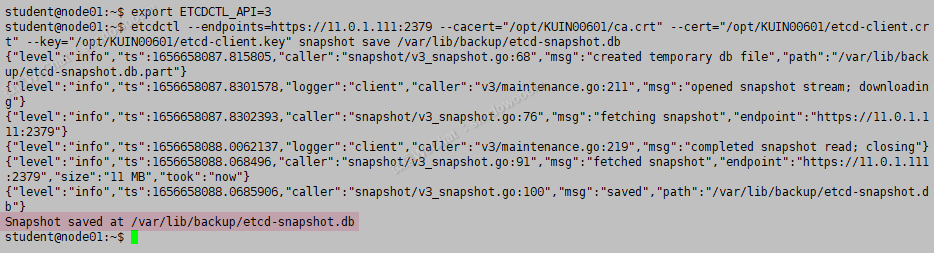
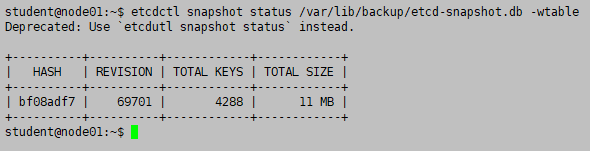
检查:
etcdctl snapshot status /var/lib/backup/etcd-snapshot.db -wtable
还原:
# 考试时,/data/backup/etcd-snapshot-previous.db的权限应该是只有root可读,所以需要使用sudo命令。
#可以ll /data/backup/etcd-snapshot-previous.db检查一下读写权限和属主。

#不加sudo会报错permission denied
sudo ETCDCTL_API=3 etcdctl --endpoints=https://11.0.1.111:2379 --cacert="/opt/KUIN00601/ca.crt" --cert="/opt/KUIN00601/etcd-client.crt" --
key="/opt/KUIN00601/etcd-client.key" snapshot restore /data/backup/etcd-snapshot-previous.db

16、排查集群中故障节点
设置配置环境:
[candidate@node-1] $ kubectl config use-context wk8s
Task
名为 node02 的 Kubernetes worker node 处于 NotReady 状态。
调查发生这种情况的原因,并采取相应的措施将 node 恢复为 Ready 状态,确保所做的任何更改永久生效。
可以使用以下命令,通过 ssh 连接到 node02 节点:
ssh node02
可以使用以下命令,在该节点上获取更高权限:
sudo -i执行初始化这道题的脚本 a.sh,模拟 node02 异常。执行完 a.sh 脚本后,等 2 分钟,node02 才会挂掉。
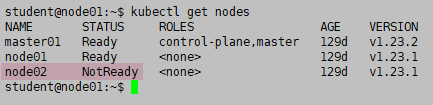
检查一下 node,发现 node02 异常
kubectl get nodes
ssh 到 node02 节点,并切换到 root 下
ssh node02
sudo -i
检查 kubelet 服务,考试时,会发现服务没有启动
systemctl status kubelet
启动服务,并设置为开机启动
systemctl start kubelet
systemctl enable kubelet
检查
systemctl status kubelet
退出 root,退回到 candidate@node02
exit
退出 node02,退回到 candidate@node01
exit
17、节点维护
设置配置环境:
[candidate@node-1] $ kubectl config use-context ek8s
Task
将名为 node02 的 node 设置为不可用,并重新调度该 node 上所有运行的 pods。考点:cordon 和 drain 命令的使用
kubectl -h
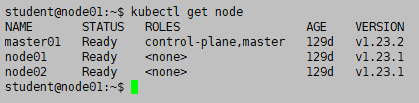
执行命令,模拟节点异常
kubectl get node
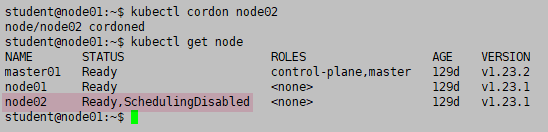
kubectl cordon node02
kubectl get node
kubectl drain node02 --ignore-daemonsets
注意,还有一个参数--delete-emptydir-data --force,这个考试时不用加,就可以正常 drain node02 的。
但如果执行后,有跟测试环境一样的报错,则需要加上--delete-emptydir-data --force,会强制将 pod 移除。

kubectl drain node02 --ignore-daemonsets --delete-emptydir-data --force
检查
kubectl get node
kubectl get pod -A -o wide|grep node02

发布者:LJH,转发请注明出处:https://www.ljh.cool/33628.html