
Kubernetes Operator
Kubernetes Operator 是一种封装、部署和管理 Kubernetes 应用的方法。我们使用 Kubernetes API(应用编程接口)和 kubectl 工具在 Kubernetes 上部署并管理 Kubernetes 应用
部署参考文档:
https://zhaohongye.com/k8s-kube-prometheus/
相关地址信息
Prometheus github 地址:https://github.com/coreos/kube-prometheus
组件说明
1.MetricServer:是 kubernetes 集群资源使用情况的聚合器,收集数据给 kubernetes 集群内使用,如kubectl,hpa,scheduler等
2.PrometheusOperator:是一个系统监测和警报工具箱,用来存储监控数据
3.NodeExporter:用于各 node 的关键度量指标状态数据
4.KubeStateMetrics:收集kubernetes 集群内资源对象数据,制定告警规则
5.Prometheus:采用pull方式收集 apiserver,scheduler,controller-manager,kubelet 组件数据,通过http 协议传输
6、Grafana:是可视化数据统计和监控平台
git clone https://github.com/coreos/kube-prometheus.git
建议使用本文章适配版本:自行匹配合适版本

git clone -b release-0.5 --single-branch https://github.com/coreos/kube-prometheus.git
cd kube-prometheus/manifests
(release-0.5版本sed修改镜像操作可省略,其他版本需注意)
sed -i "s#quay.io/prometheus/#registry.cn-hangzhou.aliyuncs.com/chenby/#g" *.yaml
sed -i "s#quay.io/brancz/#registry.cn-hangzhou.aliyuncs.com/chenby/#g" *.yaml
sed -i "s#k8s.gcr.io/prometheus-adapter/#registry.cn-hangzhou.aliyuncs.com/chenby/#g" *.yaml
sed -i "s#quay.io/prometheus-operator/#registry.cn-hangzhou.aliyuncs.com/chenby/#g" *.yaml
sed -i "s#k8s.gcr.io/kube-state-metrics/#registry.cn-hangzhou.aliyuncs.com/chenby/#g" *.yaml修改nodePort模式访问(生产环境建议使用ingress)下面使用NodePort方法不建议使用
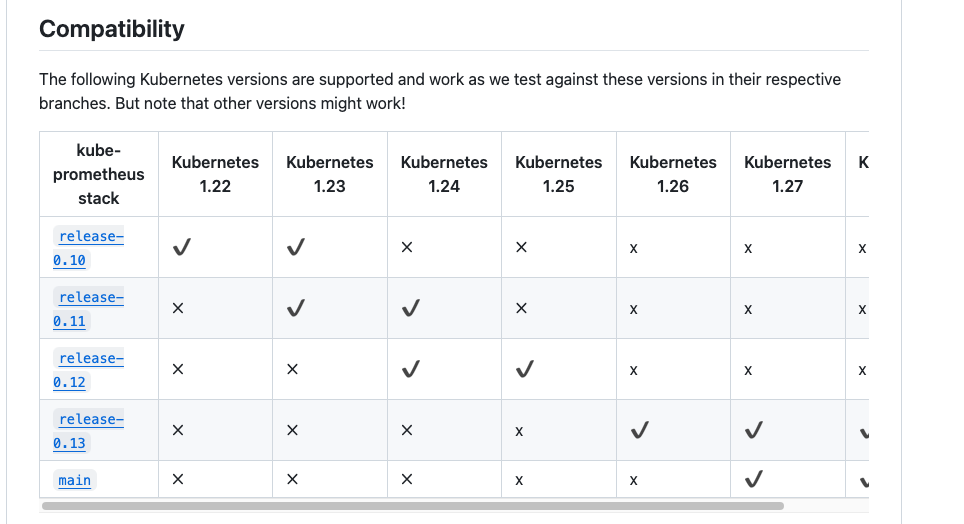
vim grafana-service.yaml
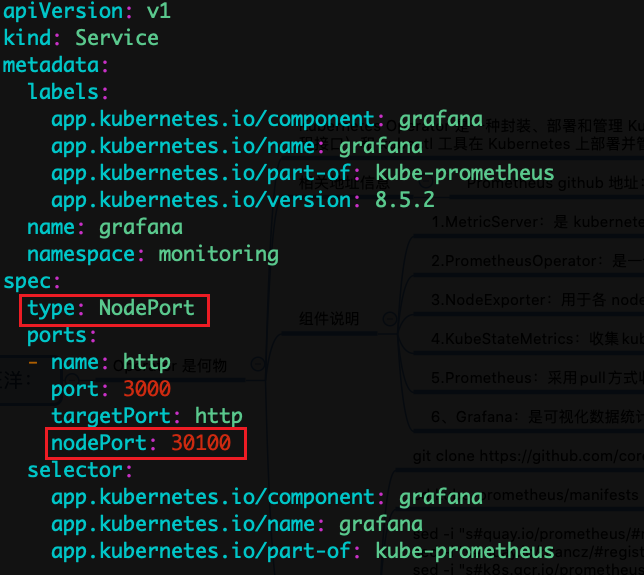
vim prometheus-service.yaml
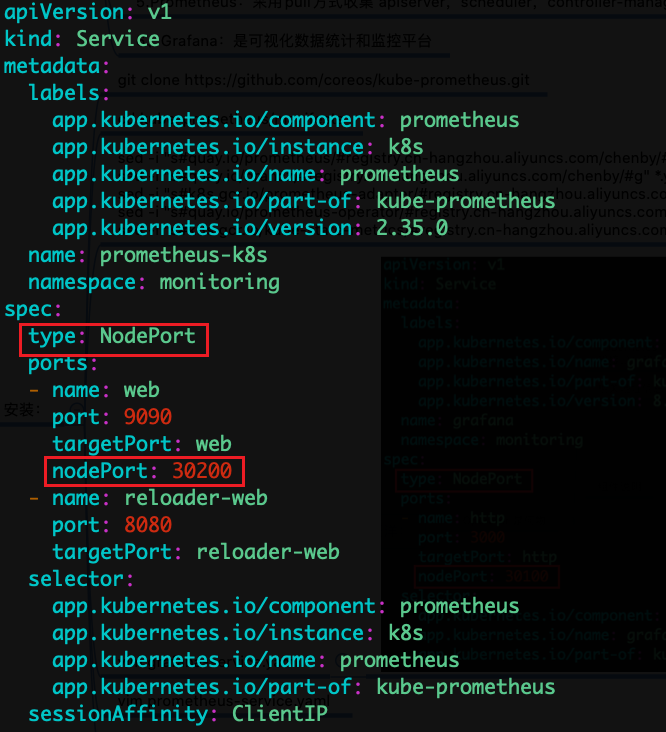
vim alertmanager-service.yaml
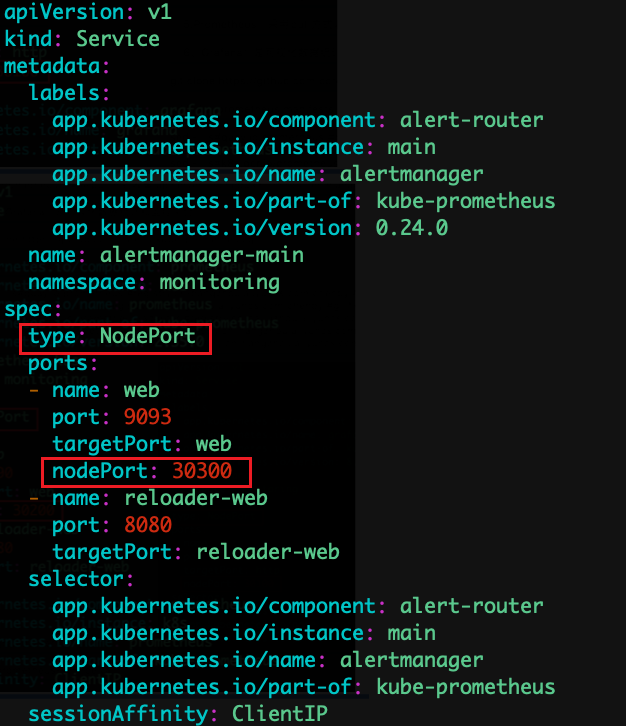
推荐使用ingress方法使用域名部署方式(v1.19+-v1.22+二进制版本,使用了networking.k8s.io/v1beta1版本部署)
vim ingress.yml
# v1beta1版本格式(v1.19+-v1.22):
apiVersion: networking.k8s.io/v1beta1
kind: Ingress
metadata:
name: prom-ingresses
namespace: monitoring
annotations:
kubernetes.io/ingress.class: "nginx"
spec:
rules:
- host: alert.test.com
http:
paths:
- backend:
serviceName: alertmanager-main
servicePort: 9093
path: /
- host: grafana.test.com
http:
paths:
- backend:
serviceName: grafana
servicePort: 3000
path: /
- host: prom.test.com
http:
paths:
- backend:
serviceName: prometheus-k8s
servicePort: 9090
path: /
# v1版本格式(v1.23+):
apiVersion: networking.k8s.io/v1
kind: Ingress
metadata:
name: prom-ingresses
namespace: monitoring
annotations:
kubernetes.io/ingress.class: "nginx"
spec:
rules:
- host: alert.test.com
http:
paths:
- pathType: Prefix
backend:
service:
name: alertmanager-main
port:
number: 9093
path: /
- host: grafana.test.com
http:
paths:
- pathType: Prefix
backend:
service:
name: grafana
port:
number: 3000
path: /
- host: prom.test.com
http:
paths:
- pathType: Prefix
backend:
service:
name: prometheus-k8s
port:
number: 9090
path: /之前ingress使用的是nodeSelector方式选择node01指定部署了ingress,如果是虚拟机修改本地/etc/hosts解析文件
根据ingress-nginx的controller所在的pod接入外部域名解析(之前helm方式安装单独指定在k8s-node01 192.168.1.13节点了)

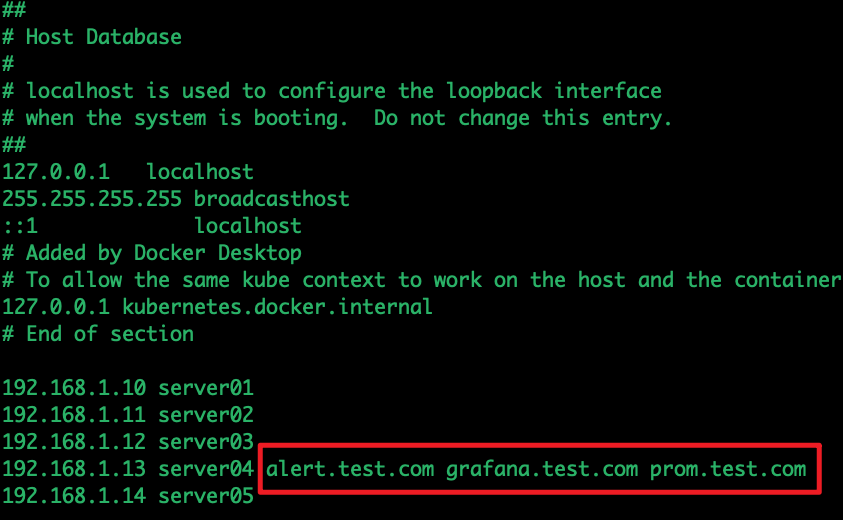
之后通过IP+端口方式修改为使用域名方式访问即可
manifests目录下进行部署
kubectl create -f setup
kubectl create -f .
等待几分钟后
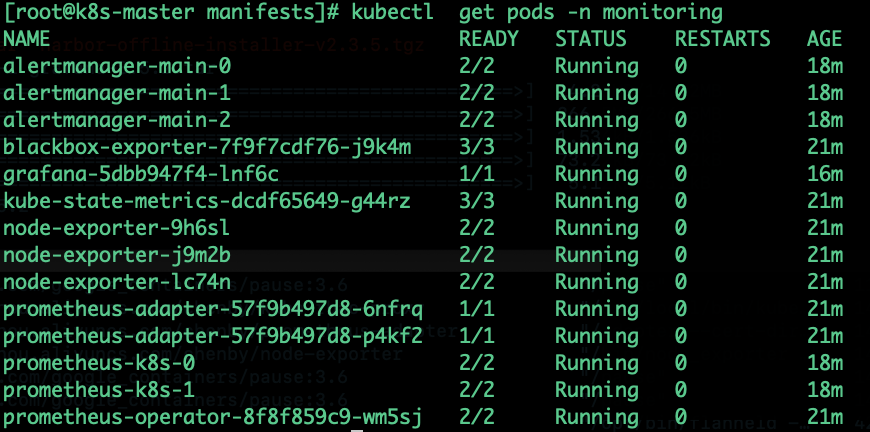
kubectl get pods -n monitoring
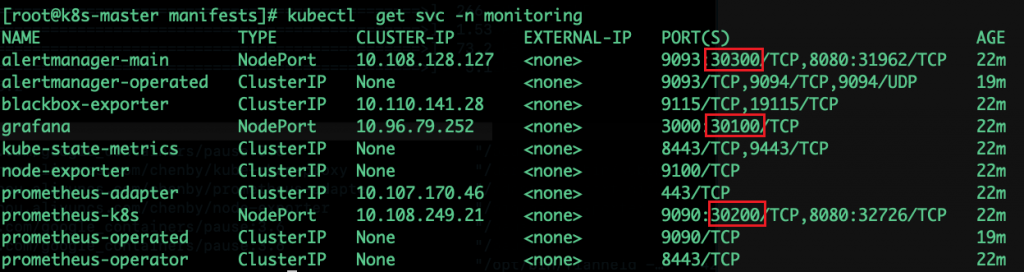
kubectl get svc -n monitoring(NodePort形式,配置了ingress直接域名访问即可)
grafana配置
用户名/密码:admin/admin
导入图表:
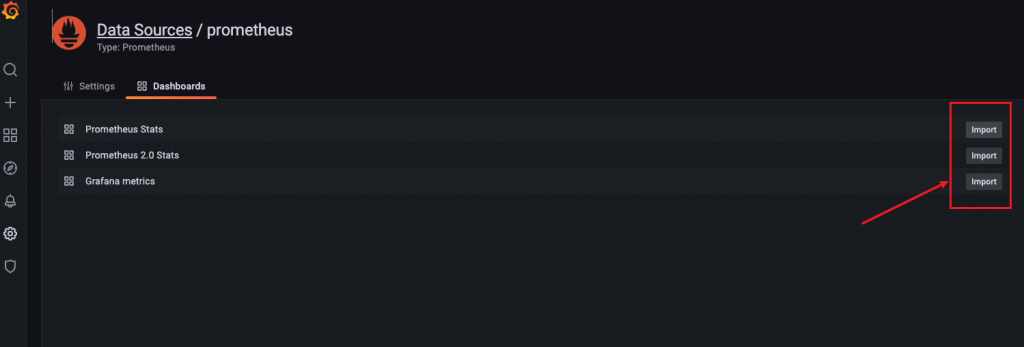
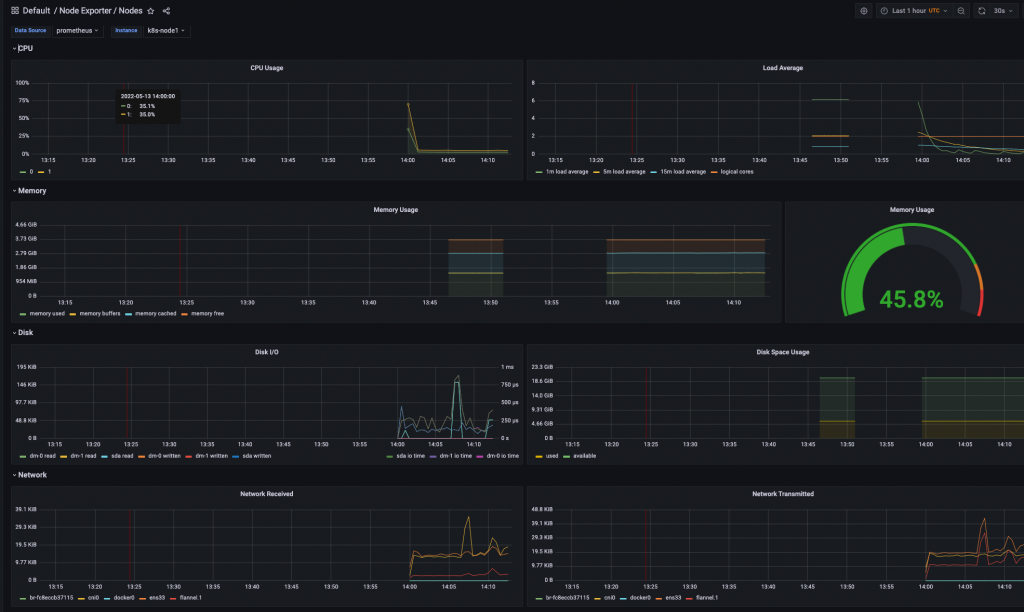
可以查看到cpu使用量和cpu负载,内存使用率,磁盘使用量,磁盘IO,网络IO
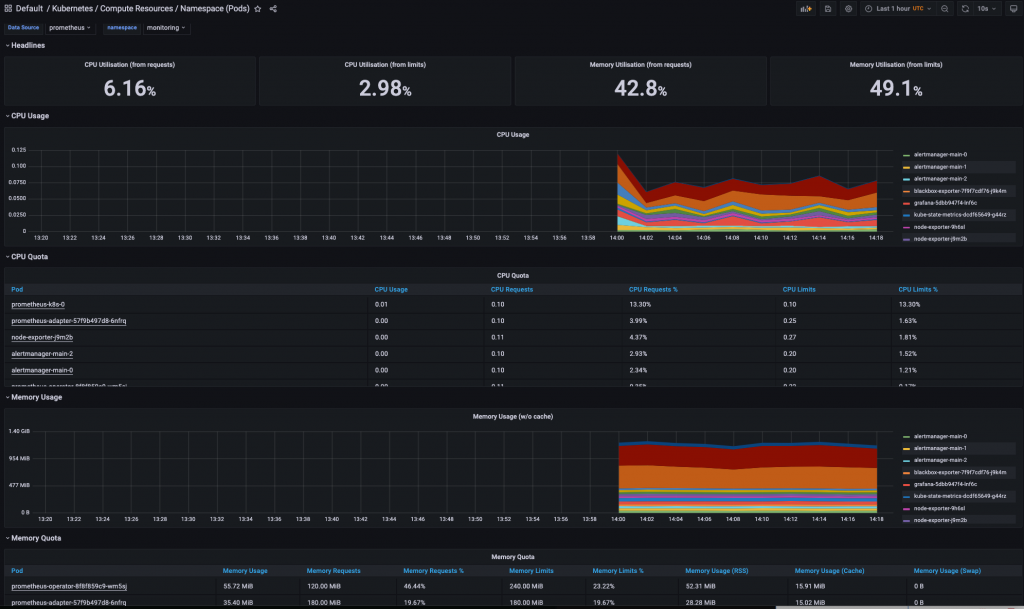
可以监控pod中的cpu使用率和内存,网络磁盘IO等
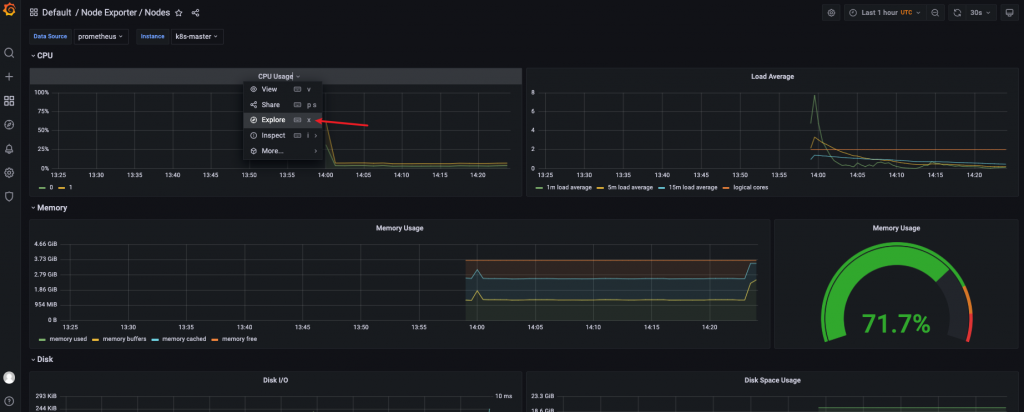
通过PQL语句将普罗米修斯的数据导入grafana
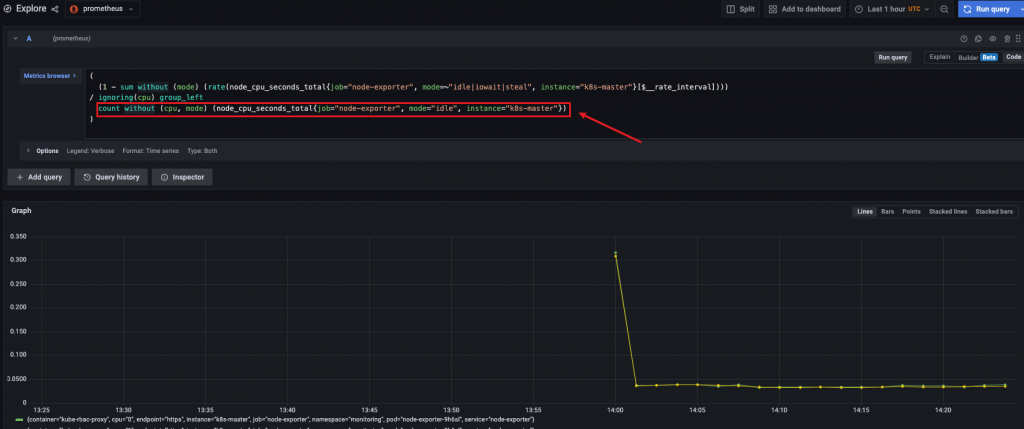
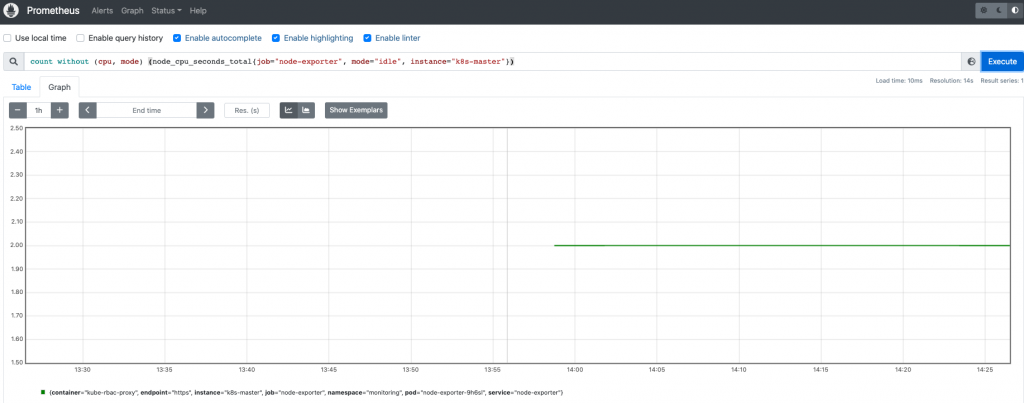
prometheus
图表只能查看一个数值:
Alertmanager
内部监测命令也可以使用了:
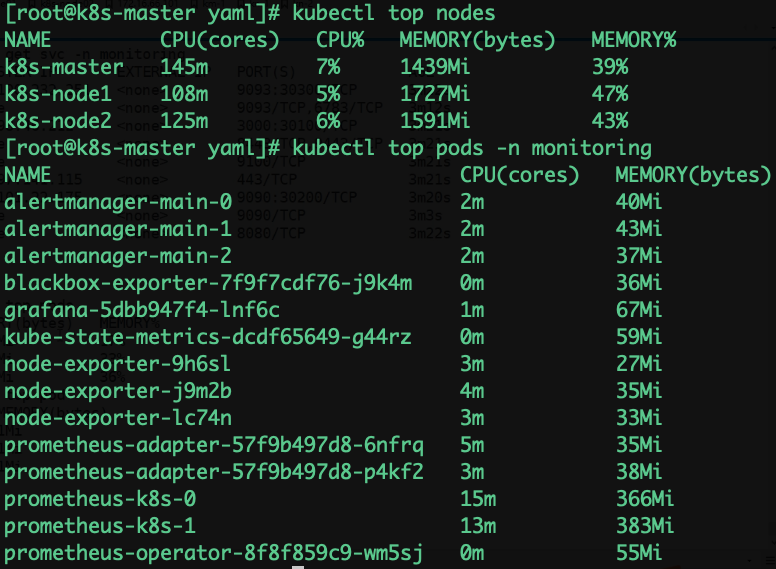
HPA监控测试:
Horizontal Pod Autoscaling
HPA 可以根据 CPU 利用率自动伸缩 RC、Deployment、RS 中的 Pod 数量
所有节点导入压测工具
docker load -i hpa.tar

创建服务:
php-apache.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
labels:
app: php-apache
name: php-apache
spec:
replicas: 1
selector:
matchLabels:
app: php-apache
template:
metadata:
creationTimestamp: null
labels:
app: php-apache
spec:
containers:
- image: wangyanglinux/hpa:latest
imagePullPolicy: IfNotPresent
name: hpa
resources:
requests:
cpu: 200m
---
apiVersion: v1
kind: Service
metadata:
labels:
app: php-apache
name: php-apache-svc
spec:
ports:
- port: 80
protocol: TCP
targetPort: 80
selector:
app: php-apache服务访问测试:

创建 HPA 控制器:
kubectl autoscale deployment php-apache --cpu-percent=50 --min=2 --max=10
设置deployment pgp-apache当pod占用cpu达到百分之50以上时,pod进行扩容,最小pod数量为2个,最大为10个

压力测试:
查看kube-dns所在IP
kubectl get svc -n kube-system

跑一个pod进行访问压测,同时开两个终端进行访问
kubectl run -i --tty work --image=busybox /bin/sh
while true; do wget -q -O- http://php-apache-svc.default.svc.cluster.local; done

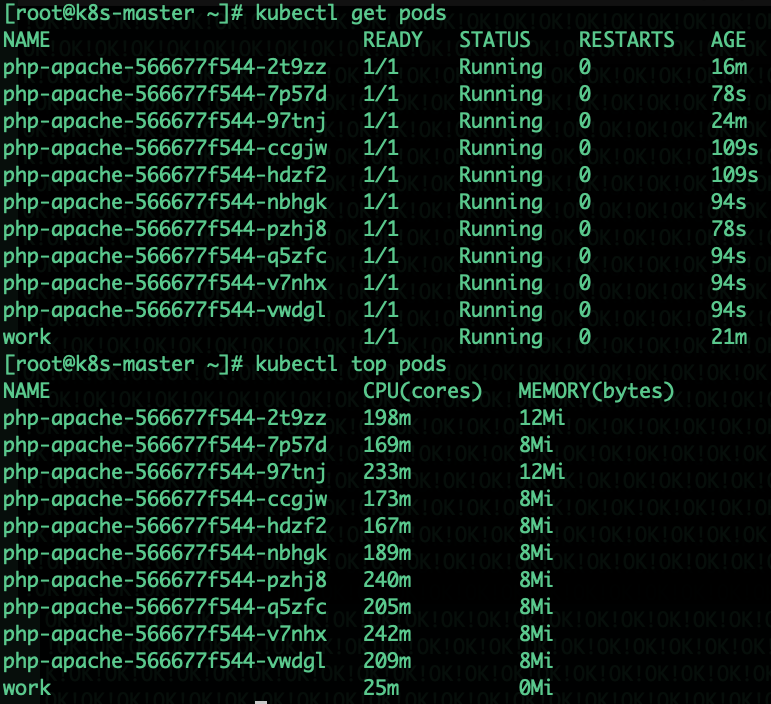
kubectl get hpa

停止时压测访问
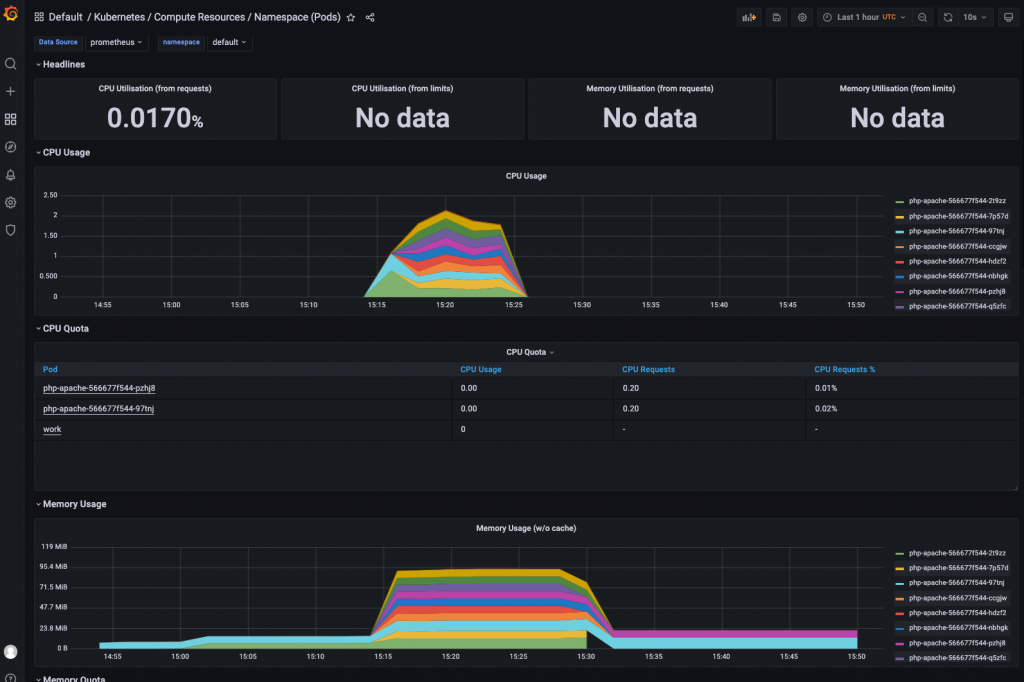
查看监控
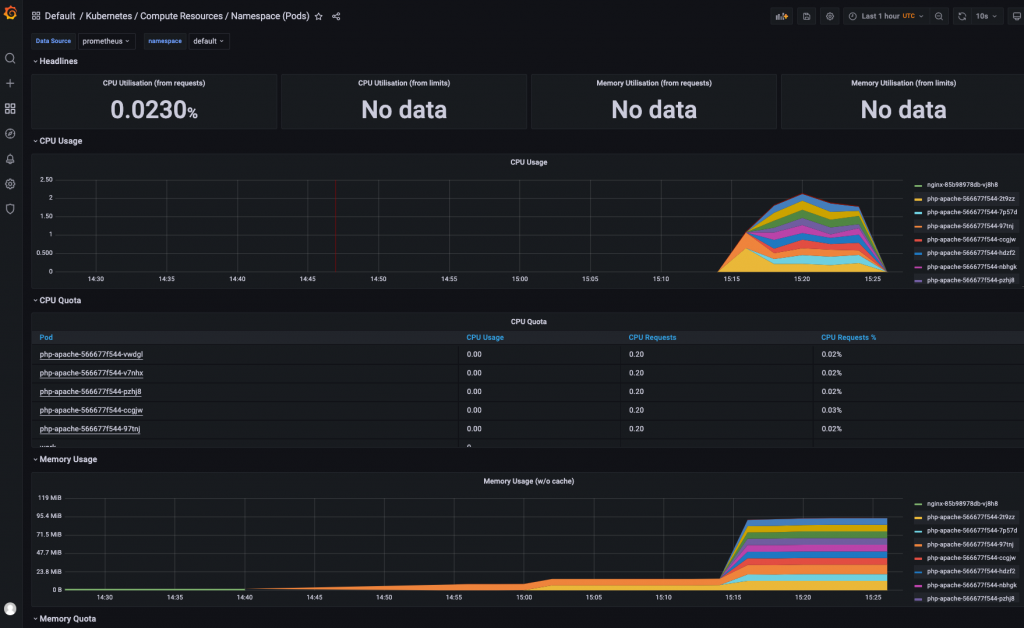
pod扩容很快,但是回收很慢,防止流量集中打死pod,所以内存很慢才会降下来
等待十分钟后:
发布者:LJH,转发请注明出处:https://www.ljh.cool/37775.html